
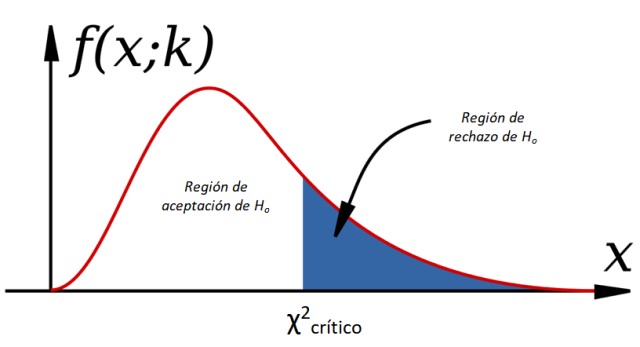
Imagen tomada de Lifeder.
Compártelo:
- Share on X (Opens in new window) X
- Share on Facebook (Opens in new window) Facebook
- Print (Opens in new window) Print
- Share on LinkedIn (Opens in new window) LinkedIn
- Share on Reddit (Opens in new window) Reddit
- Share on Tumblr (Opens in new window) Tumblr
- Share on Pinterest (Opens in new window) Pinterest
- Share on Telegram (Opens in new window) Telegram
- Share on WhatsApp (Opens in new window) WhatsApp
- Email a link to a friend (Opens in new window) Email
- Share on Threads (Opens in new window) Threads
- Share on Mastodon (Opens in new window) Mastodon
- Share on Nextdoor (Opens in new window) Nextdoor
- Share on X (Opens in new window) X
- Share on Bluesky (Opens in new window) Bluesky