Se sabe que la sintaxis qnorm(p, mean = 0, sd = 1, lower.tail = TRUE or FALSE, log.p = TRUE or FALSE) es para calcular una probabilidad p de una distribución normal estándar con media m=0 y error estándar de s=1. Sabemos también que la función cuantil está asociada con una distribución de probabilidad de una variable aleatoria y que especifica el valor de la variable aleatoria de manera que la probabilidad de que la variable sea menor o igual a ese valor es igual a la probabilidad dada (que en la sintaxis de R se designa como p); cabe mencionar que también se llama función de punto porcentual o función de distribución acumulativa inversa. Según la documentación de R sobre la sintaxis, su componente “lower.tail = TRUE or FALSE” menciona que “logical; if TRUE (default), probabilities are P[X ≤ x], otherwise, P[X > x]”, lo que implicaría, dado todo lo anterior, que esa sintaxis (utilizada con la configuración inicial – lower.tail = TRUE-) calcula el valor umbral x por debajo del cual se encuentran las observaciones sobre el fenómeno de estudio en una proporción P de las ocasiones (nótese aquí una definición frecuentista de probabilidad), incluyendo el umbral en cuestión.
Así, la función cuantil es la función inversa de la función de distribución acumulada y es de importancia fundamental en las Probabilidades y la Estadística porque en ocasiones no es posible definir la función de distribución acumulada, entonces se trabaja con su inversa. En términos más intuitivos, la función de distribución acumulada permite conocer la probabilidad de que la variable aleatoria X tome un valor menor o igual a un valor especificado , mientras que la función cuantil muestra sintéticamente (mediante el análisis del valor umbral que arroja) la cantidad de valores que se encuentran por debajo del umbral (incluyendo al umbral, es decir, P[X ≤ x]) y cuáles son estos valores; evidentemente la relación anterior se puede invertir y hablar de los que se encuentren por encima del valor umbral (sin incluir al umbral, es decir, P[X > x]), todo depende de las necesidades del investigador y del planteamiento teórico del problema.
Finalmente, si se utiliza la sintaxis de R “qK(c, …)” (siendo K cualquier función de distribución) se están calculando los intervalos de confianza con la función cuantil y no con la función de distribución acumulada, para garantizarte que siempre sea posible realizar tal cálculo, en caso la función de distribución acumulada no exista, trabajando con su función inversa.
Por ejemplo, la función percentil sirve para responder a preguntas como “¿Cuál es la nota en la cual se acumula el 78.5% de los estudiantes?”. Por supuesto, la pregunta no habla de en qué sentido se acumula esa proporción de los estudiantes ni especifica si se incluye el punto alrededor del cual se acumula tal proporción de estudiantes. Para el caso en que la pregunta “cuál es la nota debajo de la cual está el x porcentaje de los alumnos” y se respondería en sus dos sentidos de la siguiente manera (si se define x = rnorm):
qnorm(0.7850824,72,15.2) = 84, que será inicialmente P[X ≤ x]. Aquí, el 78.5% de los estudiantes tienen una nota menor o igual a 84.
qnorm(0.7850824,72,15.2,lower.tail = F) = 60, que la configuración personalizada para obtener el complemento de probabilidad P[X > x]. Aquí, el 78.5% de los estudiantes tienen una nota mayor que 60.
Figura 1
Además, puede verse que el valor umbral para el cual se cumple que P [X ≤ x] es igual al valor umbral (1-P) [X > x] o, lo que es lo mismo, el valor umbral x por debajo del cual se encuentran las observaciones sobre el fenómeno de estudio en una proporción P de las ocasiones (incluyendo el umbral en cuestión) es igual al valor umbral por encima del cual se encuentran las observaciones sobre el fenómeno de estudio en una proporción complementaria (1-P) de las ocasiones (sin incluir el umbral en cuestión).
Aldrich, J. H., & Nelson, F. D. (1984). Linear Probability, Logit, and Probit Models. Beverly Hills: Sage University Papers Series. Quantitative Applications in the Social Sciences.
Allen, M. (2017). The SAGE Encyclopedia of COMMUNICATION RESEARCH METHODS. London: SAGE Publications, Inc.
AMERICAN PSYCHOLOGICAL ASSOCIATION. (2021, Julio 15). level. Retrieved from APA Dictionary of Pyschology: https://dictionary.apa.org/level
AMERICAN PYSCHOLOGICAL ASSOCIATION. (2021, Julio 15). factor. Retrieved from APA Dictionary of Pyschology: https://dictionary.apa.org/factor
Birnbaum, Z. W., & Sirken, M. G. (1950, Marzo). Bias Due to Non-Availability in Sampling Surveys. Journal of the American Statistical Association, 45(249), 98-111.
Hastie, T., Tibshirani, R., & Friedman, J. (2017). The Elements of Statistical Learning. Data Mining, Inference, and Prediction (Segunda ed.). New York: Springer.
Instituto Nacional de Estadística y Censos de la República Argentina. (2019). Encuesta de Actividades de Niños, Niñas y Adolescentes 2016-2017. Factores de expansión, estimación y cálculo de los errores por muestra para el dominio rural. Buenos Aires: Ministerio de Hacienda. Retrieved from https://www.indec.gob.ar/ftp/cuadros/menusuperior/eanna/anexo_bases_eanna_rural.pdf
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning with Applications in R. New York: Springer.
Kolmogórov, A. N., & Fomin, S. V. (1978). Elementos de la Teoría de Funciones y del Análisis Funcional (Tercera ed.). (q. e.-m. Traducido del ruso por Carlos Vega, Trans.) Moscú: MIR.
Liao, T. F. (1994). INTERPRETING PROBABILITY MODELS. Logit, Probit, and Other Generalized Linear Models. Iowa: Sage University Papers Series. Quantitative Applications in the Social Sciences.
Lipschutz, S. (1992). Álgebra Lineal. Madrid: McGraw-Hill.
Lohr, S. L. (2019). Sampling: Design and Analysis (Segunda ed.). Boca Raton: CRC Press.
Lohr, S. L. (2019). Sampling: Design and Analysis (Segunda ed.). Boca Raton: CRC Press.
McCullagah, P., & Nelder, J. A. (1989). Generalized Linear Models (Segunda ed.). London: Chapman and Hall.
McCullagh, P., & Nelder, J. A. (1989). Generalized Linear Models (Segunda ed.). London: Chapman and Hall.
Nelder, J. A., & Wedderburn, R. W. (1972). Generalized Linear Models. Journal of the Royal Statistical Society, 135(3), 370-384.
Ritchey, F. (2002). ESTADÍSTICA PARA LAS CIENCIAS SOCIALES. El potencial de la imaginación estadística. México, D.F.: McGRAW-HILL/INTERAMERICANA EDITORES, S.A. DE C.V.
Hastie, T., Tibshirani, R., & Friedman, J. (2017). The Elements of Statistical Learning. Data Mining, Inference, and Prediction (Segunda ed.). New York: Springer.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning with Applications in R. New York: Springer.
Como señala (Cochran, 1991, pág. 195), “Uno de los rasgos de la estadística teórica es la creación de una vasta teoría que discute los métodos de obtención de buenas estimaciones a partir de los datos. En el desarrollo de la teoría, específicamente para encuestas de muestreo, se han utilizado poco estos conocimientos, por dos causas principales. Primero, en las encuestas que contienen un gran número de atributos, es una gran ventaja, aunque se disponga de máquinas computadoras, el poder utilizar procedimientos de estimación que requieran poco más que simples sumas, en tanto que los métodos superiores de estimación de la estadística teórica, como lo son la máxima verosimilitud, podrían necesitar una serie de aproximaciones sucesivas antes de encontrar una estimación (…) La mayoría de los métodos de investigación de la estadística teórica suponen que se conoce la forma funcional de la distribución de frecuencia que sigue a los datos de la muestra, y el método de estimación de estimación está cuidadosamente engranado de acuerdo a este tipo de distribución. En la teoría de encuestas por muestreo se ha preferido hacer, cuando más, algunos supuestos respecto a esta distribución de frecuencia. Esta actitud resulta razonable para tratar con encuestas en las que el tipo de distribución puede variar de un atributo a otro, y cuando no deseamos detenernos a examinarlas todas, antes de decidir cómo hacer cada estimación. En consecuencia, actualmente, las técnicas de estimación para el trabajo de encuestas por muestreo son de alcances restringidos. Ahora consideraremos dos técnicas, el método de razón (…) y el método de regresión línea (…)” Así, “Al igual que la estimación de razón, la regresión lineal se ha diseñado para incrementar la precisión en el uso de una variable auxiliar correlacionada con .” (Cochran, 1991, pág. 239).
Continuing the theme of revising theory in the convergence of random processes that I shouldn’t have forgotten so rapidly, today we consider the Skorohod Representation Theorem. Recall from the standard discussion of the different modes of convergence of random variables that almost sure convergence is among the strongest since it implies convergence in probability and thus convergence […]
En teoría de grafos, se define como grafo al par G=(V,E), en donde V es el conjunto de aquellos elementos que son vértices y E es el conjunto de pares de vértices cuyos elementos se denominan aristas. A continuación, se presenta un ejemplo simple de grafo con tres vértices (círculos azules) y tres aristas (líneas rectas negras), específicamente un triángulo rectángulo visto como grafo.
Fuente: (Wikimedia, 2021).
Un isomorfismo entre dos grafos G1 y G2 es una relación funcional biyectiva (i.e., que establece una relación uno-a-uno entre los elementos de dos conjuntos) entre los vértices de G1 y G2, que adopta la forma f: V(G1)–>V(G2), en la que cualesquiera dos vértices u, v ∈ G1 son adyacentes (relación entre dos vértices en la que ambos son extremos de la misma arista) si y solo si sus reflejos o imágenes matemáticas f(u) y f(v) son adyacentes en G2. La característica fundamental de un isomorfismo de grafo es que es una relación funcional biyectiva que preserva las aristas que caracterizan al grafo. Que esta transformación matemática preserve las aristas implica que las distancias entre los vértices, analizados estos “de dos en dos”, no cambian.
Son precisamente estas distancias a las que se les conoce como distancias relativas dentro de la estructura matemática, en contraste con las distancias absolutas que son medidas como distancias de los vértices considerados individualmente. Un ejemplo de ello se muestra a continuación.
Fuente: (Jose, 2020).
Los dos grafos anteriores son isomórficos entre sí, i.e., poseen la misma estructura interna o estructura topológica. A continuación, se presenta un ejemplo numérico de ello, en consonancia con lo anteriormente expuesto.
Fuente: (Wikipedia, 2021).
Las diferencias concretas entre las distancias topológicas y las distancias métricas pueden observarse con nitidez en lo relativo al desarrollo teórico y aplicado de modelos que explican el comportamiento colectivo de animales, como lo son bandadas de aves, bancos de peces, etc. Esto es un equivalente concreto a nivel biológico del concepto matemático abstracto de la manera en que se agrupan en subconjuntos los elementos de un determinado conjunto).
Como señala el Instituto de Sistemas Complejos de Italia (Instituto dei Sistemi Complessi, 2021), todos los modelos existentes sobre el comportamiento colectivo de los animales asumen que la interacción entre los diferentes individuos depende de la distancia métrica, al igual que en la Física. Esto implica, por ejemplo, que dos pájaros separados por 5 metros interactúan con más fuerza que dos pájaros separados por 10 metros. Como se señala en la fuente citada, los modelos desarrollados por biólogos se basan en un esquema de “zonas de comportamiento”, donde cada zona está asociada a uno de los tres componentes básicos de todos los modelos: repulsión de corto alcance, alineación, atracción de largo alcance. Los modelos desarrollados por físicos, por otro lado, usaban principalmente una función de fuerza única. Sin embargo, los dos enfoques son sustancialmente equivalentes y lo que importa es que ambos se basan en un paradigma métrico.
El punto crucial es que, dentro del paradigma métrico, el número de vecinos con los que interactúa cada individuo no es una constante, sino que depende de la densidad. Por ejemplo, supóngase que cada ave interactúa con todos los vecinos dentro de un rango de 5 metros. El número de vecinos dentro de los 5 metros será grande en una bandada densa y pequeña en una bandada escasa. Entonces, dentro del paradigma métrico, el número de vecinos que interactúan no es una constante, sino que depende de la densidad. Lo que es constante es el rango métrico de la interacción (5 metros en el ejemplo anterior).
El paradigma métrico parece muy razonable a primera vista. Los animales son buenos para evaluar distancias, por lo que tiene sentido asumir que la fuerza de sus lazos mutuos depende de la distancia. Además, los modelos métricos demostraron ser capaces de reproducir cualitativamente el comportamiento de las bandadas. Por lo tanto, no había razón para cuestionar el paradigma métrico, en ausencia de datos empíricos. Y dado que hasta el momento no se disponía de datos empíricos, todos los modelos utilizaron una interacción métrica.
Los primeros datos empíricos sobre grandes bandadas de estorninos fueron obtenidos por el nodo INFM-CNR dentro del proyecto STARFLAG (esto hace referencia a un proyecto sobre comportamiento colectivo de animales coordinado por el INFM-CNR, organismo que pertenece a la institución citada). Al reconstruir las posiciones en 3D de aves individuales, fue posible mapear la distribución promedio de los vecinos más cercanos (Figura 2), lo que proporciona la caracterización más clara de la estructura de las aves dentro de una bandada.
Así, “Dado un ave de referencia, medimos la orientación angular desu vecino más cercano con respecto a la dirección de movimiento de la bandada, es decir, el rumbo y la elevación del vecino. Repetimos esto tomando a todos los individuos dentro de una bandada como ave de referencia, y de esta manera mapeamos la posición espacial promedio de los vecinos más cercanos.” (Instituto dei Sistemi Complessi, 2021). El fragmento de la cita bibliográfica anterior en negrita y cursiva es en esencia la lógica de tomar a los individuos “de dos en dos”, añadiendo a ello elementos que juegan un rol relevante en este contexto específico de aplicación de las nociones topológicas, como lo son el rumbo y la elevación; sin embargo, hay que decir que a nivel de teoría de grafos, también existen grafos cuyas aristas poseen dirección, los cuales por motivo de simplicidad no fueron expuestos, aunque no por ello deja de ser necesaria esta especificación.
Así, es posible pensar en este mapa como un mapa de la esfera alrededor de cada ave voladora. El centro del mapa es la dirección de avance, los polos son las direcciones hacia arriba y hacia abajo. El color en un punto dado del mapa indica la probabilidad de que el vecino más cercano del pájaro esté en esa dirección particular. Este mapa muestra una sorprendente falta de vecinos más cercanos a lo largo de la dirección del movimiento. Por tanto, la estructura de los individuos es fuertemente anisotrópica[1]. Esta anisotropía probablemente esté relacionada con el aparato visual de las aves. Sin embargo, el punto crucial es que esta anisotropía es el efecto de la interacción entre individuos, cualquiera que sea esta interacción.
Fuente: (Instituto dei Sistemi Complessi, 2021).
Para respaldar esta afirmación, calculamos la distribución de vecinos muy alejados del ave de referencia, por ejemplo, para el décimo vecino más cercano (mapa inferior en la figura).
Fuente: (Instituto dei Sistemi Complessi, 2021).
Esta distribución es uniforme, para garantizar una agregación de puntos completamente isótropa[2] y sin interacción, puesto que ello es una indicación empírica directa de afirmar que la interacción decae con la distancia: cuanto más separadas están dos aves, menor es su grado de correlación. Este resultado también demuestra que podemos usar la anisotropía para obtener información sobre la interacción. De hecho, se puede calcular el mapa de distribución angular[3] de los vecinos incluso para el segundo, tercer, cuarto vecino más cercano, etc., y observar cómo la estructura anisotrópica presente para los vecinos más cercanos se desvanece progresivamente a medida que aumenta el orden del vecino.
La desintegración de esta estructura anisotrópica con la distancia se puede cuantificar de forma precisa calculando el factor de anisotropía gamma[4]. Esta cantidad decae a su valor isotrópico (no interactivo) 1/3 a medida que aumenta el orden n-ésimo del vecino, de manera similar a una función de correlación estándar.
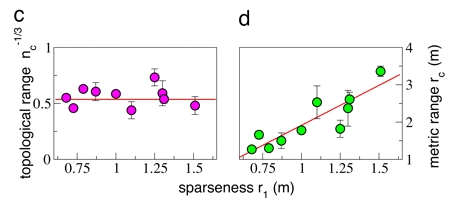
“Sin embargo, el punto crucial es que n es una distancia topológica, es decir, es una distancia medida en unidades de aves, en lugar de metros. A partir del factor de anisotropía podemos calcular el rango topológico, definido como el punto donde el factor de anisotropía se vuelve igual a su valor de no interacción. Este rango topológico es simplemente el número promedio de vecinos con los que interactúa cada ave. Claramente, dada la densidad de la bandada, también podemos definir una distancia métrica estándar y, por lo tanto, un rango métrico de la interacción. El rango métrico de interacción no es más que la distancia máxima de las aves dentro del rango topológico.” Fuente: (Instituto dei Sistemi Complessi, 2021).
Así, el punto importante es que la densidad de las bandadas varía mucho de una bandada a otra, y esto implica que el rango topológico y métrico no puede ser constante cuando la densidad varía. Para dilucidar este punto crucial, considérese dos bandadas con diferentes densidades. Si la interacción depende de la distancia métrica, entonces el rango en metros es el mismo en las dos bandadas, mientras que el número de individuos dentro de este rango es grande en la bandada más densa y pequeño en la más dispersa.
Fuente: (Instituto dei Sistemi Complessi, 2021).
Por el contrario, si la interacción depende de la distancia topológica, el rango en unidades de aves es constante en las dos bandadas, mientras que la distancia de estos n vecinos más cercanos es pequeña en la bandada más densa y grande en la más escasa.
La diferencia entre la hipótesis topológica y métrica es clara: en el escenario topológico, el número de individuos que interactúan es fijo. Por el contrario, en el escenario métrico, dicho número varía con la densidad; por ejemplo, dentro del mismo rango métrico puede haber 10 aves en una bandada muy densa y solo 1 ave en una muy escasa. Por lo tanto, los rangos topológicos y métricos no son caracterizaciones intercambiables de la interacción.
Por lo tanto, para comprender si lo que importa es la métrica o la distancia topológica, debemos medir cómo el rango métrico y topológico depende de la densidad de las bandadas. En promedio, para este caso de aplicación concreto se sostiene en la fuente citada que el rango topológico es igual a 6.5 aves. “Este resultado contrasta con la mayoría de los modelos y teorías de comportamiento animal colectivo actualmente en el mercado, que asumen un rango métrico de interacción.” Fuente: (Instituto dei Sistemi Complessi, 2021).
¿Por qué una interacción topológica y no métrica? El comportamiento colectivo de los animales se escenifica en un entorno natural convulso. Por tanto, el mecanismo de interacción formado por la evolución debe mantener la cohesión frente a fuertes perturbaciones, de las cuales la depredación es la más relevante. Creemos que la interacción topológica es el único mecanismo que otorga una cohesión tan robusta y, por lo tanto, una mayor aptitud biológica. Una interacción métrica es inadecuada para hacer frente a este problema: siempre que la distancia interindividual se hiciera mayor que el rango métrico, la interacción desaparecería, la cohesión se perdería y los rezagados se “evaporarían” de la agregación. Una interacción topológica, por el contrario, es muy robusta, ya que su fuerza es la misma a diferentes densidades. Al interactuar dentro de un número fijo de individuos, en lugar de metros, la agregación puede ser densa o escasa, cambiar de forma, fluctuar e incluso dividirse, pero manteniendo el mismo grado de cohesión. Por lo tanto, la interacción topológica es funcional para mantener la cohesión frente a las fuertes perturbaciones a las que está sujeta una bandada, típicamente depredación. Así, las distancias topológicas son aquellas distancias entre los elementos de un conjunto, o entre los componentes integrantes de un sistema dinámico, que se mantienen invariantes ante perturbaciones. Por ello, en línea con lo planteado en (Nabi, 2021) en el terreno de la biología molecular, las distancias topológicas denotan las propiedades características, i.e., la esencia, de los fenómenos naturales Lo que es más íntimo, más característico del comportamiento estudiado.
Finalmente, es necesario mencionar que existe evidencia de que el valor particular del rango topológico que encontramos (6.5) está relacionado con las capacidades cognitivas de las aves y, en particular, con sus habilidades pre numéricas[5].
[1] La anisotropía es la propiedad general de la materia según la cual cualidades como elasticidad, temperatura, conductividad, velocidad de propagación de la luz, etc., varían según la dirección en que son examinadas. Un ente anisótropo puede presentar diferentes características según la dirección.
[2] La isotropía es la característica de algunos fenómenos en el espacio cuyas propiedades no dependen de la dirección en que son examinadas.
[3] La distribución angular de un conjunto de observaciones es la distribución de las direcciones hacia donde los electrones son emitidos dentro de un determinado sistema de coordenadas.
[4] Como se señala en (Oilfield Glossary en Español, 2021), el factor de anisotropía gamma es el parámetro de las ondas S para un medio en el cual las propiedades elásticas exhiben isotropía transversal vertical [implica propiedades elásticas que son las mismas en cualquier dirección perpendicular a un eje de simetría y tiene cinco constantes elásticas independientes, como se señala en (The SEG Wiki, 2021)]. Gamma (γ) es el parámetro de anisotropía de las ondas S y equivale a mitad de la razón de la diferencia entre las velocidades de las ondas SH que se propagan en sentido horizontal y vertical, al cuadrado, dividida por la velocidad de las ondas SH que se propagan verticalmente al cuadrado; una onda SH es una onda de corte polarizada horizontalmente.”
[5] Para el caso de los humanos, las habilidades pre numéricas son aquellas necesarias antes de aprender sobre los números, tales como comparar, clasificar, identificar, reunir, establecer relaciones uno a uno, seriar, etc.
Como se señala en (Aldrich & Nelson, 1984, págs. 30-31), la inferencia estadística comienza por asumir que el modelo que se va a estimar y utilizar para hacer inferencias está correctamente especificado. La presunción, i.e., el supuesto de partida, es que la teoría estadística-matemática correspondiente a tal o cual modelo estadístico es la que justifica el uso del mismo. Sin embargo, a lo planteado por los autores hay que agregar que es aún más importante que las propiedades reales del fenómeno a estudiar (establecidas por el marco científico mediante el cual se estudia) deben corresponderse en una magnitud mínima necesaria y suficiente con las propiedades matemáticas de tal o cual modelo estadístico. Los autores señalan que es bastante fácil demostrar que la especificación incorrecta del modelo tiene implicaciones realmente sustanciales, ya que todas las propiedades estadísticas de las estimaciones pueden destruirse. Para decirlo sin rodeos, la especificación incorrecta del modelo conduce a respuestas incorrectas.
Los autores también elaboran una maravilla gnoseológica en su argumentación, relativa a la justificación del difundido uso del supuesto de linealidad, estableciendo una versión modificada de la navaja de Occam, una que no implica reduccionismo filosófico, como sí lo suele ser la que utilizan, por ejemplo, los bayesianos subjetivos en los modelos parsimoniosos (y fue en ese sentido en el que la criticó también Albert Einstein):
“¿Por qué es tan popular la especificación lineal? Hay dos razones básicas (y relacionadas). En la práctica, los modelos lineales son matemáticamente simples, por lo que los estadísticos han podido aprender mucho sobre ellos, y se han escrito programas de computadora para hacer la estimación. Sobre bases teóricas, la simplicidad conduce a su adopción, justificada por una versión de la navaja de Occam: en ausencia de una guía teórica en sentido contrario, comience asumiendo el caso más simple. Así, la Navaja de Occam, por implicación, diría: Con alguna orientación teórica en sentido contrario, no asuma el caso más simple.” (Aldrich & Nelson, 1984, pág. 31).
La investigación completa se facilita en el siguiente documento:
Arias Ramírez, R. (2020). Pobreza y desigualdad en Costa Rica: una mirada más allá de la distribución de los ingresos. Estudios del Desarrollo Social: Cuba y América Latina, 1-26. Obtenido de http://scielo.sld.cu/pdf/reds/v8n1/2308-0132-reds-8-01-16.pdf
Barría, C. (16 de Mayo de 2019). Cómo Costa Rica se convirtió en uno de los países más innovadores de América Latina (y cuáles son algunos de los inventos más sorprendentes). Obtenido de BBC Mundo: https://www.bbc.com/mundo/noticias-48193736
Baumol, W. (1983). Marx and the Iron Law of Wages. The American Economic Review, 303-308.
Cochran, W. G. (1991). Técnicas de Muestreo. México, D.F.: Compañía Editorial Continental.
Delgado Jiménez, F. (2013). EL EMPLEO INFORMAL EN COSTA RICA: CARACTERÍSTICAS DE LOS OCUPADOS Y SUS PUESTOS DE TRABAJO. Ciencias Económicas, XXXI(2), 35-51.
Hidalgo Víquez, C., Andrade Pérez, L., Rodríguez Gonzáles, S., Dumani Echandi, M., Alvarado Molina, N., Cerdas Nuñez, M., & Quirós Blanco, G. (2020). Análisis de la canasta básica alimentaria de Costa Rica: oportunidades desde la alimentación y nutrición. Población y Salud en Mesoamérica, 1-24. Obtenido de https://revistas.ucr.ac.cr/index.php/psm/article/view/40822/42616
Laplante, P. A. (2001). DICTIONARY OF COMPUTER SCIENCE, ENGENEERING AND TECHNOLOGY. Boca Ratón, Florida, Estados Unidos: CRC Press.
Levins, R. (Diciembre de 1993). A Response to Orzack and Sober: Formal Analysis and the Fluidity of Science. The Quarterly Review of Biology, 68(4), 547-55.
Vargas Solís, L. P. (2016). El Proyecto Histórico Neoliberal en Costa Rica (1984-2015): Devenir histórico y crisis. Revista Rupturas, 147-162. doi:https://doi.org/10.22458/rr.v1i1.1167


























{kind=link}