
You can also find this library at CRAN and download it directly from R and RStudio.
LISTEN TO THIS POST AS A PODCAST:
You have a time series — quarterly GDP, a population count, a sensor reading, the price of something. You suspect a differential equation is governing it, but you don’t know which one. You could guess a form and fit it. Or you could hand the data to an algorithm that searches the space of possible equations and hands you back the law, written in symbols, with a measure of how well it fits and how complex it is.
That second option is what EmpiricalDynamics does. It’s an R package — with a high-performance Julia backend — for discovering differential and stochastic differential equations directly from empirical time series. In this post I’ll walk through what it is, why it exists, and how it works under the hood. For full mathematical detail and the recovery-test suite, the project Wiki is the authoritative reference; this post is the map.
The problem it solves
There’s a field called equation discovery (or “symbolic regression for dynamics”). The idea: instead of assuming dy/dt = α + βy and estimating α, β, you let a genetic algorithm breed candidate expressions — combining variables with +, −, ×, ÷, sin, exp, and so on — and you keep the ones that fit well per unit of complexity. The output is a Pareto front of equations trading accuracy against simplicity, from which you pick the one that represents a real law rather than memorised noise.
EmpiricalDynamics, written by José Mauricio Gómez Julián (v0.1.5, MIT licence), wraps this idea into a complete, rigorous workflow aimed squarely at researchers working with observational data — economists, physicists, epidemiologists, anyone studying dynamical systems they didn’t generate in a lab. The motivation is honest: real-world data is noisy, gappy, and rarely matches a textbook form, so the toolkit has to be robust to all three.
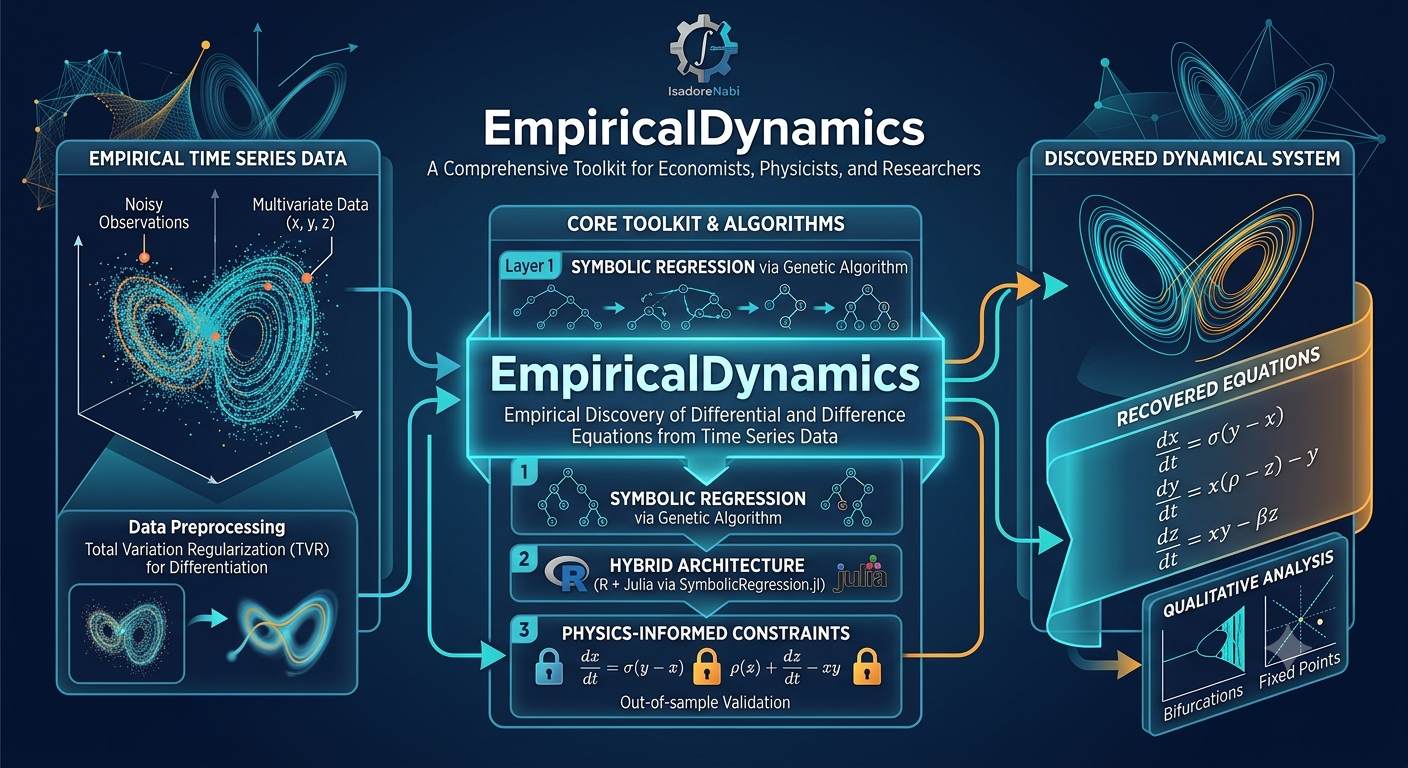
The architecture: a six-step pipeline
The package is structured as a pipeline you can read top to bottom. Each step is one or more exported R functions; the heavy symbolic search optionally hands off to Julia.
- Preprocessing — numerical differentiation. To discover
dZ/dt = f(Z, X), you first needdZ/dt. Differentiating noisy data is famously treacherous, so the package offers several methods. The flagship is Total Variation Regularization (TVR), which solves a convex optimisation balancing reconstruction fidelity against a penalty on jumps in the derivative — promoting piecewise-smooth estimates that tolerate trends and structural breaks. It’s backed by a cascading solver chain (CLARABEL → SCS → OSQP) with internal rescaling so tolerances behave regardless of data scale. Cheaper alternatives — Savitzky-Golay, smoothing splines, finite differences, spectral — are there for cleaner or periodic data, andsuggest_differentiation_method()will recommend one based on your data’s characteristics. - Exploration. Before fitting anything,
explore_dynamics()and a family of phase-portrait, bivariate, and 3-D surface plots let you eyeball the functional structure — doesdZ/dtlook linear inZ, quadratic, oscillatory? - Equation discovery. This is the heart.
symbolic_search()runs the genetic algorithm and returns a Pareto front of candidate equations. You pick one withselect_equation()using AIC, BIC, MDL, or a “knee” heuristic. If you already have a theoretical form (say, a Solow growth model or a logistic equation),fit_specified_equation()is more reliable — it fits your form with Levenberg-Marquardt nonlinear least squares rather than searching blindly. The search has three backends:"r_genetic"(pure R),"r_exhaustive"(small problems), and"julia"(the industrial path). - Residual analysis and SDE construction. Here’s where the package earns its keep for serious work. Once you have a drift function
f̂, the residuals tell you whether there’s leftover stochastic structure. A diagnostic suite runs Ljung-Box (autocorrelation), ARCH-LM (conditional heteroscedasticity), Breusch-Pagan, Jarque-Bera, and a runs test. If the residuals carry structure, you’re not done — you have a stochastic differential equationdZ = f dt + g dW, and now you need to recover the diffusiong. - Validation. Cross-validation — critically, block CV for time series, not random CV, which would destroy temporal dependence. Plus trajectory simulation from the discovered SDE and qualitative-behaviour checks (fixed points, stability, bifurcations) to confirm the equation reproduces the dynamics you actually observe.
- Output. LaTeX equations, coefficient tables, model-comparison tables, and full markdown/HTML reports — publication-ready.
The Julia backend
The R side handles statistics, diagnostics, and orchestration. The Julia side — inst/julia/symbolic_backend.jl, calling SymbolicRegression.jl — handles the expensive evolutionary search, multi-threaded across CPU cores. The Julia code defines a ScientificSearchConfig struct with the usual knobs (population size, iterations, parsimony penalty) and a notable extra: automatic detection of physical constants — π, e, φ, g, c, h, k_B — so that when your data is generated by π·sin(t), the search can return π·sin(t) rather than 3.14159·sin(t). The README reports recovering π and e to 10⁻⁸ precision from noisy data.
The R↔Julia bridge is JuliaCall (with JuliaConnectoR as an alternative). Recent releases (see NEWS.md) fixed real bugs in this glue — a wrong hard-coded UUID that made setup_julia_backend() falsely report the backend as unavailable, a single-predictor TypeError, and a Hall-of-Fame extraction ParseError. The lesson is mundane but important: the engine was fine; the R-side marshalling had drifted out of sync with current SymbolicRegression.jl. It now works end-to-end.
The one idea worth understanding deeply
If you take away a single technical point, take this: the better TVR estimates the drift, the more it destroys the information needed to recover the diffusion.
TVR works by smoothing the derivative — penalising total variation, which suppresses high-frequency components. But in an SDE, the diffusion coefficient g lives in those high-frequency residuals. So as you crank up TVR’s regularisation to get a clean drift, the residual-based diffusion estimate collapses. The Wiki documents this starkly: across solver generations, residual-based diffusion R² fell from 0.591 to 0.005 as the solver improved.
EmpiricalDynamics resolves the tension by estimating diffusion from quadratic variation — (ΔZ)²/Δt ≈ g²(X) — using the raw increments directly, bypassing TVR entirely. With this method the diffusion R² jumps to 0.985, regardless of how aggressively TVR smoothed the drift. That’s the kind of design decision that separates a toy from a toolkit: it acknowledges a fundamental statistical trade-off and routes around it.
Does it actually work?
The Wiki’s recovery test suite is the evidence, and it’s worth reading in full. The epistemological framing is unusually careful: a recovery test generates synthetic data from a known ground-truth equation, hands it to the algorithm “blind,” and checks whether the algorithm rediscovers the law. The Wiki is explicit that this is a necessary but not sufficient condition for genuine causal inference — spurious correlations and unobserved confounders remain possible, and there’s an irreducible simulation-to-reality gap. That honesty matters.
The headline numbers:
- Lorenz attractor (chaotic ODE): average R² ≈ 0.937 across the three Lorenz equations, with the TVR solver reporting 30/30 optimal convergences.
- SDE recovery with drift
10·sin(X) − 2.5·Z³and diffusion0.10 + 0.06·|X|: drift R² = 0.841, diffusion R² = 0.985 (via quadratic variation), under a challenging signal-to-noise ratio of 0.29.
These are strong results, and the Wiki is transparent about where the limits are — diffusion R² above 0.5 is often the practical ceiling when SNR < 1, and the symbolic search is stochastic, so run-to-run variability is real.
Should you use it?
If you’re a researcher with time series data and a hypothesis that a differential equation is at work — economic growth, epidemiological spread, predator-prey dynamics, interest-rate feedback — EmpiricalDynamics gives you a principled, end-to-end pipeline rather than a bag of tricks. It won’t hand you causality on a plate (nothing will), but it will tell you, defensibly, what functional form the data is consistent with, how confident you should be, and what the residuals imply about stochastic structure.
The package is young (v0.1.5, first released late 2025) and the roadmap is ambitious — GPU acceleration, neural-guided search, Bayesian SDEs via Stan. But the core is solid, the methodology is rigorous, and the documentation — both the README and the Wiki — is unusually thorough. If equation discovery is relevant to your work, this is a project worth watching and, more to the point, worth using.
Links: GitHub repository · Wiki (full theoretical foundations, recovery tests, and API reference)