By Dimitry Zakharov In September, 1935, physicists Gerhard and Luise Herzberg arrived in Saskatoon, Canada. This move was a leap of faith, as they had only learned of the small prairie city’s existence shortly before their journey, and secured a university position due to a chance friendship with the University of Saskatchewan chemistry professor John […]
Physics in Exile: Nazism, Anti-Semitism, and the 1933 Scientific Exodus
Tag: Ciencias
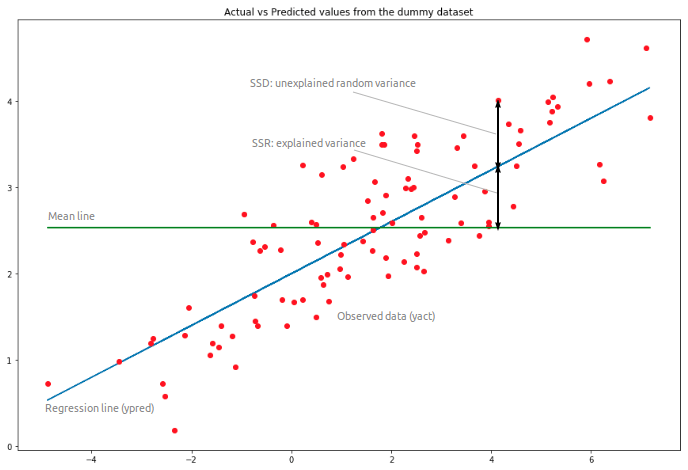
SUPUESTOS DEL MODELO CLÁSICO DE REGRESIÓN LINEAL Y DE LOS MODELOS LINEALES GENERALIZADOS
isadore nabi

REFERENCIAS
Banerjee, A. (29 de Octubre de 2019). Intuition behind model fitting: Overfitting v/s Underfitting. Obtenido de Towards Data Science: https://towardsdatascience.com/intuition-behind-model-fitting-overfitting-v-s-underfitting-d308c21655c7
Bhuptani, R. (13 de Julio de 2020). Quora. Obtenido de What is the difference between linear regression and least squares?: https://www.quora.com/What-is-the-difference-between-linear-regression-and-least-squares
Cross Validated. (23 de Marzo de 2018). Will log transformation always mitigate heteroskedasticity? Obtenido de StackExchange: https://stats.stackexchange.com/questions/336315/will-log-transformation-always-mitigate-heteroskedasticity
Greene, W. (2012). Econometric Analysis (Séptima ed.). Harlow, Essex, England: Pearson Education Limited.
Guanga, A. (11 de Octubre de 2018). Machine Learning: Bias VS. Variance. Obtenido de Becoming Human: Artificial Intelligence Magazine: https://becominghuman.ai/machine-learning-bias-vs-variance-641f924e6c57
Gujarati, D., & Porter, D. (8 de Julio de 2010). Econometría (Quinta ed.). México, D.F.: McGrawHill Educación. Obtenido de Homocedasticidad.
McCullagh, P., & Nelder, J. A. (1989). Generalized Linear Models (Segunda ed.). London: Chapman and Hall.
MIT Computer Science & Artificial Intelligence Lab. (6 de Mayo de 2021). Solving over- and under-determined sets of equations. Obtenido de Articles: http://people.csail.mit.edu/bkph/articles/Pseudo_Inverse.pdf
Nabi, I. (27 de Agosto de 2021). MODELOS LINEALES GENERALIZADOS. Obtenido de El Blog de Isadore Nabi: https://marxistphilosophyofscience.com/wp-content/uploads/2021/08/modelos-lineales-generalizados-isadore-nabi.pdf
Penn State University, Eberly College of Science. (2018). 10.4 – Multicollinearity. Obtenido de Lesson 10: Regression Pitfalls: https://online.stat.psu.edu/stat462/node/177/
Penn State University, Eberly College of Science. (24 de Mayo de 2021). Introduction to Generalized Linear Models. Obtenido de Analysis of Discrete Data: https://online.stat.psu.edu/stat504/lesson/6/6.1
Perezgonzalez, J. D. (3 de Marzo de 2015). Fisher, Neyman-Pearson or NHST? A tutorial for teaching data testing. frontiers in PSYCHOLOGY, VI(223), 1-11.
ResearchGate. (10 de Noviembre de 2014). How it can be possible to fit the four-parameter Fedlund model by only 3 PSD points? Obtenido de https://www.researchgate.net/post/How_it_can_be_possible_to_fit_the_four-parameter_Fedlund_model_by_only_3_PSD_points
ResearchGate. (28 de Septiembre de 2019). s there a rule for how many parameters I can fit to a model, depending on the number of data points I use for the fitting? Obtenido de https://www.researchgate.net/post/Is-there-a-rule-for-how-many-parameters-I-can-fit-to-a-model-depending-on-the-number-of-data-points-I-use-for-the-fitting
Salmerón Gómez, R., Blanco Izquierdo, V., & García García, C. (2016). Micronumerosidad aproximada y regresión lineal múltiple. Anales de ASEPUMA(24), 1-17. Obtenido de https://dialnet.unirioja.es/descarga/articulo/6004585.pdf
Simon Fraser University. (30 de Septiembre de 2011). THE CLASSICAL MODEL. Obtenido de http://www.sfu.ca/~dsignori/buec333/lecture%2010.pdf
StackExchange Cross Validated. (2 de Febrero de 2017). “Least Squares” and “Linear Regression”, are they synonyms? Obtenido de What is the difference between least squares and linear regression? Is it the same thing?: https://stats.stackexchange.com/questions/259525/least-squares-and-linear-regression-are-they-synonyms
Wikipedia. (18 de Marzo de 2021). Overdetermined system. Obtenido de Partial Differential Equations: https://en.wikipedia.org/wiki/Overdetermined_system
Zhao, J. (9 de Noviembre de 2017). More features than data points in linear regression? Obtenido de Medium: https://medium.com/@jennifer.zzz/more-features-than-data-points-in-linear-regression-5bcabba6883e

INTRODUCCIÓN A LOS ENSAYOS CLÍNICOS DESDE LA TEORÍA ESTADÍSTICA Y RSTUDIO: ASOCIACIÓN Y CORRELACIÓN DE PEARSON, SPEARMAN Y KENDALL
isadore NABI
### DISTRIBUCIÓN CHI-CUADRADO
###ORÍGENES HISTÓRICOS Y GENERALIDADES: https://marxianstatistics.com/2021/09/10/generalidades-sobre-la-prueba-chi-cuadrado/
###En su forma general, la distribución Chi-Cuadrado es una suma de los cuadrados de variables aleatorias N(media=0, varianza=1), véase https://mathworld.wolfram.com/Chi-SquaredDistribution.html.
###Se utiliza para describir la distribución de una suma de variables aleatorias al cuadrado. También se utiliza para probar la bondad de ajuste de una distribución de datos, si las series de datos son independientes y para estimar las confianzas que rodean la varianza y la desviación estándar de una variable aleatoria de una distribución normal.
### COEFICIENTES DE CORRELACIÓN
###Coeficiente de Correlación de Pearson (prueba paramétrica): https://statistics.laerd.com/statistical-guides/pearson-correlation-coefficient-statistical-guide.php, https://www.wikiwand.com/en/Pearson_correlation_coefficient.
###Coeficiente de Correlación de Spearman (prueba no-paramétrica): https://statistics.laerd.com/statistical-guides/spearmans-rank-order-correlation-statistical-guide.php, https://www.wikiwand.com/en/Spearman%27s_rank_correlation_coefficient, https://www.statstutor.ac.uk/resources/uploaded/spearmans.pdf.
###Coeficiente de Correlación de Kendall (prueba no-paramétrica): https://www.statisticshowto.com/kendalls-tau/, https://towardsdatascience.com/kendall-rank-correlation-explained-dee01d99c535, https://personal.utdallas.edu/~herve/Abdi-KendallCorrelation2007-pretty.pdf, https://www.wikiwand.com/en/Kendall_rank_correlation_coefficient.
####Como se verifica en su forma más general [véase Jeremy M. G. Taylor, Kendall’s and Spearman’s Correlation Coefficient in the Presence of a Blocking Variable, (Biometrics, Vol. 43, No. 2 (Jun., 1987), pp.409-416), p. 409], en presencia de “empates”, conocidos también como “observaciones vinculadas” (del inglés “ties”, que, como se verifica en http://www.statistics4u.com/fundstat_eng/dd_ties.html, significa en el contexto de las estadísticas de clasificación de orden -rank order statistics- la existencia de dos o más observaciones que tienen el mismo valor, por lo que imposibilita la asignación de números de rango únicos), es preferible utilizar el coeficiente de correlación de Spearman rho porque su varianza posee una forma más simple (relacionado con el costo computacional, puesto que la investigación de Jeremy Taylor emplea como herramienta de estadística experimental la metodología Monte Carlo, lo que puede verificarse en https://pdodds.w3.uvm.edu/files/papers/others/1987/taylor1987a.pdf).
### RIESGO RELATIVO
####Como se verifica en https://www.wikiwand.com/en/Odds_ratio, el riesgo relativo (diferente a la razón éxito/fracaso y a la razón de momios) es la proporción de éxito de un evento (o de fracaso) en términos del total de ocurrencias (éxitos más fracasos).
### RAZÓN ÉXITO/FRACASO
####Es el cociente entre el número de veces que ocurre un evento y el número de veces en que no ocurre.
####INTERPRETACIÓN: Para interpretar la razón de ataque/no ataque de forma más intuitiva se debe multiplicar dicha razón Ψ (psi) por el número de decenas necesarias Ξ (Xi) para que la razón tenga un dígito d^*∈N a la izquierda del “punto decimal” (en este caso de aplicación hipotético Ξ=1000), resultando así un escalar real υ=Ψ*Ξ (donde υ es la letra griega ípsilon) con parte entera que se interpreta como “Por cada Ξ elementos de la población de referencia bajo la condición especificada (en este caso, que tomó aspirina o que tomó un placebo) estará presente la característica (u ocurrirá el evento, según sea el caso) en (d^*+h) ocasiones, en donde h es el infinitesimal a la derecha del punto decimal (llamado así porque separa no sólo los enteros de los infinitesimales, sino que a su derecha se encuentra la casilla correspondiente justamente a algún número decimal).
### RAZÓN DE MOMIOS
####DEFÍNICIÓN: Es una medida utilizada en estudios epidemiológicos transversales y de casos y controles, así como en los metaanálisis. En términos formales, se define como la posibilidad que una condición de salud o enfermedad se presente en un grupo de población frente al riesgo que ocurra en otro. En epidemiología, la comparación suele realizarse entre grupos humanos que presentan condiciones de vida similares, con la diferencia que uno se encuentra expuesto a un factor de riesgo (mi) mientras que el otro carece de esta característica (mo). Por lo tanto, la razón de momios o de posibilidades es una medida de tamaño de efecto.
####Nótese que es un concepto, evidentemente, de naturaleza frecuentista.
####La razón de momios es el cociente entre las razones de ocurrencia/no-ocurrencia de los tratamientos experimentales estudiados (una razón por cada uno de los dos tratamientos experimentales sujetos de comparación).
### TAMAÑO DEL EFECTO
####Defínase tamaño del efecto como cualquier medida realizada sobre algún conjunto de características (que puede ser de un elemento) relativas a cualquier fenómeno, que es utilizada para abordar una pregunta de interés, según (Kelly y Preacher 2012, 140). Tal y como ellos señalan, la definición es más que una combinación de “efecto” y “tamaño” porque depende explícitamente de la pregunta de investigación que se aborde. Ello significa que lo que separa a un tamaño de efecto de un estadístico de prueba (o estimador) es la orientación de su uso, si responde una pregunta de investigación en específico entonces el estadístico (o parámetro) se convierte en un “tamaño de efecto” y si sólo es parte de un proceso global de predicción entonces es un estadístico (o parámetro) a secas, i.e., su distinción o, expresado en otros términos, la identificación de cuándo un estadístico (o parámetro) se convierte en un tamaño de efecto, es una cuestión puramente epistemológica, no matemática. Lo anterior simplemente implica que, dependiendo del tipo de pregunta que se desee responder el investigador, un estadístico (o parámetro) será un tamaño de efecto o simplemente un estadístico (o parámetro) sin más.
setwd(“C:/Users/User/Desktop/Carpeta de Estudio/Maestría Profesional en Estadística/Semestre II-2021/Métodos, Regresión y Diseño de Experimentos/2/Laboratorios/Laboratorio 2”)
## ESTIMAR EL COEFICIENTE DE CORRELACIÓN DE PEARSON ENTRE TEMPERATURA Y PORCENTAJE DE CONVERSIÓN
###CÁLCULO MANUAL DE LA COVARIANZA
prom.temp = mean(temperatura)
prom.conversion = mean(porcentaje.conversion)
sd.temp = sd(temperatura)
sd.conversion = sd(porcentaje.conversion)
n = nrow(vinilacion)
covarianza = sum((temperatura-prom.temp)*(porcentaje.conversion-prom.conversion))/(n-1)
covarianza
###La covarianza es una medida para indicar el grado en el que dos variables aleatorias cambian en conjunto (véase https://www.mygreatlearning.com/blog/covariance-vs-correlation/#differencebetweencorrelationandcovariance).
###CÁLCULO DE LA COVARIANZA DE FORMA AUTOMATIZADA
cov(temperatura,porcentaje.conversion)
###CÁLCULO MANUAL DEL COEFICIENTE DE CORRELACIÓN DE PEARSON
###Véase https://www.wikiwand.com/en/Pearson_correlation_coefficient (9 de septiembre de 2021).
coef.correlacion = covarianza/(sd.temp*sd.conversion)
coef.correlacion
###CÁLCULO AUTOMATIZADO DEL COEFICIENTE DE CORRELACIÓN DE PEARSON
cor(temperatura,porcentaje.conversion) ###Salvo que se especifique lo contrario (como puede verificarse en la librería de R), el coeficiente de correlación calculado por defecto será el de Pearson, sin embargo, se puede calcular también el coeficiente de Kendall (escribiendo “kendall” en la casilla “method” de la sintaxis “cor”) o el de Spearman (escribiendo “spearman” en la casilla “method” de la sintaxis “cor”).
cor(presion,porcentaje.conversion)
###VÍNCULO, SIMILITUDES Y DIFERENCIAS ENTRE CORRELACIÓN Y COVARIANZA
###El coeficiente de correlación está íntimamente vinculado con la covarianza. La covarianza es una medida de correlación y el coeficiente de correlación es también una forma de medir la correlación (que difiere según sea de Pearson, Kendall o Spearman).
###La covarianza indica la dirección de la relación lineal entre variables, mientras que el coeficiente de correlación mide no sólo la dirección sino además la fuerza de esa relación lineal entre variables.
###La covarianza puede ir de menos infinito a más infinito, mientras que el coeficiente de correlación oscila entre -1 y 1.
###La covarianza se ve afectada por los cambios de escala: si todos los valores de una variable se multiplican por una constante y todos los valores de otra variable se multiplican por una constante similar o diferente, entonces se cambia la covarianza. La correlación no se ve influenciada por el cambio de escala.
###La covarianza asume las unidades del producto de las unidades de las dos variables. La correlación es adimensional, es decir, es una medida libre de unidades de la relación entre variables.
###La covarianza de dos variables dependientes mide cuánto en cantidad real (es decir, cm, kg, litros) en promedio covarían. La correlación de dos variables dependientes mide la proporción de cuánto varían en promedio estas variables entre sí.
###La covarianza es cero en el caso de variables independientes (si una variable se mueve y la otra no) porque entonces las variables no necesariamente se mueven juntas (por el supuesto de ortogonalidad entre los vectores, que expresa geométricamente su independencia lineal). Los movimientos independientes no contribuyen a la correlación total. Por tanto, las variables completamente independientes tienen una correlación cero.
## CREAR UNA MATRIZ DE CORRELACIONES DE PEARSON Y DE SPEARMAN
####La vinilación de los glucósidos se presenta cuando se les agrega acetileno a alta presión y alta temperatura, en presencia de una base para producir éteres de monovinil.
###Los productos de monovinil éter son útiles en varios procesos industriales de síntesis.
###Interesa determinar qué condiciones producen una conversión máxima de metil glucósidos para diversos isómeros de monovinil.
cor(vinilacion) ###Pearson
cor(vinilacion, method=”spearman”) ###Spearman
## CREAR UNA MATRIZ DE VARIANZAS Y COVARIANZAS (LOCALIZADAS ESTAS ÚLTIMAS EN LA DIAGONAL PRINCIPAL DE LA MATRIZ)
cov(vinilacion)
## GENERAR GRÁFICOS DE DISPERSIÓN
plot(temperatura,porcentaje.conversion)
plot(porcentaje.conversion~temperatura)
mod = lm(porcentaje.conversion~temperatura)
abline(mod,col=2)
###La sintaxis “lm” es usada para realizar ajuste de modelos lineales (es decir, ajustar un conjunto de datos a la curva dibujada por un modelo lineal -i.e., una línea recta-, lo cual -si es estadísticamente robusto- implica validar que el conjunto de datos en cuestión posee un patrón de comportamiento geométrico lineal).
###La sintaxis “lm” puede utilizar para el ajuste el método de los mínimos cuadrados ponderados o el método de mínimos cuadrados ordinarios, en función de si la opción “weights” se llena con un vector numérico o con “NULL”, respectivamente).
### La casilla “weights” de la sintaxis “lm” expresa las ponderaciones a utilizar para realizar el proceso de ajuste (si las ponderaciones son iguales para todas las observaciones, entonces el método de mínimos cuadrados ponderados se transforma en el método de mínimos cuadrados ordinarios). Estas ponderaciones son, en términos computacionales, aquellas que minimizan la suma ponderada de los errores al cuadrado.
###Las ponderaciones no nulas pueden user usadas para indicar diferentes varianzas (con los valores de las ponderaciones siendo inversamente proporcionales a la varianza); o, equivalentemente, cuando los elementos del vector de ponderaciones son enteros positivos w_i, en donde cada respuesta y_i es la media de las w_j unidades observacionales ponderadas (incluyendo el caso de que hay w_i observaciones iguales a y_i y los datos se han resumido).
###Sin embargo, en el último caso, observe que no se utiliza la variación dentro del grupo. Por lo tanto, la estimación sigma y los grados de libertad residuales pueden ser subóptimos; en el caso de pesos de replicación, incluso incorrecto. Por lo tanto, los errores estándar y las tablas de análisis de varianza deben tratarse con cuidado.
###La estimación sigma se refiere a la sintaxis “sigma” que estima la desviación estándar de los errores (véase https://stat.ethz.ch/R-manual/R-devel/library/stats/html/sigma.html).
###Si la variable de respuesta (o dependiente) es una matriz, un modelo lineal se ajusta por separado mediante mínimos cuadrados a cada columna de la matriz.
###Cabe mencionar que “formula” (la primera entrada de la sintaxis “lm”) tiene un término de intersección implícito (recuérdese que toda ecuación de regresión tiene un intercepto B_0, que puede ser nulo). Para eliminar dicho término, debe usarse y ~ x – 1 o y ~ 0 + x.
plot(presion~porcentaje.conversion)
mod = lm(presion~porcentaje.conversion) ###Ajuste a la recta antes mencionado y guardado bajo el nombre “mod”.
abline(mod,col=2) ###Es crear una línea color rojo (col=2) en la gráfica generada (con la función “mod”)
## REALIZAR PRUEBA DE HIPÓTESIS PARA EL COEFICIENTE DE CORRELACIÓN
###Véase https://opentextbc.ca/introstatopenstax/chapter/testing-the-significance-of-the-correlation-coefficient/, https://online.stat.psu.edu/stat501/lesson/1/1.9,
###Para estar casi seguros (en relación al concepto de convergencia) Para asegurar que existe al menos una leve correlación entre dos variables (X,Y) se tiene que probar que el coeficiente de correlación poblacional (r) no es nulo.
###Para que la prueba de hipótesis tenga validez se debe verificar que la distribución de Y para cada X es normal y que sus valores han sido seleccionados aleatoriamente.
###Si se rechaza la hipótesis nula, no se asegura que haya una correlación muy alta.
###Si el valor p es menor que el nivel de significancia se rechaza la Ho de que el coeficiente de correlación entre Y y X es cero en términos de determinado nivel de significancia estadística.
###Evaluar la significancia estadística de un coeficiente de correlación puede contribuir a validar o refutar una investigación donde este se haya utilizado (siempre que se cuenten con los datos empleados en la investigación), por ejemplo, en el uso de modelos lineales de predicción.
###Se puede utilizar la distribución t con n-2 grados de libertad para probar la hipótesis.
###Como se observará a continuación, además de la forma estándar, también es posible calcular t como la diferencia entre el coeficiente de correlación.
###Si la probabilidad asociada a la hipótesis nula es casi cero, puede afirmarse a un nivel de confianza determinado de que la correlación es altamente significativa en términos estadísticos.
###FORMA MANUAL
ee = sqrt((1-coef.correlacion^2)/(n-2))
t.calculado = (coef.correlacion-0)/ee ###Aquí parece implicarse que el valor t puede calcularse como el cociente entre el coeficiente de correlación muestral menos el coeficiente de correlación poblacional sobre el error estándar de la media.
2*(1-pt(t.calculado,n-2))
###FORMA AUTOMATIZADA
cor.test(temperatura,porcentaje.conversion) ###El valor del coeficiente de correlación que se ha estipulado (que es cero) debe encontrarse dentro del intervalo de confianza al nivel de probabilidad pertinente para aceptar Ho y, caso contrario, rechazarla.
cor.test(temperatura,presion)
###Como se señala en https://marxianstatistics.com/2021/09/05/analisis-teorico-de-la-funcion-cuantil-en-r-studio/, calcula el valor umbral x por debajo del cual se encuentran las observaciones sobre el fenómeno de estudio en una proporción P de las ocasiones (nótese aquí una definición frecuentista de probabilidad), incluyendo el umbral en cuestión.
qt(0.975,6)
### EJEMPLO DE APROXIMACIÓN COMPUTACIONAL DE LA DISTRIBUCIÓN t DE STUDENT A LA DISTRIBUCIÓN NORMAL
###El intervalo de confianza se calcula realizando la transformación-z de Fisher (tanto con la función automatizada de R como con la función personalizada elaborada) como a nivel teórico), la cual se utiliza porque cuando la transformación se aplica al coeficiente de correlación muestral, la distribución muestral de la variable resultante es aproximadamente normal, lo que implica que posee una varianza que es estable sobre diferentes valores de la correlación verdadera subyacente (puede ampliarse más en https://en.wikipedia.org/wiki/Fisher_transformation).
coef.correlacion+c(-1,1)*qt(0.975,6)*ee ###Intervalo de confianza para el estadístico de prueba sujeto de hipótesis (el coeficiente de correlación, en este caso) distribuido como una distribución t de Student.
coef.correlacion+c(-1,1)*qnorm(0.975)*ee ###Intervalo de confianza para el estadístico de prueba sujeto de hipótesis (el coeficiente de correlación, en este caso) distribuido normalmente.
## CASO DE APLICACIÓN HIPOTÉTICO
###En un estudio sobre el metabolismo de una especie salvaje, un biólogo obtuvo índices de actividad y datos sobre tasas metabólicas para 20 animales observados en cautiverio.
rm(list=ls()) ###Remover todos los objetos de la lista
actividad <- read.csv(“actividad.csv”, sep = “,”, dec=”.”, header = T)
attach(actividad)
n=nrow(actividad)
str(actividad)####”str” es para ver qué tipo de dato es cada variable.
plot(Indice.actividad,Tasa.metabolica)
###Coeficiente de Correlación de Pearson
cor(Indice.actividad,Tasa.metabolica, method=”pearson”)
###Se rechaza la hipótesis nula de que la correlación de Pearson es 0.
###Coeficiente de correlación de Spearman
(corr = cor(Indice.actividad,Tasa.metabolica, method=”spearman”))
(t.s=corr*(sqrt((n-2)/(1-(corr^2)))))
(gl=n-2)
(1-pt(t.s,gl))*2
###Se rechaza la hipótesis nula de que la correlación de Spearman es 0.
###NOTA ADICIONAL:
###Ambas oscilan entre -1 y 1. El signo negativo denota la relacion inversa entre ambas. La correlacion de Pearson mide la relación lineal entre dos variables (correlacion 0 es independencia lineal, que los vectores son ortogonales). La correlación de Pearson es para variables numérica de razón y tiene el supuesto de normalidad en la distribución de los valores de los datos. Cuando los supuestos son altamente violados, lo mejor es usar una medida de correlación no-paramétrica, específicamente el coeficiente de Spearman. Sobre el coeficiente de Spearman se puede decir lo mismo en relación a la asociación. Así, valores de 0 indican correlación 0, pero no asegura que por ser cero las variables sean independientes (no es concluyente).
### TABLAS DE CONTINGENCIA Y PRUEBA DE INDEPENDENCIA
###Una tabla de contingencia es un arreglo para representar simultáneamente las cantidades de individuos y sus porcentajes que se presentan en cada celda al cruzar dos variables categóricas.
###En algunos casos una de las variables puede funcionar como respuesta y la otra como factor, pero en otros casos sólo interesa la relación entre ambas sin intentar explicar la dirección de la relación.
###CASO DE APLICACIÓN HIPOTÉTICO
###Un estudio de ensayos clínicos trataba de probar si la ingesta regular de aspirina reduce la mortalidad por enfermedades cardiovasculares. Los participantes en el estudio tomaron una aspirina o un placebo cada dos días. El estudio se hizo de tal forma que nadie sabía qué pastilla estaba tomando. La respuesta es que si presenta o no ataque cardiaco (2 niveles),
rm(list=ls())
aspirina = read.csv(“aspirina.csv”, sep = “,”, dec=”.”, header = T)
aspirina
str(aspirina)
attach(aspirina)
names(aspirina)
str(aspirina)
View(aspirina)
#### 1. Determinar las diferencias entre la proporción a la que ocurrió un ataque dependiendo de la pastilla que consumió. Identifique el porcentaje global en que presentó ataque y el porcentaje global en que no presentó.
e=tapply(aspirina$freq,list(ataque,pastilla),sum) ###Genera la estructura de la tabla con la que se trabajará (la base de datos organizada según el diseño experimental previamente realizado).
prop.table(e,2) ###Riesgo Relativo columna. Para verificar esto, contrástese lo expuesto al inicio de este documento con la documentación CRAN [accesible mediante la sintaxis “?prop.table”] para más detalles.
prop.table(e,1) ###Riesgo Relativo fila. Para verificar esto, contrástese lo expuesto al inicio de este documento con la documentación CRAN [accesible mediante la sintaxis “?prop.table”] para más detalles.
(et=addmargins(e)) ###Tabla de contingencia.
addmargins(prop.table(e)) ####Distribución porcentual completa.
###Si se asume que el tipo de pastilla no influye en el hecho de tener un ataque cardíaco, entonces, debería de haber igual porcentaje de ataques en la columna de médicos que tomaron aspirina que en la de los que tomaron placebo.
###Se obtiene el valor esperado de ataques y no ataques.
### Lo anterior se realiza bajo el supuesto de que hay un 1.3% de ataques en general y un 98.7% de no ataques.
#### 2. Usando los valores observados y esperados, calcular el valor de Chi-Cuadrado para determinar si existe dependencia entre ataque y pastilla?
###Al aplicar la distribución Chi cuadrado, que es una distribución continua, para representar un fenómeno discreto, como el número de casos en cada unos de los supuestos de la tabla de 2*2, existe un ligero fallo en la aproximación a la realidad. En números grandes, esta desviación es muy escasa, y puede desecharse, pero cuando las cantidades esperadas en alguna de las celdas son números pequeños- en general se toma como límite el que tengan menos de cinco elementos- la desviación puede ser más importante. Para evitarlo, Yates propuso en 1934 una corrección de los métodos empleados para hallar el Chi cuadrado, que mejora la concordancia entre los resultados del cálculo y la distribución Chi cuadrado. En el articulo anterior, correspondiente a Chi cuadrado, el calculador expone, además de los resultados de Chi cuadrado, y las indicaciones para decidir, con arreglo a los límites de la distribución para cada uno de los errores alfa admitidos, el rechazar o no la hipótesis nula, una exposición de las frecuencias esperadas en cada una de las casillas de la tabla de contingencia, y la advertencia de que si alguna de ellas tiene un valor inferior a 5 debería emplearse la corrección de Yates. Fuente: https://www.samiuc.es/estadisticas-variables-binarias/valoracion-inicial-pruebas-diagnosticas/chi-cuadrado-correccion-yates/.
###Como se señala en [James E. Grizzle, Continuity Correction in the χ2-Test for 2 × 2 Tables, (The American Statistician, Oct., 1967, Vol. 21, No. 4 (Oct., 1967), pp. 28-32), p. 29-30], técnicamente hablando, la corrección de Yates hace que “(…) las probabilidades obtenidas bajo la distribución χ2 bajo la hipótesis nula converjan de forma más cercana con las probabilidades obtenidas bajo el supuesto de que el conjunto de datos fue generado por una muestra proveniente de la distribución hipergeométrica, i.e., generados bajo el supuesto que los dos márgenes de la tabla fueron fijados con antelación al muestreo.”
###Grizzle se refiere con “márgenes” a los totales de la tabla (véase https://www.tutorialspoint.com/how-to-create-a-contingency-table-with-sum-on-the-margins-from-an-r-data-frame). Además, la lógica de ello subyace en la misma definición matemática de la distribución hipergeométrica. Como se puede verificar en RStudio mediante la sintaxis “?rhyper”, la distribución hipergeométrica tiene la estructura matemática (distribución de probabilidad) p(x) = choose(m, x) choose(n, k-x)/choose(m+n, k), en donde m es el número de éxitos, n es el número de fracasos lo que ) y k es el tamaño de la muestra (tanto m, n y k son parámetros en función del conjunto de datos, evidentemente), con los primeros dos momentos definidos por E[X] = μ = k*p y la varianza se define como Var(X) = k p (1 – p) * (m+n-k)/(m+n-1). De lo anterior se deriva naturalmente que para realizar el análisis estocástico del fenómeno modelado con la distribución hipergeométrica es necesario conocer la cantidad de sujetos que representan los éxitos y los fracasos del experimento (en donde “éxito” y “fracaso” se define en función del planteamiento del experimento, lo cual a su vez obedece a múltiples factores) y ello implica que se debe conocer el total de los sujetos experimentales estudiados junto con su desglose en los términos binarios ya especificados.
###Lo mismo señalado por Grizzle se verifica (citando a Grizzle) en (Biometry, The Principles and Practice of Statistics in Biological Research, Robert E. Sokal & F. James Rohlf, Third Edition, p. 737), especificando que se vuelve innecesaria la corrección de Yates aún para muestras de 20 observaciones.
###Adicionalmente, merece mención el hecho que, como es sabido, la distribución binomial se utiliza con frecuencia para modelar el número de éxitos en una muestra de tamaño n extraída con reemplazo de una población de tamaño N. Sin embargo, si el muestreo se realiza sin reemplazo, las muestras extraídas no son independientes y, por lo tanto, la distribución resultante es una hipergeométrica; sin embargo, para N mucho más grande que n, la distribución binomial sigue siendo una buena aproximación y se usa ampliamente (véase https://www.wikiwand.com/en/Binomial_distribution).
###Grados de libertad correspondientes: número de filas menos 1 por número de columnas menos 1.
###Ho = Hay independencia entre el ataque y las pastillas.
(tabla.freq<-xtabs(freq~ataque+pastilla, data=aspirina))
###La tabla de frecuencias contiene tanto las frecuencias observadas como las esperadas.
###La frecuencia esperada es el conteo de observaciones que se espera en una celda, en promedio, si las variables son independientes.
###La frecuencia esperada de una variable se calcula como el producto entre el cociente [(Total de la Columna j)/(Total de Totales)]*(Total Fila i).
###PRUEBA CHI-CUADRADO AUTOMATIZADA
(prueba.chi<-chisq.test(tabla.freq,correct=F) ) ###La sintaxis “chisq.test” sirve para realizar la prueba de Chi-Cuadrado en tablas de contingencia y para realizar pruebas de bondad de ajuste.
names(prueba.chi)
###PRUEBA CHI-CUADRADO PASO A PASO
(esperado<-prueba.chi$expected) ###valores esperados
(observado<-prueba.chi$observed) ###valores observados
(cuadrados<-(esperado-observado)^2/esperado)
(chi<-sum(cuadrados))
1-pchisq(chi,1) ###Valor de p de la distribución Chi-Cuadrado (especificada mediante el conjunto de datos) calculado de forma no-automatizada.
###Si el valor p es mayor que el nivel de significancia se falla en rechazar Ho, si es menor se rechaza Ho.
###Se rechaza Ho con un nivel de significancia alfa de 0.05. Puesto que se tiene una probabilidad muy baja de cometer error tipo I, i.e., rechazar la hipótesis nula siendo falsa.