Consider an optimization problem in standard form: with the variable . Let be the domain for , i.e. the intersection of the domains of the ‘s and the ‘s. Let denote the optimal value of the problem. The Lagrange dual function is the function defined as the minimum value of the Lagrangian over : The […]
Lagrange dual, weak duality and strong duality
Tag: Función
The Lagrange dual function is always concave
Consider an optimization problem in standard form: with the variable . Let be the domain for , i.e. the intersection of the domains of the ‘s and the ‘s. The Lagrangian associated with this problem is the function defined as with domain . The Lagrange dual function is the function defined as the minimum value […]
The Lagrange dual function is always concave
A short note on the startsWith function
The startsWith function comes with base R, and determines whether entries of an input start with a given prefix. (The endsWith function does the same thing but for suffixes.) The following code checks if each of “ant”, “banana” and “balloon” starts with “a”: The second argument (the prefix to check) can also be a vector. […]
A short note on the startsWith function
SOBRE LA VISIÓN MARXISTA DE LA EXISTENCIA COMO ESTRUCTURA ORGÁNICA OBJETIVA (BORRADOR)
II.XI. Ley de Conexión Universal y Acción Recíproca
Como señalan (Fundación Gustavo Bueno, 2021), (Rosental & Iudin, 1971, págs. 78-79) y (Frolov, 1984, págs. 76-77), la conexión y la acción recíproca entre los objetos y los fenómenos de la Naturaleza y de la Sociedad tienen un carácter universal. La dialéctica materialista sostiene por eso, que ni un solo fenómeno de la Naturaleza y de la Sociedad puede ser comprendido si se le toma fuera de sus conexiones con los fenómenos circundantes. Por ejemplo, el sistema solar representa un todo único, todas sus partes se hallan en conexión mutua, en acción recíproca. La conexión mutua tiene lugar entre los animales y las condiciones geográficas que los rodean. En la sociedad humana, todas sus parten se hallan también en la más íntima relación mutua y recíproco condicionamiento. Así, tal o cual ideología puede ser comprendida sólo en relación con todo el conjunto de las condiciones materiales de la vida de la sociedad, con la lucha de clases, etc. Todo régimen y movimiento sociales que aparecen en la historia deben ser juzgados desde el punto de vista de las condiciones que los han engendrado y a los que se hallan vinculados; el régimen de la esclavitud, dentro de las condiciones modernas, es un absurdo, pero dentro de las condiciones de desintegración del régimen del comunismo primitivo era un fenómeno perfectamente lógico y natural, y representaba un progreso en comparación con el comunismo primitivo. De igual forma, no se puede explicar científicamente un fenómeno tal como las guerras imperialistas si se las separa del modo de producción capitalista, de las contradicciones efectivas del capitalismo. Por eso hay que abordar cada fenómeno desde el punto de vista histórico. Lo que es real y natural en unas condiciones históricas pierde todo sentido en otras. La existencia de la acción recíproca entre los fenómenos no supone que todas las causas y efectos sean importantes en igual grado: el método dialéctico exige que se indaguen las bases de esa interacción, que se establezcan las causas decisivas, fundamentales, que condicionaron tal o cual fenómeno.
Así, por oposición a la metafísica, la dialéctica materialista no considera la naturaleza como un conglomerado casual de objetos y fenómenos, desligados y aislados unos de los otros y sin ninguna relación de dependencia entre sí (puesto que ello termina siempre por derivar en una concepción de la naturaleza como una aglomeración caótica de hechos accidentales), sino como un todo articulado y único, en el que los objetos y fenómenos se hallan orgánicamente vinculados unos a otros, dependen unos de otros y se condicionan los unos a los otros. Por eso, el método dialéctico entiende que ningún fenómeno de la naturaleza puede ser comprendido si se le enfoca aisladamente, sin conexión con los fenómenos que le rodean, pues todo fenómeno, tomado de cualquier campo de la naturaleza, puede convertirse en un absurdo, si se le examina sin conexión con las condiciones que le rodean, desligado de ellas; y por el contrario, todo fenómeno puede ser comprendido y explicado, si se le examina en su conexión indisoluble con los fenómenos circundantes y condicionado por ellos.
Sin embargo, la dialéctica materialista plantea que no basta tener en cuenta el encadenamiento de causas y efectos, sino que es preciso subrayar también que la causa y el efecto actúan el uno sobre el otro. Así, todo régimen político está determinado por el régimen económico que lo ha engendrado. Pero a su vez, el poder político ejerce una influencia considerable sobre el régimen económico. No es posible analizar el modo de producción capitalista, que se halla desgarrado por las contradicciones y no es más que una traba al desarrollo de las fuerzas productivas, sin tener en cuenta el papel que desempeña el poder político de la burguesía, pues ésta, todavía en el poder, trata de eternizar por todos los medios el modo de producción fundado sobre la explotación del hombre por el hombre. Los fenómenos deben ser enfocados desde el punto de vista de su interacción y de su condicionamiento recíproco, pues se cometería un error grosero si sólo se dijera que las relaciones de producción están en función de las fuerzas productivas. Sería un procedimiento unilateral, porque, engendradas por las fuerzas productivas, las relaciones de producción desempeñan, si corresponden a las fuerzas productivas, un papel importantísimo en el desarrollo de estas últimas (y en caso contrario, un papel importantísimo en el freno a su desarrollo).
El alcance y la importancia del principio de la conexión y de la interacción de los fenómenos, reside en que destaca claramente un hecho esencial: el mundo real está regido por leyes. El encadenamiento de los fenómenos significa que las contingencias no dominan en la naturaleza y en la sociedad; que son las leyes objetivas, independientes de la voluntad y de la conciencia humanas, las que determinan el desarrollo. La conexión y la interacción de la causa y del efecto condicionan el curso necesario de los fenómenos de la naturaleza y la vida social. Hay que estudiar los regímenes y los movimientos sociales desde el punto de vista de las condiciones que los han engendrado y a las cuales están vinculados. En nuestros días, sería absurdo el régimen de esclavitud, mientras que en la época en que la comuna primitiva se disgregaba, representaba un fenómeno necesario, un paso adelante. Del mismo modo, el régimen capitalista, progresivo en ciertas condiciones históricas, constituye hoy un obstáculo al progreso de la sociedad.
Saber abordar los hechos reales es tener en cuenta las condiciones concretas de lugar y tiempo, por lo que la concatenación de los fenómenos de la forma antes expuesta ayuda a mostrar la sofística y el eclecticismo que reside en aquellas separaciones arbitrarias de ciertos aspectos de un fenómeno complejo, en la confusión de considerar equivalentes condiciones históricas diferentes, en la transposición mecánica en una situación nueva lo que no es valedero sino en una situación dada, etc.
Esta ley es la ley más general de la existencia del mundo; constituye el resultado y la manifestación de la interacción universal de todos los objetos y fenómenos, es la regularidad más general de la existencia del mundo. Expresa la unidad estructural interna de todos los elementos y propiedades en cada sistema íntegro, así como los nexos y relaciones infinitamente diversos del sistema dado con los sistemas o fenómenos que le rodean. En esta ley se manifiestan la unidad del mundo material y la determinación de cualquier fenómeno por otros procesos materiales, es decir, la interacción universal de los cuerpos condiciona la existencia misma de los objetos materiales concretos y todas sus peculiaridades específicas. La conexión universal de los fenómenos tiene manifestaciones infinitamente diversas. Incluye las relaciones entre las propiedades particulares de los cuerpos o de los fenómenos concretos de la naturaleza, relaciones que encuentran su expresión en leyes específicas; también incluye las relaciones entre las propiedades universales de la materia y las tendencias de desarrollo que encuentran su manifestación en las leyes dialécticas universales del ser. De ahí que toda ley sea una expresión concreta de la conexión universal de los fenómenos. Gracias a tal conexión, el mundo no constituye un amontonamiento caótico de fenómenos, sino un proceso universal único, sujeto a ley del movimiento, es decir, es un proceso lógico único de movimiento y desarrollo de la materia.
Los nexos entre los objetos y los fenómenos pueden ser directos o indirectos, permanentes o temporales, esenciales o inesenciales, casuales o necesarios, funcionales (dependencia funcional) o no funcionales, etc. La conexión universal de los fenómenos se halla estrechamente vinculada a la causalidad, más la causa y el efecto como tales sólo pueden ser examinados al margen de la conexión universal de unos fenómenos con otros. Si la causa y el efecto, por el contrario, se ponen en conexión con el todo, pasan una al otro, se transforman en conexión e interacción universales. Constituye un caso particular de esta interconexión la retroconexión en todos los sistemas que se regulan automáticamente.
Debe establecerse además que no es posible reducir a la mera interacción física de los cuerpos el nexo entre los fenómenos, puesto que, aparte de ella, existen relaciones biológicas y sociales incomparablemente más complejas que se subordinan a sus leyes específicas. A medida que avanza el desarrollo de la materia y va pasando a formas más elevadas de organización, se complican también las formas de interconexión de los cuerpos, aparecen especies de movimiento cualitativamente nuevas. Esta ley impera asimismo en lo que respecta al desenvolvimiento de la sociedad humana, en la cual, a medida que progresan los modos de producción y la civilización se desarrolla, se hacen más complejos los nexos entre los individuos y los estados, se diversifican cada vez más las relaciones políticas, económicas, ideológicas, etc. Este concepto es de gran alcance cognoscitivo. El mundo objetivo sólo puede conocerse investigando las formas de conexión causales y de otro tipo entre los fenómenos, delimitando los nexos y relaciones más esenciales, etc., es decir, a través de la investigación multilateral y sistemática de cualesquiera objetos y la segregación de todas las conexiones y relaciones esenciales, así como de las leyes de tales conexiones. El progreso del conocimiento cobra realidad en el movimiento del pensar, que pasa de reflejar conexiones menos profundas y generales a establecer nexos y relaciones más profundos y más generales entre los fenómenos y procesos. La estructura misma de las ciencias y su clasificación constituyen un reflejo de la conexión universal de los fenómenos. Así se explica que con el progreso del saber científico los lazos y la interacción de las ciencias entre sí se hagan cada vez más estrechos, y que surjan ciencias “limítrofes” que anudan esferas del saber antes separadas (por ejemplo, la bioquímica, la astrofísica, etc.).
Como una demostración parcial de esta ley, la más general entre las leyes de la dialéctica y de la existencia de la realidad misma, se estudiará la investigación de (Vitiello, 2014), que muestra que existe un isomorfismo entre sistemas disipativos, sistemas fractales auto-similares y sistemas electrodinámicos, lo que plantea, en según sus palabras, una “visión integrada de la Naturaleza” (p. 203).
Como señala (Lesne, Renormalization Methods, 1998, pág. 1), en aproximadamente los últimos cincuenta años han aparecido en la comunidad científica, primero en la teoría de campos y luego en varios otros dominios como la física estadística y los sistemas dinámicos, los términos “métodos de renormalización”, “grupo de renormalización” y “operadores de renormalización”. Las técnicas analíticas a las que se refieren estas expresiones son fundamentales para el estudio de lo que se conoce como fenómenos críticos, por el fracaso de los métodos anteriores; su desarrollo siguió a la aparición de la noción de invariancia de escala.” Así, ejemplos concretos, como la transición líquido-gas de una sustancia pura, sugieren la distinción entre los siguientes tipos de sistemas:
- Sistemas homogéneos a gran escala, ilustrado por la imagen de un tablero de ajedrez.
- Sistemas críticos auto-similares, ilustrados por la imagen de un globo, y cuyas propiedades macroscópicas se expresan mediante leyes de escala; los métodos de renormalización son esenciales aquí. Fueron concebidos para dar un valor explícito a los exponentes asociados y mostrar sus propiedades de universalidad, si las hubiese.
Figura 2: Fenómeno Crítico como Superposición Estable de Fase Sólida y Fase Líquida

Un fenómeno crítico es aquel que ocurre cuando, como resultado de la acción de fuerzas (para el ejemplo gráfico dado, estas fuerzas imprimen presión y temperatura sobre el sistema físico del entorno sobre un determinado sistema en una magnitud que excede el umbral[1]), dicho sistema manifiesta una coexistencia estable entre dos fases (estados), cuando regularmente estos estados están ligados entre sí en algún orden temporal (i.e., no-simultáneo).
Como señala (Lesne, Renormalization Methods, 1998, pág. 2), las nociones sobre el comportamiento colectivo de los grados de libertad en sistemas estadísticos que analizan el mundo microscópico es revelada por el estudio de las fluctuaciones y de las correlaciones estadísticas, mientras que la noción de fenómeno crítico[2], que es precisamente resultante del comportamiento colectivo antes descrito, es una noción perceptible en todas las escalas y versa sobre la divergencia crítica (respecto de un valor crítico) de ciertas cantidades macroscópicas descritas por las leyes de escala y por sus exponentes (conocidos como exponentes críticos).
Comprendido lo anterior, puede exponerse sobre terreno firme el concepto de auto-similaridad. Este concepto, también conocido como invarianza escalar para el caso continuo, significa que “(…) Nada importante se modifica en la física del estado crítico si cambiamos la escala de observación (…) Por ejemplo, a medida que disminuimos el aumento de un microscopio imaginario, tan pronto como ya no vemos los detalles microscópicos, la imagen del sistema físico permanece estadísticamente igual. Esta propiedad de invarianza escalar del estado crítico fue destacada y utilizada en la década de 1960 por Kadanoff, quien tuvo la intuición de que esta sería la clave para una descripción eficaz de los fenómenos críticos. De hecho, en 1970 varios físicos, en particular Wilson, propusieron una serie de métodos denominados “grupo de renormalización” que permitían el cálculo de comportamientos críticos extrayendo las consecuencias físicas de la invarianza de escala (…) Una de estas consecuencias es que los comportamientos críticos no dependen en gran medida en detalles físicos microscópicos que se “promedian” a gran escala. Sin embargo, dependen en gran medida de las características geométricas del sistema: la dimensión espacial y el número n de componentes del parámetro de orden.” (Lesne & Laguës, Scale Invariance. From Phase Transitions to Turbulence, 2012, págs. 30-31). Como señala, (Lesne, Renormalization Methods, 1998, pág. 2), las nociones de invariancia de escala y auto-similaridad, a través de la ruptura de la simetría, reemplazan la noción de homogeneidad y separación de escalas; junto a estas aparecen determinadas estructuras jerárquicas, correlacionando las distintas escalas de un sistema. Estos conceptos expresan en el mundo instrumental las nociones de propiedades universales y clases de universalidad.
Merece la pena destacar que este reemplazamiento de las nociones de homogeneidad y separación de escalas por una concepción más orgánica (la auto-similaridad, conceptual y matemáticamente, permite conectar las diferentes escalas de un sistema) y dinámica (puesto que las estructuras fractales son estructuras recurrentes) ocurre también en la mecánica cuántica a la luz de las últimas investigaciones en dos sentidos: por un lado, en la inseparabilidad teórica y matemática de las fuerzas fundamentales (matemáticamente hablando, por ejemplo, no es posible integrar la función que las contiene para estimar la contribución individual que cada una de ellas en la versión cuántica de lo que en física clásica se conoce como momento de fuerza -que es a lo que se refiere Hegel cuando habla de los omentos de fuerza de la palanca, como se vio antes-); por otro lado, en relación a la homogeneidad del universo. Ambas cuestiones se abordarán de forma conjunta en la sección relativa al principio monista de complementariedad.
Además, esta posición frente a la homogeneidad perfecta no sólo se encuentra en la economía política marxista y la mecánica cuántica, también en las ciencias médicas. Así, señala (Sharma & Vijay, 2009, pág. 110) que en la evolución del endotelio[3], que partió de un vertebrado ancestral hace unos 540-510 millones de años y tenía como objetivo optimizar la dinámica del flujo y la función de barrera (y/o para localizar las funciones inmunes y de coagulación) fue decisivo (y los autores señalan que hay que ser enfáticos en eso) el hecho de que la heterogeneidad endotelial evolucionó como una característica central del endotelio desde el principio, lo que según los mismos autores refleja su papel en la satisfacción de las diversas necesidades de los tejidos corporales.
Las nociones antes expuestas sobre renormalización están íntimamente relacionadas con el concepto de estructura fractal. Según (Mandelbrot, 1983, pág. 15), quien acuñó el concepto, una estructura fractal es un conjunto para el cual la dimensión de Hausdorff-Besicovitch excede estrictamente la dimensión topológica. ¿Qué es una dimensión de Hausdorff-Besicovitch?, ¿qué es una dimensión fractal en general? Como se señala en (FOLDOC, 2021), una dimensión fractal puede definirse, a grandes rasgos, como la magnitud resultante de operar el límite del cociente del cambio logarítmico en el tamaño del objeto y el cambio logarítmico en la escala de medición, cuando la escala de medición se acerca a cero. Las diferencias entre tipos de dimensión fractal provienen de las diferencias en lo que se entiende exactamente por “tamaño del objeto” y lo que se entiende por “escala de medición”, así como por los diferentes caminos que es posible tomar para obtener un número promedio de muchas partes diferentes de un objeto geométrico. Como puede observarse, las dimensiones fractales cuantifican la geometría estática de un objeto.
(Lesne, Renormalization Methods, 1998, pág. 270) señala que las propiedades fractales de una estructura natural se definen solo aproximadamente, localmente y en un dominio de escalas que está acotado por arriba y por abajo. Además, generalmente son solo propiedades estadísticas, que se vuelven observables y bien definidas solo promediando sobre diferentes subdivisiones, para las cantidades globales como N(a,r) [4],o sobre diferentes centros para las cantidades locales como n(a,r,x ̅_0 ).
Como señala (Lesne, Renormalization Methods, 1998, pág. 265) , el hecho que la teoría sobre fractales aborde la mayor parte de temas que aborda la teoría de renormalización obedece a que los principios físicos que subyacen a la presencia de estructuras fractales son los mismos que hacen que los métodos de renormalización funcionen. Las nociones esenciales de leyes de escala y de invariancia de escala, de auto-similaridad y de universalidad aparecen en ambas situaciones. ¿Qué es una estructura fractal entonces? Es una representación visual de las características que asegura que los métodos de renormalización son relevantes para el análisis del sistema en el que aparece; la expresión de su auto-similaridad guía la elección del formalismo (metodológico) y la construcción subsiguiente del operador de renormalización. Las singularidades locales[5] de las medidas[6] fractales (análisis fractal de medidas de conjuntos, usualmente de la medida de Borel en R^d) pueden describirse jerárquicamente por su espectro dimensional[7], determinadas por el análisis multifractal[8] o reveladas por análisis de renormalización antes delineado.
A través del concepto de isomorfismo, originalmente perteneciente a la topología algebraica y expuesto anteriormente, pueden vincularse teórica y empíricamente:
- La teoría matemática de los sistemas complejos[9] (representada en las estructuras fractales auto-similares).
- Los sistemas disipativos[10].
- Los sistemas mecánico-cuánticos[11].
(Vitiello, 2014, pág. 203) establece que en electrodinámica existe un intercambio mutuo de energía y momento entre el campo de materia y el campo electromagnético, la energía total y el momento se conservan y, a partir de ello, muestra que para un fenómeno de tipo electromagnético conformado por un campo magnético constante y un potencial escalar armónico[12], el sistema electrodinámico que modela dicha clase de fenómenos es isomórfico (topológicamente equivalente) a un sistema de osciladores armónicos amortiguados/amplificados[13]. Estos pueden describirse mediante estados coherentes[14] comprimidos[15] que a su vez son isomorfos a estructuras fractales auto-similares. Bajo dichas condiciones de campo magnético constante y potencial escalar armónico, la electrodinámica es, por tanto, isomorfa a estructuras fractales auto-similares (que presentan alguna propiedad universal o clases de universalidad para estructuras discontinuas) y estados coherentes comprimidos. A nivel cuántico, la disipación induce una geometría no-conmutativa[16] con el parámetro de compresión[17] jugando un papel relevante.
La ubicuidad[18] de los fractales en la Naturaleza y la relevancia de los estados coherentes y la interacción electromagnética apuntan, según Vitiello, hacia “una visión unificada e integrada de la Naturaleza”; por supuesto, esta unificación e integración a la que se refiere el autor citado es fundamentalmente instrumental, no de carácter general como la aquí planteada. Un bosquejo sobre las razones por las que esta vinculación de carácter tan general es posible de establecer alrededor del ruido rosa se presenta a continuación.
Como señala (Zhao, 2021, pág. 2), las propiedades de un sistema físico pueden revelarse analizando sus respuestas frente a perturbaciones externas. La forma en que las respuestas de un sistema se pueden clasificar en varias categorías principales. Aquí hay algunos ejemplos:
En su investigación, Zhao estudia una clase de sistemas complicados (difícil a nivel su operativización) en cuanto son particularmente extendidos espacialmente (como arena apilada) y cuyas respuestas a pequeñas perturbaciones no tienen una longitud o un tiempo característicos. Las respuestas contienen una serie de eventos en toda la duración y escala de tiempo. Su distribución de probabilidad frente al tiempo o la duración obedece la ley de potencia[19], lo que significa que no hay un valor esperado de tiempo o duración de las respuestas. En particular, la distribución de probabilidad de la energía liberada en los eventos tiene la forma 1/f^α ,con α≈1, por lo que se denomina ruido “similar a 1 /f”, en donde 1/f es el conocido ruido rosa[20], que es el hecho empírico-instrumental alrededor del cual Vitiello fundamenta su enfoque formal integral de la Naturaleza. ¿Por qué ocurre esto?
Señala (Zhao, 2021, págs. 6-7) que la autoorganización crítica (SOC, de ahora en adelante) fue sugerida por Per Bak, Chao Tan y Kurt Wiesenfeld en 1987. El título del artículo era Self-Organized Criticality: An Explanation of 1/f noise. En este artículo, Bak et al. argumentaron (como característica distintiva de los sistemas SOC) que cuando un sistema extendido espacialmente con muchos grados de libertad es alejado del equilibrio por una fuerza externa, el estado estacionario es un estado con correlación espacial de ley de potencia.
Así, un sistema dinámico clásico evolucionará espontáneamente a un “estado crítico” que carece de una longitud característica. También argumentaron que la falta de una longitud característica provocará la falta de un tiempo característico, lo que inducirá un comportamiento de ley de potencia en el espectro de frecuencias (el que se señaló antes). En palabras del autor, “El mensaje más emocionante de este artículo es que hay sistemas que no necesitan un ajuste de parámetros, sino que evolucionan espontáneamente hasta un punto crítico.” (p. 7).
La idea original de Bak et al. es que:
- El concepto de SOC es universal: los sistemas espacialmente extendidos en la naturaleza siempre están en el estado SOC.
- SOC causa el espectro de potencia similar a 1/f. Estas ideas físicas básicas no son difíciles de comprender cuando consideramos modelos simples como un montón de arena o el modelo de Burridge-Knopoff[21]. Sin embargo, después de 18 años de investigaciones teóricas y experimentales, la gente todavía no tiene una comprensión clara del SOC. Primero, los experimentos y las simulaciones por computadora han demostrado que muchos sistemas están en el estado SOC solo bajo ciertas condiciones, lo que significa que no está garantizada la universalidad de los SOC afirmada por Bak et al. En segundo lugar, hay algunos sistemas que tienen las “huellas digitales” de SOC, pero tienen ruido 1/f^2 en lugar de un ruido no trivial similar a 1/f. Sin embargo, la idea de Bak et al. es valiosa en el sentido de que proporcionó a las personas una forma de resolver tales problemas en un marco teórico preestablecido, aunque es evidente la necesidad de continuar sobre esa ruta teórica la investigación científica sobre los sistemas autoorganizados.
A la luz de lo planteado en esta sección, puede establecerse, en relación al automovimiento general de la Naturaleza y la sociedad, que los componentes (modelados mediante ecuaciones) de una totalidad de referencia (modelada mediante un sistema de ecuaciones) comparten una esencia común (i.e., que son isomórficos entre sí) que permite su combinación integro-diferencial[22] de forma armónica y coherente bajo una determinada estructura interna de naturaleza material (objetiva), no-lineal (la totalidad es diferente a la suma de sus partes) y dinámica (el tiempo transcurre y el sistema, así como sus componentes, cambia) generada por la interacción de tales componentes bajo determinadas condiciones iniciales[23]. La estructura interna del sistema (o totalidad de referencia) condiciona a los componentes que la generan bajo el mismo conjunto de leyes (pero generalizado, por lo que no es formalmente el mismo) que rigen la interacción entre las condiciones iniciales y las relaciones primigenias entre componentes que determinaron la gestación de dicha estructura interna[24], [25]. Estas leyes son: 1. Unidad y Lucha de los Contrarios (que implica emergencia[26] y autoorganización[27] -al menos de tipo SOC-), 2. Salto de lo Cuantitativo a lo Cualitativo (implica emergencia, bifurcación[28] y salto[29]), 3. Ley de la Negación de la Negación (que es la crisálida del proceso dinámico antes descrito, en donde lo que negó es negado).
Lo anteriormente expuesto no debe resultar extraño, no en cuanto la complejidad misma posee un significado intrínsecamente dialéctico. Como señala (Moreno Ortiz, 2005, pág. 4), desde un punto de vista etimológico, la palabra “complejidad” es de origen latino, proviene de complectere, cuya raíz plectere significa ‘trenzar, enlazar’. El agregado del prefijo com- añade el sentido de la dualidad de dos elementos opuestos que se enlazan íntimamente, pero sin anular su dualidad. De allí que complectere se utilice tanto para referirse al combate entre dos guerreros, como al entrelazamiento de dos amantes.
Finalmente, con miras a reforzar la exposición realizada en esta sección sobre el amplio espectro de aplicación de los sistemas complejos (específicamente en términos del amplio espectro de surgimiento que poseen), señala (Lesne, Renormalization Methods, 1998, pág. 140) que la aparición de la noción de caos determinista fue la señal para el abandono de la idea básica establecida por Lev Landau (1944), según la cual las leyes de evolución deterministas y regulares generan un comportamiento asintótico caótico sólo después de la desestabilización de un número infinito de grados de libertad. La insuficiencia de esta teoría se reveló cuando se obtuvo evidencia de que las características caóticas pueden ocurrir en sistemas con solo un pequeño número de grados de libertad, o incluso en sistemas de dimensión infinita que involucran solo un subespacio de dimensión finita del espacio de fase. Un ejemplo de este segundo caso lo da un sistema espacio-temporal cuya dinámica se puede extender a un número finito de funciones espacio-temporales dadas, lo que reduce el estudio al del sistema dinámico que describe la evolución puramente temporal del número finito de coeficientes que ocurren en esta descomposición. La posibilidad del caos no está excluida a priori, excepto para evoluciones continuas autónomas en la dimensión 1 o 2.
Referencias
FOLDOC. (29 de 12 de 2021). Obtenido de Free On-Line Dictionary of Computing: https://foldoc.org/fractal+dimension
Frolov, I. T. (1984). Diccionario de filosofía. (O. Razinkov, Trad.) Moscú: Editorial Progreso. Obtenido de http://filosofia.org/
Fundación Gustavo Bueno. (29 de 12 de 2021). Conexión universal entre los fenómenos. Obtenido de Diccionario soviético de filosofía: https://www.filosofia.org/enc/ros/conex.htm
Lesne, A. (1998). Renormalization Methods. Critical Phenomena, Chaos, Fractal Structures. West Sussex, Inglaterra: John Wiley lk Sons Ltd,.
Lesne, A., & Laguës, M. (2012). Scale Invariance. From Phase Transitions to Turbulence (Primera edición, traducida del francés (que cuenta con dos ediciones) ed.). New York: Springer.
Mandelbrot, B. B. (1983). The Fractal Geometry of Nature. New York: W. H. Freeman and Company.
Moreno Ortiz, J. C. (2005). El Significado y el Desafío de la Complejidad para la Bioética. Revista Latinoamericana de Bioética, 1-19. Obtenido de https://www.redalyc.org/pdf/1270/127020937001.pdf
Rosental, M. M., & Iudin, P. F. (1971). DICCIONARIO FILOSÓFICO. San Salvador: Tecolut.
Sharma, & Vijay. (2009). Deterministic Chaos and Fractal Complexity in the Dynamics of Cardiovascular Behavior: Perspectives on a New Frontier. The Open Cardiovascular Medicine Journal, 110-123. Obtenido de https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2757669/pdf/TOCMJ-3-110.pdf
Vitiello, G. (2014). On the Isomorphism between Dissipative Systems, Fractal Self-Similarity and Electrodynamics. Toward an Integrated Vision of Nature. systems, 203-206.
Zhao, X. (30 de Diciembre de 2021). 1/f like noise and self organized criticality. Obtenido de University of Illinois at Urbana Champaign: https://guava.physics.uiuc.edu/~nigel/courses/563/Essays_2005/PDF/Xin.pdf
[1] Los umbrales son valores definidos que determinan si un estadístico (magnitud generada a partir de un conjunto de datos reales mediante algún modelo matemático-computacional que provee algún tipo de información sobre los datos usados) está por encima, por debajo o dentro de un rango normal en su red; la normalidad lo determina el curso de las investigaciones en el campo en el que se está realizando. Los umbrales también se utilizan al mostrar colores en paneles. Todo lo que esté por debajo del umbral marginal es azul, todo lo que esté entre el umbral marginal y el crítico es amarillo y todo lo que esté por encima del umbral crítico es rojo. Los umbrales también se pueden utilizar como parte de los widgets de estado que se basan en el rendimiento o en una línea de base. Véase https://observerdocs.viavisolutions.com/index.html#page/Observer_Apex/understanding_thresholds.html. El umbral es también conocido como límite termodinámico (para problemas espaciales) o régimen asintótico (para problemas temporales), en los que la aparición de singularidades marca un fenómeno crítico; en el estudio de los sistemas inestables, James Clerk Maxwell en 1873 fue el primero en utilizar el término singularidad en su sentido más general: aquel en el que se refiere a contextos en los que cambios arbitrariamente pequeños, normalmente impredecibles, pueden conducir a efectos arbitrariamente grandes (véase https://en.wikipedia.org/wiki/Singularity_(system_theory)).
[2] Se les dice “críticos” en cuanto exceden el umbral.
[3] Tejido formado por una sola capa de células que tapiza interiormente el corazón y otras cavidades internas.
[4] Una región centrada en a y con longitud característica r, siendo ésta última una medida que define la escala del sistema, por ejemplo, el radio en una circunferencia. A nivel de sistemas, la longitud característica se define como el volumen del sistema dividido sobre su superficie.
[5] Singularidades (en el sentido de Maxwell) que aplican únicamente en una región del espacio de interés o de referencia.
[6] Como señala (Kolmogórov & Fomin, 1978, pág. 290), el concepto de medida de un conjunto constituye una generalización natural de los siguientes conceptos: 1) de la longitud de un segmento, 2) del área de una figura plana, 3) del volumen de una figura en el espacio, 4) del incremento de una función no-decreciente en el semisegmento [a,b), 5) de la integral de una función no negativa en una región lineal, plana, del espacio, etc.
Retomando lo planteado en (Hegel F. , 1968, págs. 49-55), considérese un conjunto A con a elementos. Se dice que A está equipado con una medida M si una cierta medida M(E) es asignada a alguno de los subconjuntos E de A. El conjunto A, junto con su medida M, conforman un espacio métrico. La medida de un conjunto es un número real que es positivo o nulo. Además, la medida asume que si dos conjuntos no se intersecan (no tienen elementos en común) la medida de su suma es igual a la suma de sus medidas (es decir, la medida es lineal) y que la existencia de medidas de dos conjuntos implica la existencia de la medida de un tercer conjunto (que es igual a la medida de ambos conjuntos). La medida de todo el espacio de referencia, en el contexto de las probabilidades, es igual a 1. Un sistema de medidas es contablemente cerrado si contiene todas las posibles sumas contables de sus elementos. Finalmente, una medida es normal si para los conjuntos equipados de medida la condición E=∑E_n, E_n⋅E_m = 0, n ≠ m (n = 1, 2, …) implica M(E)=∑M(E_n); el enunciado anterior establece que cuando los subconjuntos E de A tengan entre sí una relación lineal perfecta (i.e., se nulifican al multiplicarse escalarmente) implica que la aplicación de la medida M sobre dichos subconjuntos será un procedimiento lineal (aplicarla al todo es equivalente a aplicarla a la suma de las partes).
[7] El vector característico o autovector de una transformación lineal (por ejemplo, la transformación lineal de un sistema de ecuaciones) es un vector no-nulo que cambia a lo sumo por un factor de escala (valor característico o autovalor) cuando la transformación lineal en cuestión es aplicada sobre el objeto matemático del que se trate. La generalización conceptual y matemática del conjunto de autovectores de una transformación lineal es conocida en el análisis funcional como espectro. Este espectro puede descomponerse en tres tipos de espectro, que conforman las partes del espectro en general: 1) espectro puntual (consistente en todos los autovalores del operador lineal de un espacio de Banach -espacio lineal X en que la región de convergencia de una sucesión de Cauchy pertenece a dicho espacio-, que es el operador que realiza la transformación lineal), 2) espectro continuo [que es el conjunto de escalares que no son autovalores, pero que hacen que la región conformada por las diferencias entre el operador lineal T y λ (donde λ es el conjunto de escalares que hacen que su diferencia con T no tenga una función inversa acotada -bien delimitada- en X)] sean un subconjunto propio (subconjunto que es igual al conjunto que lo contiene) y denso (un determinado subconjunto E es denso en un espacio X si todo elemento de X o pertenece a E o está arbitrariamente cerca de algún miembro de E) del espacio X, 3) espectro residual (todos los escalares del espectro que no son escalares puntuales ni continuos).
[8] Como señala (Lesne, Renormalization Methods, 1998, pág. 271), una de las tres estructuras fractales más complejas es aquellas que pertenecen a la familia de fractales superpuestos, donde la dimensión fractal local D(x) (que significa que la dimensión fractal pertenece a una subregión del espacio de interés centrada en x) depende de x de manera muy irregular: para cada valor D, {x,D (x)= D} es un conjunto fractal muy lacunar [un conjunto fractal lacunar es aquel en que la distribución de sus componentes -resultante de su patrón de iteración- deja huecos (Lesne, Renormalization Methods, 1998, pág. 266), tal como se puede observar al realizar iteraciones con el conjunto de Cantor (Lesne, Renormalization Methods, 1998, pág. 267)]. Establecido lo anterior, el análisis multifractal se diseñó con el fin de describir para cada valor de D su distribución fractal entrelazada en el espacio x.
[9] Conocida usualmente como teoría matemática del caos.
[10] En general, una estructura disipativa es aquella estructura coherente (en términos de su lógica interna) y autoorganizada (es un proceso en el que alguna forma global de orden o coordinación surge de las interacciones locales entre los componentes de un sistema inicialmente desordenado) que aparece en sistemas que se encuentran fuera del equilibrio (a menudo lejos del mismo) en un entorno con el que realiza intercambios de algún tipo. En física, estos sistemas son termodinámicos y los intercambios son en términos de materia y energía. Ilya Prigogine obtuvo en 1977 el Nobel de Química por el descubrimiento de los sistemas disipativos.
[11] Sistemas mecánicos de naturaleza física en que la inclusión del cuanto de acción es relevante; sobre el cuanto de acción se hablará en la sección correspondiente al principio monista de complementariedad.
[12] El potencial escalar de un oscilador armónico. Un potencial escalar describe la situación en la que la diferencia en las energías potenciales de un objeto físico en dos posiciones diferentes depende solo de las posiciones, no de la trayectoria tomada por el objeto al viajar de una posición a la otra. Un ejemplo son las diferencias en la energía potencial del objeto físico a causa de la gravedad (el diferencial energético sólo depende de la posición del objeto).
[13] Un oscilador armónico es en mecánica clásica un sistema que, cuando se desplaza de su posición de equilibrio, experimenta una fuerza restauradora F proporcional al desplazamiento x; algo similar a la lógica de la mano invisible de Smith, que matematizó Walras (aunque bajo un espíritu esencialmente diferente, en relación a las posibles perturbaciones que pudiese sufrir el sistema económico de su posición de equilibrio (donde la oferta y la demanda se igualan, para el caso neoclásico). Un oscilador armónico amortiguado es aquel oscilador armónico bajo la acción de una fuerza de amortiguación (fricción) proporcional a la velocidad del sistema (la velocidad de su trayectoria o tasa de crecimiento). Un oscilador armónico es también un sistema en el que un objeto vibra (que es la forma que adopta el movimiento en los sistemas de sonido) con cierta amplitud y frecuencia; en un oscilador armónico simple, no existen fuerzas externas como la fricción o las fuerzas impulsoras que actúan sobre el objeto o, en su defecto, su efecto es despreciable; por lo tanto, la amplitud y la frecuencia siempre son las mismas. En una oscilación armónica amortiguada existen fuerzas (fricción) que actúan sobre el objeto, lo que tiene el efecto de que la amplitud (de la trayectoria) disminuya hasta que se detiene. En la vida real, la situación ideal de un oscilador armónico simple no existe. Esto significa que para mantener una oscilación debe aplicarse una fuerza impulsora o directora (conductora), de ahí el concepto de oscilador armónico dirigido.
[14] Un oscilador armónico cuántico es el análogo de un oscilador armónico clásico en la mecánica cuántica.
[15] Estado cuántico generalmente descrito mediante dos cantidades físicas mesurables no-conmutativas (véase la siguiente nota al pie) que tienen espectros continuos de autovalores.
[16] Una geometría no-conmutativa son espacios que presentan a nivel local (de una región de sí) estructuras algebraicas no-conmutativas, que son estructuras matemáticas en que uno de los operadores (símbolo que indica que se realiza una operación) binarios (porque la operación es efectuada sobre dos elementos) principales no cumple con la propiedad conmutativa al relacionar cualesquiera dos pares de elementos que se encuentren dentro de dicha localidad. Esto puede extenderse a estructuras usuales como la topología de un espacio o la norma del mismo y, conceptualmente, significa que la disipación, a nivel cuántico, induce una geometría en que el orden resulta relevante para una de las relaciones fundamentales que describen la operación de un determinado sistema en una región definida del espacio.
[17] Un parámetro es, conceptualmente hablando, una variable que sirve para identificar los elementos (usualmente funciones) que pertenecen a una determinada familia (que es una forma más general de conjunto). Comprendido esto, ¿qué es luz comprimida (del inglés squeezed light)? Señala (Lvovsky, Squeezed light, 2015, pág. 121) que la luz comprimida es un estado físico de la luz en el cual el ruido de un campo eléctrico en ciertas fases cae por debajo del estado de vacío (estado cuántico con la menor energía posible). Esto significa que, cuando se enciende la luz comprimida, se detecta menos ruido que en el caso que no hubiese ninguna luz. Esta característica aparentemente paradójica es una consecuencia directa de la naturaleza cuántica de la luz y no puede explicarse dentro de la mecánica clásica (bajo la lógica clásica es que resulta paradójica, aunque no lo sea). Comprendido lo anterior, resulta natural comprender el parámetro de comprensión lumínica como la variable que permite identificar como pertenecientes a una determinada familia de estados físicos a todas las funciones que modelan estados de luz comprimida. Como se señala en (Lvovsky, Squeezed light, 2015, pág. 128) y en (Lvovsky, Squeezed light, 2016, pág. 4), si un estado de comprensión cuántica de la luz se modela mediante la identidad S ̂(r)=exp[(ζa ̂-ζa ̂^(†2) )/2, en donde a ̂ es el operador de aniquilación y a ̂^(†2) es el operador de creación, entonces su parámetro de comprensión se expresa mediante ζ=re^iϕ, donde r es igual al logaritmo natural del factor de compresión r=ln(R), i es la coordenada rotacional (imaginaria) y ϕ son números reales (la fase ϕ determina el ángulo de la cuadratura que se comprime). Como señala (Drummond & Ficek, 2004, págs. 14-15), las propiedades estadístico-cuánticas de los estados coherentes están completamente determinadas por los valores medios de los operadores de posición y momento y sus varianzas. Complementariamente a lo anterior, señala que los estados comprimidos de radiación se producen en procesos no-lineales en los que un campo electromagnético “clásico” impulsa un medio no-lineal. En el medio no-lineal, se pueden generar pares de fotones correlacionados de la misma frecuencia. Un operador de compresión (una fuerza con las características necesarias para comprimir en la forma cuántica antes descrita la luz) puede aplicarse sobre estados coherentes y producir estados coherentes comprimidos (los estados coherentes de un oscilador armónico son aquellos que tienen la característica que sus valores esperados observables evolucionan de la misma forma en que lo hace un sistema dinámico clásico).
[18] La ubicuidad, como cualidad de ubicuo, es la característica de un ente de estar presente a un mismo tiempo en todas partes.
[19] Ley estadística que establece la relación funcional entre dos cantidades, donde un cambio relativo en una cantidad da como resultado un cambio relativo proporcional en la otra cantidad, con independencia del tamaño inicial de esas cantidades. Lo anterior equivale a afirmar que una cantidad varía como potencia de otra.
[20] Como señala (Mandelbrot, 1983, pág. 74), en física el ruido es sinónimo de posibilidad de fluctuación o error, independientemente de su origen y manifestación. Por otro lado, señala (Kiely, 2021, pág. 1) que el ruido 1/f es un ruido de baja frecuencia para el que la potencia del ruido es inversamente proporcional a la frecuencia. El ruido 1/f se ha observado no solo en la electrónica, sino también en la música, la biología e incluso la economía. Las fuentes del ruido 1/f todavía se debaten ampliamente y aún se están realizando muchas investigaciones en esta área.
[21] El modelo de Burridge-Knopoff es un sistema de ecuaciones diferenciales utilizado para modelar terremotos usando n puntos en línea recta, cada uno de masa m, que interactúan entre sí a través de resortes, y en el que todas las masas están sujetas a una fuerza que es proporcional a las distancias x_i(t) de las masas desde su posición de equilibrio y hasta una fuerza de fricción F(v), donde v es la velocidad.
[22] Es decir, que permite la acción de leyes integrales o leyes diferenciales según corresponda.
[23] Que inexorablemente, como indicaba Levins al validar el argumento de Engels, implica las condiciones iniciales no solo del sistema analizado en sí mismo sino también las del entorno.
[24] La estructura interna del sistema, lo que filosóficamente es esencia y matemáticamente es su topología.
[25] Así se establece que el todo, generado por las partes en el estado inicial, ulteriormente se vuelve más que las partes, adquiere independencia relativa de estas y las determina; por supuesto, las partes también influyen en el todo y lo modifican (aunque, evidentemente, la influencia no es tan condicionante en el sentido inverso, al menos no como caso general; las excepciones obedecen a condiciones concretas del momento de desarrollo del todo analizado y, en última instancia, la acción de las partes ha sido determinada de forma mediata -histórica, acumulativa- o bien, para el caso de los componentes genéticos del todo analizado -sus componentes históricamente primigenios-, las partes fueron condicionadas en el momento de formación del todo por las condiciones bajo las cuales tales partes se relacionaron de forma combinatoria (el contexto de formación del sistema estudiado), así como también cada una de estas partes es la cristalización de la dinámica acaecida en otros sistemas, en sus sistemas de referencia), de ahí que la independencia del todo respecto a estas sea relativa, no absoluta.
[26] Cualidad de los sistemas de transitar de una estructura simple hacia estructuras más complejas (sistemas en que la totalidad no puede ser reducida a la suma de sus partes).
[27] A grandes rasgos, puede definirse como aquel proceso en el que alguna forma de orden general surge de interacciones locales entre partes de un sistema inicialmente desordenado. La autoorganización crítica es una forma laxa de autoorganización (más general, en cuanto relaja los requerimientos).
[28] Como señala (Weisstein, 2021), una bifurcación es una separación de la estructura sistémica en dos ramas o partes. En sistemas dinámicos es una duplicación, triplicación, etc., que acompaña al inicio del caos. Una bifurcación representa una súbita apariencia de cambio cualitativo en relación a las soluciones del sistema no-lineal cuando algunos parámetros varían.
[29] En su sentido cuántico, un salto es la transición abrupta de un sistema cuántico de un estado a otro (o de un nivel de energía a otro); el término “salto” tiene como finalidad distinguirlo de los sistemas clásicos, en los cuales las transiciones son graduales. En un sentido dialéctico-materialista, un salto es un concepto más amplio que el de la mecánica cuántica y la mecánica clásica considerados aisladamente, que se asimila más al mecanismo evolutivo de Darwin-Gould: Charles Darwin estableció que la evolución por diferenciación y selección actuaba gradualmente, mientras que el biólogo marxista Stephen Jay Gould complementó esto afirmando que en algunos contextos podían ocurrir saltos abruptos (esto se expandirá más adelante cuando se analicen los equilibrios puntuados de Gould). Un salto, en su sentido dialéctico-materialista es, muy sintéticamente, la solución de la continuidad, la transición rápida y súbita de una cualidad a otra, gracias a la acumulación paulatina de los cambios cuantitativos insignificantes e imperceptibles (Fundación Gustavo Bueno, 2021).

ASPECTOS TEÓRICOS GENERALES SOBRE LA MATRIZ DE DISEÑO ESTRUCTURAL
ISADORE NABI
Como se señala en (Eppinger & Browning, 2012, págs. 2-4), la matriz de diseño estructural (DSM de ahora en adelante, por sus siglas en inglés) es una herramienta de modelado de redes que se utiliza para representar los elementos que componen un sistema y sus interacciones, destacando así la arquitectura del sistema (o estructura diseñada). DSM se adapta particularmente bien a aplicaciones en el desarrollo de sistemas de ingeniería complejos y, hasta la fecha, se ha utilizado principalmente en el área de gestión de ingeniería. Sin embargo, en el horizonte hay una gama mucho más amplia de aplicaciones de DSM que abordan problemas complejos en la gestión de la atención médica, los sistemas financieros, las políticas públicas, las ciencias naturales y los sistemas sociales. El DSM se representa como una matriz cuadrada N x N, que mapea las interacciones entre el conjunto de N elementos del sistema. DSM, una herramienta muy flexible, se ha utilizado para modelar muchos tipos de sistemas. Dependiendo del tipo de sistema que se modele, DSM puede representar varios tipos de arquitecturas. Por ejemplo, para modelar la arquitectura de un producto, los elementos de DSM serían los componentes del producto y las interacciones serían las interfaces entre los componentes (figura 1.1.a).

Para modelar la arquitectura de una organización, los elementos de DSM serían las personas o equipos de la organización, y las interacciones podrían ser comunicaciones entre las personas (figura l.1.b). Para modelar una arquitectura de proceso, los elementos del DSM serían las actividades en el proceso, y las interacciones serían los flujos de información y/o materiales entre ellos (figura l.l.c). Los modelos DSM de diferentes tipos de arquitecturas pueden incluso combinarse para representar cómo se relacionan los diferentes dominios del sistema dentro de un sistema más grande (figura l.l.d). Por tanto, el DSM es una herramienta genérica para modelar cualquier tipo de arquitectura de sistema. En comparación con otros métodos de modelado de redes, el principal beneficio de DSM es la naturaleza gráfica del formato de visualización de la matriz. La matriz proporciona una representación muy compacta, fácilmente escalable y legible de forma intuitiva de la arquitectura de un sistema. La figura l.3.a muestra un modelo DSM simple de un sistema con ocho elementos, junto con su representación gráfica dirigida equivalente (dígrafo) en la figura 1.3.b.

En comparación con otros métodos de modelado de redes, el principal beneficio de DSM es la naturaleza gráfica del formato de visualización de la matriz. La matriz proporciona una representación muy compacta, fácilmente escalable y legible de forma intuitiva de la arquitectura de un sistema. La figura l.3.a muestra un modelo DSM simple de un sistema con ocho elementos, junto con su representación equivalente como grafo dirigido (dígrafo) en la figura 1.3.b. En los estudios iniciales de DSM, a muchos les resulta fácil pensar que las celdas a lo largo de la diagonal de la matriz representan los elementos del sistema, análogos a los nodos en el modelo de dígrafo; sin embargo, es necesario mencionar que, para mantener el diagrama de matriz compacto, los nombres completos de los elementos a menudo se enumeran a la izquierda de las filas (y a veces también encima de las columnas) en lugar de en las celdas diagonales. También es fácil pensar que cada celda sobre la diagonal principal de la matriz puede tener entradas que ingresan desde sus lados izquierdo y derecho y salidas que salen desde arriba y abajo. Las fuentes y destinos de estas interacciones de entrada y salida se identifican mediante marcas en las celdas fuera de la diagonal (en la figura anterior expresadas con una letra X) análogas a los arcos direccionales en el modelo de dígrafo. Examinar cualquier fila de la matriz revela todas las entradas del elemento en esa fila (que son salidas de otros elementos).
Si se observa hacia abajo, cualquier columna de la matriz muestra todas las salidas del elemento en esa columna (que se convierten en entradas para otros elementos). En el ejemplo simple de DSM que se muestra en la figura 1.3.a, los ocho elementos del sistema están etiquetados de la A a la H, y hemos etiquetado tanto las filas como las columnas de la A a la H en consecuencia. Al leer la fila D, por ejemplo, vemos que el elemento D tiene entradas de los elementos A, B y F, representados por las marcas X en la fila D, columnas A, B y F. Al leer la columna F, vemos ese elemento F tiene salidas que van a los elementos B y D. Por lo tanto, la marca en la celda fuera de la diagonal [D, F] representa una interacción que es tanto una entrada como una salida dependiendo de si se toma la perspectiva de su proveedor (columna F) o su receptor (fila D). Es importante notar que muchos recursos de DSM usan la convención opuesta, la transposición de la matriz, con las entradas de un elemento mostradas en su columna y sus salidas mostradas en su fila. Las dos convenciones transmiten la misma información, y ambas se utilizan ampliamente debido a las diversas raíces de las herramientas basadas en matrices para los sistemas de modelado.
En este sentido, como se verifica en (IBM, 2021), en diversos escenarios aplicados puede existir más de una función discriminante[1], como se muestra a continuación.

En general, como se verifica en (Zhao & Maclean, 2000, pág. 841), el análisis discriminante canónico (CDA, por nombre en inglés) es una técnica multivariante que se puede utilizar para determinar las relaciones entre una variable categórica y un grupo de variables independientes. Uno de los propósitos principales de CDA es separar clases (poblaciones) en un espacio discriminante de menor dimensión. En este contexto es que cuando existe más de una función discriminante (cada una de estas puede verse como un modelo de regresión lineal), un asterisco (*) como en este caso (para el caso del programa SaaS) u otro símbolo denotará la mayor correlación absoluta de cada variable con una de las funciones canónicas. Dentro de cada función, estas variables marcadas se ordenan por el tamaño de la correlación. Para el caso de la tabla presentada en la figura anterior, su lectura debe realizarse de la siguiente manera:
- “Nivel educativo” está más fuertemente correlacionado con la primera función y es la única variable más fuertemente correlacionada con esta función.
- Años con empresa actual, “Edad” en años, “Ingresos del hogar” en miles, “Años” en la dirección actual, “Retirado” y “Sexo” están más fuertemente correlacionados con la segunda función, aunque “Sexo” y “Jubilación” están más débilmente correlacionados que los otros. Las demás variables marcan esta función como función de “estabilidad”.
- “Número de personas en el hogar” y “Estado civil” están más fuertemente correlacionados con la tercera función discriminante, pero esta es una función sin utilidad, así que estos predictores son prácticamente inútiles.
REFERENCIAS
de la Fuente Fernández, S. (s.f.). Análisis Discriminante. Obtenido de Universidad Autónoma de Madrid: https://www.estadistica.net/Master-Econometria/Analisis_Discriminante.pdf
Eppinger, S. D., & Browning, T. R. (2012). Design Structure Matrix Methods and Applications. Cambridge, Massachusetts: MIT Press.
IBM. (2021). Análisis discriminante. Obtenido de SPSS Statistics: https://www.ibm.com/docs/es/spss-statistics/version-missing?topic=features-discriminant-analysis
IBM. (2021). Matriz de estructura. Obtenido de SaaS: https://www.ibm.com/docs/es/spss-modeler/SaaS?topic=customers-structure-matrix
Wikipedia. (23 de Junio de 2021). Linear classifier. Obtenido de Statistical classification: https://en.wikipedia.org/wiki/Linear_classifier
Zhao, G., & Maclean, A. L. (2000). A Comparison of Canonical Discriminant Analysis and Principal Component Analysis for Spectral Transformation. Photogrammetric Engineering & Remote Sensing, 841-847. Obtenido de https://www.asprs.org/wp-content/uploads/pers/2000journal/july/2000_jul_841-847.pdf
[1] Como se verifica en (de la Fuente Fernández, pág. 1), un discriminante es cada una de las variables independientes con las que se cuenta. Además, como se verifica en (IBM, 2021), una función discriminante es aquella que, mediante las diferentes combinaciones lineales de las variables predictoras, busca realizar la mejor discriminación posible entre los grupos. No debe olvidarse que, como se señala en (Wikipedia, 2021), En el campo del aprendizaje automático, el objetivo de la clasificación estadística es utilizar las características de un objeto para identificar a qué clase (o grupo) pertenece.
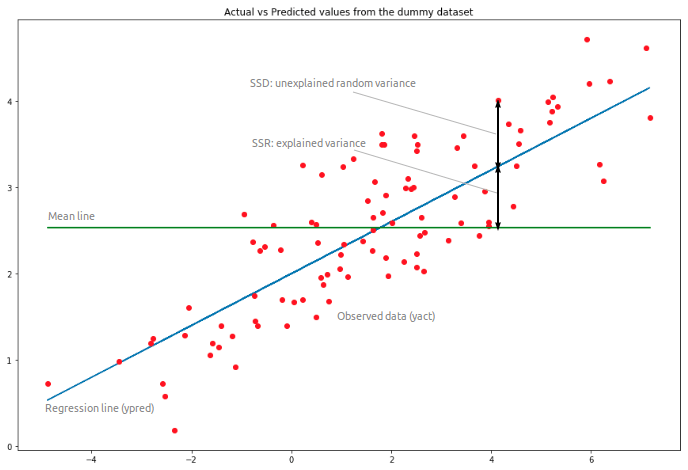
SUPUESTOS DEL MODELO CLÁSICO DE REGRESIÓN LINEAL Y DE LOS MODELOS LINEALES GENERALIZADOS
isadore nabi

REFERENCIAS
Banerjee, A. (29 de Octubre de 2019). Intuition behind model fitting: Overfitting v/s Underfitting. Obtenido de Towards Data Science: https://towardsdatascience.com/intuition-behind-model-fitting-overfitting-v-s-underfitting-d308c21655c7
Bhuptani, R. (13 de Julio de 2020). Quora. Obtenido de What is the difference between linear regression and least squares?: https://www.quora.com/What-is-the-difference-between-linear-regression-and-least-squares
Cross Validated. (23 de Marzo de 2018). Will log transformation always mitigate heteroskedasticity? Obtenido de StackExchange: https://stats.stackexchange.com/questions/336315/will-log-transformation-always-mitigate-heteroskedasticity
Greene, W. (2012). Econometric Analysis (Séptima ed.). Harlow, Essex, England: Pearson Education Limited.
Guanga, A. (11 de Octubre de 2018). Machine Learning: Bias VS. Variance. Obtenido de Becoming Human: Artificial Intelligence Magazine: https://becominghuman.ai/machine-learning-bias-vs-variance-641f924e6c57
Gujarati, D., & Porter, D. (8 de Julio de 2010). Econometría (Quinta ed.). México, D.F.: McGrawHill Educación. Obtenido de Homocedasticidad.
McCullagh, P., & Nelder, J. A. (1989). Generalized Linear Models (Segunda ed.). London: Chapman and Hall.
MIT Computer Science & Artificial Intelligence Lab. (6 de Mayo de 2021). Solving over- and under-determined sets of equations. Obtenido de Articles: http://people.csail.mit.edu/bkph/articles/Pseudo_Inverse.pdf
Nabi, I. (27 de Agosto de 2021). MODELOS LINEALES GENERALIZADOS. Obtenido de El Blog de Isadore Nabi: https://marxistphilosophyofscience.com/wp-content/uploads/2021/08/modelos-lineales-generalizados-isadore-nabi.pdf
Penn State University, Eberly College of Science. (2018). 10.4 – Multicollinearity. Obtenido de Lesson 10: Regression Pitfalls: https://online.stat.psu.edu/stat462/node/177/
Penn State University, Eberly College of Science. (24 de Mayo de 2021). Introduction to Generalized Linear Models. Obtenido de Analysis of Discrete Data: https://online.stat.psu.edu/stat504/lesson/6/6.1
Perezgonzalez, J. D. (3 de Marzo de 2015). Fisher, Neyman-Pearson or NHST? A tutorial for teaching data testing. frontiers in PSYCHOLOGY, VI(223), 1-11.
ResearchGate. (10 de Noviembre de 2014). How it can be possible to fit the four-parameter Fedlund model by only 3 PSD points? Obtenido de https://www.researchgate.net/post/How_it_can_be_possible_to_fit_the_four-parameter_Fedlund_model_by_only_3_PSD_points
ResearchGate. (28 de Septiembre de 2019). s there a rule for how many parameters I can fit to a model, depending on the number of data points I use for the fitting? Obtenido de https://www.researchgate.net/post/Is-there-a-rule-for-how-many-parameters-I-can-fit-to-a-model-depending-on-the-number-of-data-points-I-use-for-the-fitting
Salmerón Gómez, R., Blanco Izquierdo, V., & García García, C. (2016). Micronumerosidad aproximada y regresión lineal múltiple. Anales de ASEPUMA(24), 1-17. Obtenido de https://dialnet.unirioja.es/descarga/articulo/6004585.pdf
Simon Fraser University. (30 de Septiembre de 2011). THE CLASSICAL MODEL. Obtenido de http://www.sfu.ca/~dsignori/buec333/lecture%2010.pdf
StackExchange Cross Validated. (2 de Febrero de 2017). “Least Squares” and “Linear Regression”, are they synonyms? Obtenido de What is the difference between least squares and linear regression? Is it the same thing?: https://stats.stackexchange.com/questions/259525/least-squares-and-linear-regression-are-they-synonyms
Wikipedia. (18 de Marzo de 2021). Overdetermined system. Obtenido de Partial Differential Equations: https://en.wikipedia.org/wiki/Overdetermined_system
Zhao, J. (9 de Noviembre de 2017). More features than data points in linear regression? Obtenido de Medium: https://medium.com/@jennifer.zzz/more-features-than-data-points-in-linear-regression-5bcabba6883e
FUNDAMENTOS GENERALES DE LA PROGRAMACIÓN EN R STUDIO: UN ENFOQUE ESTADÍSTICO-MATEMÁTICO






INTRODUCCIÓN A LOS ENSAYOS CLÍNICOS DESDE LA TEORÍA ESTADÍSTICA Y RSTUDIO: ASOCIACIÓN Y CORRELACIÓN DE PEARSON, SPEARMAN Y KENDALL
isadore NABI
### DISTRIBUCIÓN CHI-CUADRADO
###ORÍGENES HISTÓRICOS Y GENERALIDADES: https://marxianstatistics.com/2021/09/10/generalidades-sobre-la-prueba-chi-cuadrado/
###En su forma general, la distribución Chi-Cuadrado es una suma de los cuadrados de variables aleatorias N(media=0, varianza=1), véase https://mathworld.wolfram.com/Chi-SquaredDistribution.html.
###Se utiliza para describir la distribución de una suma de variables aleatorias al cuadrado. También se utiliza para probar la bondad de ajuste de una distribución de datos, si las series de datos son independientes y para estimar las confianzas que rodean la varianza y la desviación estándar de una variable aleatoria de una distribución normal.
### COEFICIENTES DE CORRELACIÓN
###Coeficiente de Correlación de Pearson (prueba paramétrica): https://statistics.laerd.com/statistical-guides/pearson-correlation-coefficient-statistical-guide.php, https://www.wikiwand.com/en/Pearson_correlation_coefficient.
###Coeficiente de Correlación de Spearman (prueba no-paramétrica): https://statistics.laerd.com/statistical-guides/spearmans-rank-order-correlation-statistical-guide.php, https://www.wikiwand.com/en/Spearman%27s_rank_correlation_coefficient, https://www.statstutor.ac.uk/resources/uploaded/spearmans.pdf.
###Coeficiente de Correlación de Kendall (prueba no-paramétrica): https://www.statisticshowto.com/kendalls-tau/, https://towardsdatascience.com/kendall-rank-correlation-explained-dee01d99c535, https://personal.utdallas.edu/~herve/Abdi-KendallCorrelation2007-pretty.pdf, https://www.wikiwand.com/en/Kendall_rank_correlation_coefficient.
####Como se verifica en su forma más general [véase Jeremy M. G. Taylor, Kendall’s and Spearman’s Correlation Coefficient in the Presence of a Blocking Variable, (Biometrics, Vol. 43, No. 2 (Jun., 1987), pp.409-416), p. 409], en presencia de “empates”, conocidos también como “observaciones vinculadas” (del inglés “ties”, que, como se verifica en http://www.statistics4u.com/fundstat_eng/dd_ties.html, significa en el contexto de las estadísticas de clasificación de orden -rank order statistics- la existencia de dos o más observaciones que tienen el mismo valor, por lo que imposibilita la asignación de números de rango únicos), es preferible utilizar el coeficiente de correlación de Spearman rho porque su varianza posee una forma más simple (relacionado con el costo computacional, puesto que la investigación de Jeremy Taylor emplea como herramienta de estadística experimental la metodología Monte Carlo, lo que puede verificarse en https://pdodds.w3.uvm.edu/files/papers/others/1987/taylor1987a.pdf).
### RIESGO RELATIVO
####Como se verifica en https://www.wikiwand.com/en/Odds_ratio, el riesgo relativo (diferente a la razón éxito/fracaso y a la razón de momios) es la proporción de éxito de un evento (o de fracaso) en términos del total de ocurrencias (éxitos más fracasos).
### RAZÓN ÉXITO/FRACASO
####Es el cociente entre el número de veces que ocurre un evento y el número de veces en que no ocurre.
####INTERPRETACIÓN: Para interpretar la razón de ataque/no ataque de forma más intuitiva se debe multiplicar dicha razón Ψ (psi) por el número de decenas necesarias Ξ (Xi) para que la razón tenga un dígito d^*∈N a la izquierda del “punto decimal” (en este caso de aplicación hipotético Ξ=1000), resultando así un escalar real υ=Ψ*Ξ (donde υ es la letra griega ípsilon) con parte entera que se interpreta como “Por cada Ξ elementos de la población de referencia bajo la condición especificada (en este caso, que tomó aspirina o que tomó un placebo) estará presente la característica (u ocurrirá el evento, según sea el caso) en (d^*+h) ocasiones, en donde h es el infinitesimal a la derecha del punto decimal (llamado así porque separa no sólo los enteros de los infinitesimales, sino que a su derecha se encuentra la casilla correspondiente justamente a algún número decimal).
### RAZÓN DE MOMIOS
####DEFÍNICIÓN: Es una medida utilizada en estudios epidemiológicos transversales y de casos y controles, así como en los metaanálisis. En términos formales, se define como la posibilidad que una condición de salud o enfermedad se presente en un grupo de población frente al riesgo que ocurra en otro. En epidemiología, la comparación suele realizarse entre grupos humanos que presentan condiciones de vida similares, con la diferencia que uno se encuentra expuesto a un factor de riesgo (mi) mientras que el otro carece de esta característica (mo). Por lo tanto, la razón de momios o de posibilidades es una medida de tamaño de efecto.
####Nótese que es un concepto, evidentemente, de naturaleza frecuentista.
####La razón de momios es el cociente entre las razones de ocurrencia/no-ocurrencia de los tratamientos experimentales estudiados (una razón por cada uno de los dos tratamientos experimentales sujetos de comparación).
### TAMAÑO DEL EFECTO
####Defínase tamaño del efecto como cualquier medida realizada sobre algún conjunto de características (que puede ser de un elemento) relativas a cualquier fenómeno, que es utilizada para abordar una pregunta de interés, según (Kelly y Preacher 2012, 140). Tal y como ellos señalan, la definición es más que una combinación de “efecto” y “tamaño” porque depende explícitamente de la pregunta de investigación que se aborde. Ello significa que lo que separa a un tamaño de efecto de un estadístico de prueba (o estimador) es la orientación de su uso, si responde una pregunta de investigación en específico entonces el estadístico (o parámetro) se convierte en un “tamaño de efecto” y si sólo es parte de un proceso global de predicción entonces es un estadístico (o parámetro) a secas, i.e., su distinción o, expresado en otros términos, la identificación de cuándo un estadístico (o parámetro) se convierte en un tamaño de efecto, es una cuestión puramente epistemológica, no matemática. Lo anterior simplemente implica que, dependiendo del tipo de pregunta que se desee responder el investigador, un estadístico (o parámetro) será un tamaño de efecto o simplemente un estadístico (o parámetro) sin más.
setwd(“C:/Users/User/Desktop/Carpeta de Estudio/Maestría Profesional en Estadística/Semestre II-2021/Métodos, Regresión y Diseño de Experimentos/2/Laboratorios/Laboratorio 2”)
## ESTIMAR EL COEFICIENTE DE CORRELACIÓN DE PEARSON ENTRE TEMPERATURA Y PORCENTAJE DE CONVERSIÓN
###CÁLCULO MANUAL DE LA COVARIANZA
prom.temp = mean(temperatura)
prom.conversion = mean(porcentaje.conversion)
sd.temp = sd(temperatura)
sd.conversion = sd(porcentaje.conversion)
n = nrow(vinilacion)
covarianza = sum((temperatura-prom.temp)*(porcentaje.conversion-prom.conversion))/(n-1)
covarianza
###La covarianza es una medida para indicar el grado en el que dos variables aleatorias cambian en conjunto (véase https://www.mygreatlearning.com/blog/covariance-vs-correlation/#differencebetweencorrelationandcovariance).
###CÁLCULO DE LA COVARIANZA DE FORMA AUTOMATIZADA
cov(temperatura,porcentaje.conversion)
###CÁLCULO MANUAL DEL COEFICIENTE DE CORRELACIÓN DE PEARSON
###Véase https://www.wikiwand.com/en/Pearson_correlation_coefficient (9 de septiembre de 2021).
coef.correlacion = covarianza/(sd.temp*sd.conversion)
coef.correlacion
###CÁLCULO AUTOMATIZADO DEL COEFICIENTE DE CORRELACIÓN DE PEARSON
cor(temperatura,porcentaje.conversion) ###Salvo que se especifique lo contrario (como puede verificarse en la librería de R), el coeficiente de correlación calculado por defecto será el de Pearson, sin embargo, se puede calcular también el coeficiente de Kendall (escribiendo “kendall” en la casilla “method” de la sintaxis “cor”) o el de Spearman (escribiendo “spearman” en la casilla “method” de la sintaxis “cor”).
cor(presion,porcentaje.conversion)
###VÍNCULO, SIMILITUDES Y DIFERENCIAS ENTRE CORRELACIÓN Y COVARIANZA
###El coeficiente de correlación está íntimamente vinculado con la covarianza. La covarianza es una medida de correlación y el coeficiente de correlación es también una forma de medir la correlación (que difiere según sea de Pearson, Kendall o Spearman).
###La covarianza indica la dirección de la relación lineal entre variables, mientras que el coeficiente de correlación mide no sólo la dirección sino además la fuerza de esa relación lineal entre variables.
###La covarianza puede ir de menos infinito a más infinito, mientras que el coeficiente de correlación oscila entre -1 y 1.
###La covarianza se ve afectada por los cambios de escala: si todos los valores de una variable se multiplican por una constante y todos los valores de otra variable se multiplican por una constante similar o diferente, entonces se cambia la covarianza. La correlación no se ve influenciada por el cambio de escala.
###La covarianza asume las unidades del producto de las unidades de las dos variables. La correlación es adimensional, es decir, es una medida libre de unidades de la relación entre variables.
###La covarianza de dos variables dependientes mide cuánto en cantidad real (es decir, cm, kg, litros) en promedio covarían. La correlación de dos variables dependientes mide la proporción de cuánto varían en promedio estas variables entre sí.
###La covarianza es cero en el caso de variables independientes (si una variable se mueve y la otra no) porque entonces las variables no necesariamente se mueven juntas (por el supuesto de ortogonalidad entre los vectores, que expresa geométricamente su independencia lineal). Los movimientos independientes no contribuyen a la correlación total. Por tanto, las variables completamente independientes tienen una correlación cero.
## CREAR UNA MATRIZ DE CORRELACIONES DE PEARSON Y DE SPEARMAN
####La vinilación de los glucósidos se presenta cuando se les agrega acetileno a alta presión y alta temperatura, en presencia de una base para producir éteres de monovinil.
###Los productos de monovinil éter son útiles en varios procesos industriales de síntesis.
###Interesa determinar qué condiciones producen una conversión máxima de metil glucósidos para diversos isómeros de monovinil.
cor(vinilacion) ###Pearson
cor(vinilacion, method=”spearman”) ###Spearman
## CREAR UNA MATRIZ DE VARIANZAS Y COVARIANZAS (LOCALIZADAS ESTAS ÚLTIMAS EN LA DIAGONAL PRINCIPAL DE LA MATRIZ)
cov(vinilacion)
## GENERAR GRÁFICOS DE DISPERSIÓN
plot(temperatura,porcentaje.conversion)
plot(porcentaje.conversion~temperatura)
mod = lm(porcentaje.conversion~temperatura)
abline(mod,col=2)
###La sintaxis “lm” es usada para realizar ajuste de modelos lineales (es decir, ajustar un conjunto de datos a la curva dibujada por un modelo lineal -i.e., una línea recta-, lo cual -si es estadísticamente robusto- implica validar que el conjunto de datos en cuestión posee un patrón de comportamiento geométrico lineal).
###La sintaxis “lm” puede utilizar para el ajuste el método de los mínimos cuadrados ponderados o el método de mínimos cuadrados ordinarios, en función de si la opción “weights” se llena con un vector numérico o con “NULL”, respectivamente).
### La casilla “weights” de la sintaxis “lm” expresa las ponderaciones a utilizar para realizar el proceso de ajuste (si las ponderaciones son iguales para todas las observaciones, entonces el método de mínimos cuadrados ponderados se transforma en el método de mínimos cuadrados ordinarios). Estas ponderaciones son, en términos computacionales, aquellas que minimizan la suma ponderada de los errores al cuadrado.
###Las ponderaciones no nulas pueden user usadas para indicar diferentes varianzas (con los valores de las ponderaciones siendo inversamente proporcionales a la varianza); o, equivalentemente, cuando los elementos del vector de ponderaciones son enteros positivos w_i, en donde cada respuesta y_i es la media de las w_j unidades observacionales ponderadas (incluyendo el caso de que hay w_i observaciones iguales a y_i y los datos se han resumido).
###Sin embargo, en el último caso, observe que no se utiliza la variación dentro del grupo. Por lo tanto, la estimación sigma y los grados de libertad residuales pueden ser subóptimos; en el caso de pesos de replicación, incluso incorrecto. Por lo tanto, los errores estándar y las tablas de análisis de varianza deben tratarse con cuidado.
###La estimación sigma se refiere a la sintaxis “sigma” que estima la desviación estándar de los errores (véase https://stat.ethz.ch/R-manual/R-devel/library/stats/html/sigma.html).
###Si la variable de respuesta (o dependiente) es una matriz, un modelo lineal se ajusta por separado mediante mínimos cuadrados a cada columna de la matriz.
###Cabe mencionar que “formula” (la primera entrada de la sintaxis “lm”) tiene un término de intersección implícito (recuérdese que toda ecuación de regresión tiene un intercepto B_0, que puede ser nulo). Para eliminar dicho término, debe usarse y ~ x – 1 o y ~ 0 + x.
plot(presion~porcentaje.conversion)
mod = lm(presion~porcentaje.conversion) ###Ajuste a la recta antes mencionado y guardado bajo el nombre “mod”.
abline(mod,col=2) ###Es crear una línea color rojo (col=2) en la gráfica generada (con la función “mod”)
## REALIZAR PRUEBA DE HIPÓTESIS PARA EL COEFICIENTE DE CORRELACIÓN
###Véase https://opentextbc.ca/introstatopenstax/chapter/testing-the-significance-of-the-correlation-coefficient/, https://online.stat.psu.edu/stat501/lesson/1/1.9,
###Para estar casi seguros (en relación al concepto de convergencia) Para asegurar que existe al menos una leve correlación entre dos variables (X,Y) se tiene que probar que el coeficiente de correlación poblacional (r) no es nulo.
###Para que la prueba de hipótesis tenga validez se debe verificar que la distribución de Y para cada X es normal y que sus valores han sido seleccionados aleatoriamente.
###Si se rechaza la hipótesis nula, no se asegura que haya una correlación muy alta.
###Si el valor p es menor que el nivel de significancia se rechaza la Ho de que el coeficiente de correlación entre Y y X es cero en términos de determinado nivel de significancia estadística.
###Evaluar la significancia estadística de un coeficiente de correlación puede contribuir a validar o refutar una investigación donde este se haya utilizado (siempre que se cuenten con los datos empleados en la investigación), por ejemplo, en el uso de modelos lineales de predicción.
###Se puede utilizar la distribución t con n-2 grados de libertad para probar la hipótesis.
###Como se observará a continuación, además de la forma estándar, también es posible calcular t como la diferencia entre el coeficiente de correlación.
###Si la probabilidad asociada a la hipótesis nula es casi cero, puede afirmarse a un nivel de confianza determinado de que la correlación es altamente significativa en términos estadísticos.
###FORMA MANUAL
ee = sqrt((1-coef.correlacion^2)/(n-2))
t.calculado = (coef.correlacion-0)/ee ###Aquí parece implicarse que el valor t puede calcularse como el cociente entre el coeficiente de correlación muestral menos el coeficiente de correlación poblacional sobre el error estándar de la media.
2*(1-pt(t.calculado,n-2))
###FORMA AUTOMATIZADA
cor.test(temperatura,porcentaje.conversion) ###El valor del coeficiente de correlación que se ha estipulado (que es cero) debe encontrarse dentro del intervalo de confianza al nivel de probabilidad pertinente para aceptar Ho y, caso contrario, rechazarla.
cor.test(temperatura,presion)
###Como se señala en https://marxianstatistics.com/2021/09/05/analisis-teorico-de-la-funcion-cuantil-en-r-studio/, calcula el valor umbral x por debajo del cual se encuentran las observaciones sobre el fenómeno de estudio en una proporción P de las ocasiones (nótese aquí una definición frecuentista de probabilidad), incluyendo el umbral en cuestión.
qt(0.975,6)
### EJEMPLO DE APROXIMACIÓN COMPUTACIONAL DE LA DISTRIBUCIÓN t DE STUDENT A LA DISTRIBUCIÓN NORMAL
###El intervalo de confianza se calcula realizando la transformación-z de Fisher (tanto con la función automatizada de R como con la función personalizada elaborada) como a nivel teórico), la cual se utiliza porque cuando la transformación se aplica al coeficiente de correlación muestral, la distribución muestral de la variable resultante es aproximadamente normal, lo que implica que posee una varianza que es estable sobre diferentes valores de la correlación verdadera subyacente (puede ampliarse más en https://en.wikipedia.org/wiki/Fisher_transformation).
coef.correlacion+c(-1,1)*qt(0.975,6)*ee ###Intervalo de confianza para el estadístico de prueba sujeto de hipótesis (el coeficiente de correlación, en este caso) distribuido como una distribución t de Student.
coef.correlacion+c(-1,1)*qnorm(0.975)*ee ###Intervalo de confianza para el estadístico de prueba sujeto de hipótesis (el coeficiente de correlación, en este caso) distribuido normalmente.
## CASO DE APLICACIÓN HIPOTÉTICO
###En un estudio sobre el metabolismo de una especie salvaje, un biólogo obtuvo índices de actividad y datos sobre tasas metabólicas para 20 animales observados en cautiverio.
rm(list=ls()) ###Remover todos los objetos de la lista
actividad <- read.csv(“actividad.csv”, sep = “,”, dec=”.”, header = T)
attach(actividad)
n=nrow(actividad)
str(actividad)####”str” es para ver qué tipo de dato es cada variable.
plot(Indice.actividad,Tasa.metabolica)
###Coeficiente de Correlación de Pearson
cor(Indice.actividad,Tasa.metabolica, method=”pearson”)
###Se rechaza la hipótesis nula de que la correlación de Pearson es 0.
###Coeficiente de correlación de Spearman
(corr = cor(Indice.actividad,Tasa.metabolica, method=”spearman”))
(t.s=corr*(sqrt((n-2)/(1-(corr^2)))))
(gl=n-2)
(1-pt(t.s,gl))*2
###Se rechaza la hipótesis nula de que la correlación de Spearman es 0.
###NOTA ADICIONAL:
###Ambas oscilan entre -1 y 1. El signo negativo denota la relacion inversa entre ambas. La correlacion de Pearson mide la relación lineal entre dos variables (correlacion 0 es independencia lineal, que los vectores son ortogonales). La correlación de Pearson es para variables numérica de razón y tiene el supuesto de normalidad en la distribución de los valores de los datos. Cuando los supuestos son altamente violados, lo mejor es usar una medida de correlación no-paramétrica, específicamente el coeficiente de Spearman. Sobre el coeficiente de Spearman se puede decir lo mismo en relación a la asociación. Así, valores de 0 indican correlación 0, pero no asegura que por ser cero las variables sean independientes (no es concluyente).
### TABLAS DE CONTINGENCIA Y PRUEBA DE INDEPENDENCIA
###Una tabla de contingencia es un arreglo para representar simultáneamente las cantidades de individuos y sus porcentajes que se presentan en cada celda al cruzar dos variables categóricas.
###En algunos casos una de las variables puede funcionar como respuesta y la otra como factor, pero en otros casos sólo interesa la relación entre ambas sin intentar explicar la dirección de la relación.
###CASO DE APLICACIÓN HIPOTÉTICO
###Un estudio de ensayos clínicos trataba de probar si la ingesta regular de aspirina reduce la mortalidad por enfermedades cardiovasculares. Los participantes en el estudio tomaron una aspirina o un placebo cada dos días. El estudio se hizo de tal forma que nadie sabía qué pastilla estaba tomando. La respuesta es que si presenta o no ataque cardiaco (2 niveles),
rm(list=ls())
aspirina = read.csv(“aspirina.csv”, sep = “,”, dec=”.”, header = T)
aspirina
str(aspirina)
attach(aspirina)
names(aspirina)
str(aspirina)
View(aspirina)
#### 1. Determinar las diferencias entre la proporción a la que ocurrió un ataque dependiendo de la pastilla que consumió. Identifique el porcentaje global en que presentó ataque y el porcentaje global en que no presentó.
e=tapply(aspirina$freq,list(ataque,pastilla),sum) ###Genera la estructura de la tabla con la que se trabajará (la base de datos organizada según el diseño experimental previamente realizado).
prop.table(e,2) ###Riesgo Relativo columna. Para verificar esto, contrástese lo expuesto al inicio de este documento con la documentación CRAN [accesible mediante la sintaxis “?prop.table”] para más detalles.
prop.table(e,1) ###Riesgo Relativo fila. Para verificar esto, contrástese lo expuesto al inicio de este documento con la documentación CRAN [accesible mediante la sintaxis “?prop.table”] para más detalles.
(et=addmargins(e)) ###Tabla de contingencia.
addmargins(prop.table(e)) ####Distribución porcentual completa.
###Si se asume que el tipo de pastilla no influye en el hecho de tener un ataque cardíaco, entonces, debería de haber igual porcentaje de ataques en la columna de médicos que tomaron aspirina que en la de los que tomaron placebo.
###Se obtiene el valor esperado de ataques y no ataques.
### Lo anterior se realiza bajo el supuesto de que hay un 1.3% de ataques en general y un 98.7% de no ataques.
#### 2. Usando los valores observados y esperados, calcular el valor de Chi-Cuadrado para determinar si existe dependencia entre ataque y pastilla?
###Al aplicar la distribución Chi cuadrado, que es una distribución continua, para representar un fenómeno discreto, como el número de casos en cada unos de los supuestos de la tabla de 2*2, existe un ligero fallo en la aproximación a la realidad. En números grandes, esta desviación es muy escasa, y puede desecharse, pero cuando las cantidades esperadas en alguna de las celdas son números pequeños- en general se toma como límite el que tengan menos de cinco elementos- la desviación puede ser más importante. Para evitarlo, Yates propuso en 1934 una corrección de los métodos empleados para hallar el Chi cuadrado, que mejora la concordancia entre los resultados del cálculo y la distribución Chi cuadrado. En el articulo anterior, correspondiente a Chi cuadrado, el calculador expone, además de los resultados de Chi cuadrado, y las indicaciones para decidir, con arreglo a los límites de la distribución para cada uno de los errores alfa admitidos, el rechazar o no la hipótesis nula, una exposición de las frecuencias esperadas en cada una de las casillas de la tabla de contingencia, y la advertencia de que si alguna de ellas tiene un valor inferior a 5 debería emplearse la corrección de Yates. Fuente: https://www.samiuc.es/estadisticas-variables-binarias/valoracion-inicial-pruebas-diagnosticas/chi-cuadrado-correccion-yates/.
###Como se señala en [James E. Grizzle, Continuity Correction in the χ2-Test for 2 × 2 Tables, (The American Statistician, Oct., 1967, Vol. 21, No. 4 (Oct., 1967), pp. 28-32), p. 29-30], técnicamente hablando, la corrección de Yates hace que “(…) las probabilidades obtenidas bajo la distribución χ2 bajo la hipótesis nula converjan de forma más cercana con las probabilidades obtenidas bajo el supuesto de que el conjunto de datos fue generado por una muestra proveniente de la distribución hipergeométrica, i.e., generados bajo el supuesto que los dos márgenes de la tabla fueron fijados con antelación al muestreo.”
###Grizzle se refiere con “márgenes” a los totales de la tabla (véase https://www.tutorialspoint.com/how-to-create-a-contingency-table-with-sum-on-the-margins-from-an-r-data-frame). Además, la lógica de ello subyace en la misma definición matemática de la distribución hipergeométrica. Como se puede verificar en RStudio mediante la sintaxis “?rhyper”, la distribución hipergeométrica tiene la estructura matemática (distribución de probabilidad) p(x) = choose(m, x) choose(n, k-x)/choose(m+n, k), en donde m es el número de éxitos, n es el número de fracasos lo que ) y k es el tamaño de la muestra (tanto m, n y k son parámetros en función del conjunto de datos, evidentemente), con los primeros dos momentos definidos por E[X] = μ = k*p y la varianza se define como Var(X) = k p (1 – p) * (m+n-k)/(m+n-1). De lo anterior se deriva naturalmente que para realizar el análisis estocástico del fenómeno modelado con la distribución hipergeométrica es necesario conocer la cantidad de sujetos que representan los éxitos y los fracasos del experimento (en donde “éxito” y “fracaso” se define en función del planteamiento del experimento, lo cual a su vez obedece a múltiples factores) y ello implica que se debe conocer el total de los sujetos experimentales estudiados junto con su desglose en los términos binarios ya especificados.
###Lo mismo señalado por Grizzle se verifica (citando a Grizzle) en (Biometry, The Principles and Practice of Statistics in Biological Research, Robert E. Sokal & F. James Rohlf, Third Edition, p. 737), especificando que se vuelve innecesaria la corrección de Yates aún para muestras de 20 observaciones.
###Adicionalmente, merece mención el hecho que, como es sabido, la distribución binomial se utiliza con frecuencia para modelar el número de éxitos en una muestra de tamaño n extraída con reemplazo de una población de tamaño N. Sin embargo, si el muestreo se realiza sin reemplazo, las muestras extraídas no son independientes y, por lo tanto, la distribución resultante es una hipergeométrica; sin embargo, para N mucho más grande que n, la distribución binomial sigue siendo una buena aproximación y se usa ampliamente (véase https://www.wikiwand.com/en/Binomial_distribution).
###Grados de libertad correspondientes: número de filas menos 1 por número de columnas menos 1.
###Ho = Hay independencia entre el ataque y las pastillas.
(tabla.freq<-xtabs(freq~ataque+pastilla, data=aspirina))
###La tabla de frecuencias contiene tanto las frecuencias observadas como las esperadas.
###La frecuencia esperada es el conteo de observaciones que se espera en una celda, en promedio, si las variables son independientes.
###La frecuencia esperada de una variable se calcula como el producto entre el cociente [(Total de la Columna j)/(Total de Totales)]*(Total Fila i).
###PRUEBA CHI-CUADRADO AUTOMATIZADA
(prueba.chi<-chisq.test(tabla.freq,correct=F) ) ###La sintaxis “chisq.test” sirve para realizar la prueba de Chi-Cuadrado en tablas de contingencia y para realizar pruebas de bondad de ajuste.
names(prueba.chi)
###PRUEBA CHI-CUADRADO PASO A PASO
(esperado<-prueba.chi$expected) ###valores esperados
(observado<-prueba.chi$observed) ###valores observados
(cuadrados<-(esperado-observado)^2/esperado)
(chi<-sum(cuadrados))
1-pchisq(chi,1) ###Valor de p de la distribución Chi-Cuadrado (especificada mediante el conjunto de datos) calculado de forma no-automatizada.
###Si el valor p es mayor que el nivel de significancia se falla en rechazar Ho, si es menor se rechaza Ho.
###Se rechaza Ho con un nivel de significancia alfa de 0.05. Puesto que se tiene una probabilidad muy baja de cometer error tipo I, i.e., rechazar la hipótesis nula siendo falsa.

GENERALIDADES Y ORÍGENES HISTÓRICOS DE LA DISTRIBUCIÓN CHI-CUADRADO
ISADORE NABI

FUNDAMENTOS GENERALES DEL PROCESO DE ESTIMACIÓN Y PRUEBA DE HIPÓTESIS EN R STUDIO. PARTE II, CÓDIGO EN R STUDIO CON COMENTARIOS
ISADORE NABI
##ESTABLECER EL DIRECTORIO DE TRABAJO
setwd(“(…)”)
##LEER EL ARCHIVO DE DATOS. EN ESTE CASO, SUPÓNGASE QUE LOS DATOS SON DE UNA MUESTRA ALEATORIA DE 21 TIENDAS UBICADAS EN DIFERENTES PARTES DEL PAÍS Y A LAS CUALES SE LES REALIZÓ VARIOS ESTUDIOS. PARA ELLO SE MIDIERON ALGUNAS VARIABLES QUE SE PRESENTAN A CONTINUACIÓN
###- menor16= es un indicador de limpieza del lugar, a mayor número más limpio.
###- ipc= es un indice de producto reparado con defecto, indica el % de producto que se pudo reparar y posteriormente comercializar.
###- ventas= la cantidad de productos vendidos en el último mes.
read.table(“estudios.txt”)
## CREAR EL ARCHIVO Y AGREGAR NOMBRES A LAS COLUMNAS
estudios = read.table(“estudios.txt”, col.names=c(“menor16″,”ipc”,”ventas”))
names(estudios)
nrow(estudios)
ncol(estudios)
dim(estudios)
## REVISAR LA ESTRUCTURA DEL ARCHIVO Y CALCULAR LA MEDIA, LA DESVIACIÓN ESTÁNDAR Y LOS CUANTILES PARA LAS VARIABLES DE ESTUDIO Y, ADICIONALMENTE, CONSTRÚYASE UN HISTOGRAMA DE FRECUENCIAS PARA LA VARIABLE “VENTAS”
str(estudios)
attach(estudios)
ventas
###Nota: la función “attach” sirve para adjuntar la base de datos a la ruta de búsqueda R. Esto significa que R busca en la base de datos al evaluar una variable, por lo que se puede acceder a los objetos de la base de datos simplemente dando sus nombres.
###Nota: Al poner el comando “attach”, la base de datos se adjunta a la dirección de búsqueda de R. Entonces ahora pueden llamarse las columnas de la base de datos por su nombre sin necesidad de hacer referencia a la base de datos ventas es una columna -i.e., una variable- de la tabla estudios). Así, al escribrlo, se imprime (i.e., se genera visualmente para la lectura ocular)
## CALCULAR LOS ESTADÍSTICOS POR VARIABLE Y EN CONJUNTO
mean(ventas)
sd(ventas)
var(ventas)
apply(estudios,2,mean)
apply(estudios,2,sd)
###Nota: la función “apply” sirve para aplicar otra función a las filas o columnas de una tabla de datos
###Nota: Si en “apply” se pone un “1” significa que aplicará la función indicada sobre las filas y si se pone un “2” sobre las columnas
## APLICAR LA FUNCIÓN “quantile”.
quantile(ventas) ###El cuantil de función genérica produce cuantiles de muestra correspondientes a las probabilidades dadas. La observación más pequeña corresponde a una probabilidad de 0 y la más grande a una probabilidad de 1.
apply(estudios,2,quantile)
###Nótese que para aplicar la función “apply” debe haberse primero “llamado” (i.e., escrito en una línea de código) antes la función que se aplicará (en este caso es la función “quantile”).
(qv = quantile(ventas,probs=c(0.025,0.975)))
###Aquí se está creando un vector de valores correspondientes a determinada probabilidad (las ventas, en este caso), que para este ejemplo son probabilidades de 0.025 y 0.975 de probabilidad, que expresan determinada proporción de la unidad de estudio que cumple con una determinada característica (que en este ejemplo esta proporción es el porcentaje de tiendas que tienen determinado nivel de ventas -donde la característica es el nivel de ventas-).
## GENERAR UN HISTOGRAMA DE FRECUENCIAS PARA LA COLUMNA “ventas”
hist(ventas)
abline(v=qv,col=2)
###Aquí se indica con “v” el conjunto de valores x para los cuales se graficará una línea. Como se remite a “qv” (que es un vector numérico de dos valores, 141 y 243) en el eje de las x, entonces graficará dos líneas color rojo (una en 141 y otra en 243).
###Aquí “col” es la sintaxis conocida como parte de los “parámetros gráficos” que sirve para especificar el color de las líneas
hist(ventas, breaks=7, col=”red”, xlab=”Ventas”, ylab=”Frecuencia”,
main=”Gráfico
Histograma de las ventas”)
detach(estudios)
###”breaks” es la indicación de cuántas particiones tendrá la gráfica (número de rectángulos, para este caso).
## GENERAR UNA DISTRIBUCIÓN N(35,4) CON NÚMEROS PSEUDOALEATORIOS PARA UN TAMAÑO DE MUESTRA n=1000
y = rnorm(1000,35,2)
hist(y)
qy = quantile(y,probs=c(0.025,0.975))
hist(y,freq=F)
abline(v=qy,col=2)
lines(density(y),col=2) #”lines” es una función genérica que toma coordenadas dadas de varias formas y une los puntos correspondientes con segmentos de línea.
## GENERAR UNA FUNCIÓN CON LAS VARIABLES n (CANTIDAD DE DATOS), m (MEDIA MUESTRAL) y s (DESVIACIÓN ESTÁNDAR MUESTRAL) QUE ESTIME Y GRAFIQUE, ADEMÁS DE LOS CÁLCULOS DEL INCISO ANTERIOR, LA MEDIA.
plot.m = function(n,m,s) {
y = rnorm(n,m,s)
qy = quantile(y,probs=c(0.025,0.975))
hist(y,freq=F)
abline(v=qy,col=2)
lines(density(y),col=2) ###Aquí se agrega una densidad teórica (una curva que dibuja una distribución de probabilidad -de masa o densidad- de referencia), la cual aparece en color rojo.
mean(y)
}
## OBTENER UNA MUESTRA DE TAMAÑO n=10 DE N(100, 15^2)
plot.m(10000,100,15)
###Nótese que formalmente la distribución normal se caracteriza siempre por su media y varianza, aunque en la sintaxis “rnorm” de R se introduzca su media y la raíz de su varianza (la desviación estándar muestral)
##Generar mil repeticiones e ingresarlas en un vector. Compárense sus medias y desviaciones estándar.
n=10000; m=100;s=15
I = 1000 ###”I” son las iteraciones
medias = numeric(I)
for(i in 1:I) {#”for” es un bucle (sintaxis usada usualmente para crear funciones personalizadas)
sam=rnorm(n,m,s) ###Aquí se crea una variable llamada “sam” (de “sample”, i.e., muestra) que contiene una la distribución normal creada con números pseudoaleatorios.
medias[i]=mean(sam) } ###”sam” se almacena en la i-ésima posición la i-ésima media generada con “rnorm” que le corresponde dentro del vector numérico de iteraciones (el que contiene las medias de cada iteración) medias[i] (que contiene los elementos generados con la función “mean(sam)”).
###Un bucle es una interrupción repetida del flujo regular de un programa; pueden concebirse como órbitas (en el contexto de los sistemas dinámicos) computacionales. Un programa está diseñado para ejecutar cada línea ordenadamente (una a una) de forma secuencial 1,2,3,…,n. En la línea m el programa entiende que tiene que ejecutar todo lo que esté entre la línea n y la línea m y repetirlo, en orden secuencial, una cantidad x de veces. Entonces el flujo del programa sería, para el caso de un flujo regular 1,2,3,(4,5,…,m),(4,5,…,m),…*x,m+1,m+2,…,n.
## UTILIZAR LA VARIABLE “medias[i]” GENERADA EN EL INCISO ANTERIOR PARA DETERMINAR LA DESVIACIÓN ESTÁNDAR DE ESE CONJUNTO DE MEDIAS (ALMACENADO EN “medias[i]”) Y DETERMINAR SU EQUIVALENCIA CON EL ERROR ESTÁNDAR DE LA MEDIA (e.e.)
###Lo anterior evidentemente implica que se está construyendo sintéticamente (a través de bucles computacionales) lo que, por ejemplo, en un laboratorio botánico se registra a nivel de datos (como en el que Karl Pearson y Student hacían sus experimentos y los registraban estadísticamente) y luego se analiza en términos de los métodos de la estadística descriptiva e inferencial (puesto que a esos dominios pertenece el e.e.).
sd(medias) ### desviación de la distribución de las medias
(ee = s/sqrt(n) )### equivalencia teórica
## COMPARAR LA DISTRIBUCIÓN DE MEDIAS
m
mean(medias)
## GRAFICAR LA DISTRIBUCIÓN DE MEDIAS GENERADA EN EL INCISO ANTERIOR
hist(medias)
qm = quantile(medias,probs=c(0.025,0.975))
hist(medias,freq=F)
abline(v=qm,col=2)
lines(density(medias),col=2)
## GENERAR UN INTERVALO DE CONFIANZA CON UN NIVEL DE 0.95 PARA LA MEDIA DE LAS VARIABLES SUJETAS A ESTUDIO
attach(estudios)
### Percentil 0.975 de la distribución t-student para 95% de área bajo la curva
n = length(ventas) ###Cardinalidad o módulo del conjunto de datos
t = qt(0.975,n-1) ###valor t de la distribución t de student correspondiente a un nivel de probabilidad y n-1 gl
###Se denominan pruebas t porque todos los resultados de la prueba se basan en valores t. Los valores T son un ejemplo de lo que los estadísticos llaman estadísticas de prueba. Una estadística de prueba es un valor estandarizado que se calcula a partir de datos de muestra durante una prueba de hipótesis. El procedimiento que calcula la estadística de prueba compara sus datos con lo que se espera bajo la hipótesis nula (fuente: https://blog.minitab.com/en/adventures-in-statistics-2/understanding-t-tests-t-values-and-t-distributions).
###”qt” es la sintaxis que especifica un valor t determinado de la variable aleatoria de manera que la probabilidad de que esta variable sea menor o igual a este determinado valor t es igual a la probabilidad dada (que en la sintaxis de R se designa como p)
###Para más información véase https://marxianstatistics.com/2021/09/05/analisis-teorico-de-la-funcion-cuantil-en-r-studio/
###”n-1″ son los grados de libertad de la distribución t de student.
#### Error Estándar
ee = sd(ventas)/sqrt(n)
### Intervalo
mean(ventas)-t*ee
mean(ventas)+t*ee
mean(ventas)+c(-1,1)*t*ee ###c(-1,1) es un vector que se introduce artificialmente para poder construir el intervalo de confianza al 95% (u a otro nivel de confianza deseado) en una sola línea de código.
## ELABORAR UNA FUNCIÓN QUE PERMITA CONSTRUIR UN INTERVALO DE CONFIANZA AL P% DE NIVEL DE CONFIANZA PARA LA VARIABLE X
ic = function(x,p) {
n = length(x)
t = qt(p+((1-p)/2),n-1)
ee = sd(x)/sqrt(n)
mean(x)+c(-1,1)*t*ee
}
###Intervalo de 95% confianza para ventas
ic(ventas,0.95)
ic(ventas,0.99)
###El nivel de confianza hace que el intervalo de confianza sea más grande pues esto implica que los estadísticos de prueba (las versiones muestrales de los parámetros poblacionales) son más estadísticamente más robustos, por lo que su vecindario de aplicación es más amplio.
ic(ipc,0.95)
ic(menor16,0.95)
## REALIZAR LA PRUEBA DE HIPÓTESIS (PARA UNA MUESTRA) DENTRO DEL INTERVALO DE CONFIANZA GENERADO AL P% DE NIVEL DE CONFIANZA
t.test(ventas,mu=180) ###Por defecto, salvo que se cambie tal configuración, R realiza esta prueba a un nivel de confianza de 0.95.
### Realizando manualmente el cálculo anterior:
(t2=(mean(ventas)-180)/ee) ###Aquí se calcula el valor t por separado (puesto que la sintaxis “t.test” lo estima por defecto, como puede verificarse en la consola tras correr el código). Se denota con “t2” porque anteriormente se había definido en la línea de código 106 t = qt(0.975,n-1) para la construcción manual de los intervalos de confianza.
2*(1-pt(t2,20)) ###Aquí se calcula manualmente el valor p. Se multiplica por dos para tener la probabilidad acumulada total (considerando ambas colas) al valor t (t2, siendo más precisos) definido, pues esta es la definición de valor p. Esto se justifica por el hecho de la simetría geométrica de la distribución normal, la cual hace que la probabilidad acumulada (dentro de un intervalo de igual longitud) a un lado de la media sea igual a la acumulada (bajo la condición especificada antes) a la derecha de la media.
2*(pt(-t2,20)) ###Si el signo resultante de t fuese negativo. Además, 20 es debido a n-1 = 21-1 = 20.
###La sintaxis “pt” calcula el valor de la función de densidad acumulada (cdf) de la distribución t de Student dada una determinada variable aleatoria x y grados de libertad df (degrees of freedom, equivalente a gl en español), véase https://www.statology.org/working-with-the-student-t-distribution-in-r-dt-qt-pt-rt/
## CREAR UNA VARIABLE QUE PERMITA SEPARAR ESPACIALMENTE (AL INTERIOR DE LA GRÁFICA QUE LOS REPRESENTA) AQUELLOS ipc MENORES A UN VALOR h (h=117) DE AQUELLOS QUE SON IGUALES O MAYORES QUE h (h=117)
(ipc1 = 1*(ipc<17)+2*(ipc>=17))
ipc2=factor(ipc1,levels=c(1,2),labels=c(“uno”,”dos”))
plot(ipc2,ipc)
abline(h=17,col=2)
## GENERAR GRÁFICO DE DIAMENTE CON LOS INTERVALOS DE CONFIANZA AL 0.95 DE NdC CENTRADOS EN LAS MEDIAS DE CADA GRUPO CREADO ALREDEDOR DE 17 Y UN BOX-PLOT
library(gplots)
plotmeans(ventas~ipc2) ###Intervalos del 95% alrededor de la media (GRÁFICO DE DIMANTES)
boxplot(ventas~ipc2)
## REALIZAR LA PRUEBA DE HIPÓTESIS DE QUE LA MEDIA ES LA MISMA PARA LOS DOS GRUPOS GENERADOS ALREDEDOR DE h=17
(med = tapply(ventas,ipc1,mean))
(dev = tapply(ventas,ipc1,sd))
(var = tapply(ventas,ipc1,var))
(n = table(ipc1))
dif=med[1]-med[2]
###La sintaxis “tapply” aplica una función a cada celda de una matriz irregular (una matriz es irregular si la cantidad de elementos de cada fila varía), es decir, a cada grupo (no vacío) de valores dados por una combinación única de los niveles de ciertos factores.
### PRUEBA DE HIPÓTESIS EN ESCENARIO 1: ASUMIENDO VARIANZAS IGUALES (SUPUESTO QUE EN ESCENARIOS REALES DEBERÁ VERIFICARSE CON ANTELACIÓN)
varpond= ((n[1]-1)*var[1] + (n[2]-1)*var[2])/(n[1]+n[2]-2) ###Aquí se usa una varianza muestral ponderada como medida más precisa (dado que el tamaño de los grupos difiere) de una varianza muestral común entre los dos grupos construidos alrededor de h=17
e.e=sqrt((varpond/n[1])+(varpond/n[2]))
dif/e.e
t.test(ventas~ipc1,var.equal=T)
t.test(ventas~ipc1) #Por defecto la sintaxis “t.test” considera las varianzas iguales, por lo que en un escenario de diferentes varianzas deberá ajustarse esto como se muestra a continuación.
### PRUEBA DE HIPÓTESIS EN ESCENARIO 2: ASUMIENDO VARIANZAS DESIGUALES (AL IGUAL QUE ANTES, ESTO DEBE VERIFICARSE)
e.e2=sqrt((var[1]/n[1])+(var[2]/n[2]))
dif/e.e2
a=((var[1]/n[1]) + (var[2]/n[2]))^2
b=(((var[1]/n[1])^2)/(n[1]-1)) +(((var[2]/n[2])^2)/(n[2]-1))
(glmod=a/b)
t.test(ventas~ipc1,var.equal=F)
###Para aceptar o rechazar la hipótesis nula el intervalo debe contener al cero (porque la Ho afirma que la verdadera diferencia en las medias -i.e., su significancia estadística- es nula).
###Conceptualmente hablando, una diferencia estadísticamente significativa expresa una variación significativa en el patrón geométrico que describe al conjunto de datos. Véase https://marxianstatistics.com/2021/08/27/modelos-lineales-generalizados/. Lo que define si una determinada variación es significativa o no está condicionado por el contexto en que se realiza la investigación y la naturaleza misma del fenómeno estudiado.
## REALIZAR PRUEBA F PARA COMPARAR LA VARIANZA DE LOS GRUPOS Y LA PROBABILIDAD ASOCIADA
(razon.2 = var[1]/var[2]) ###Ratio de varianzas (asumiendo que las varianzas poblacionales son equivalentes a la unidad, en otro caso su estimación sería matemáticamente diferente; véase https://sphweb.bumc.bu.edu/otlt/mph-modules/bs/bs704_power/bs704_power_print.html y https://stattrek.com/online-calculator/f-distribution.aspx).
pf(razon.2,n[1]-1,n[2]-1) ###Al igual que “pt” (para el caso de la t de Student que compara medias de dos grupos o muestras), “pf” en el contexto de la prueba F (que compara la varianza de dos grupos o muestras) calcula la probabilidad acumulada que existe hasta determinado valor.
###La forma general mínima (más sintética) de la sintaxis “pf” es “pf(x, df1, df2)”, en donde “x” es el vector numérico (en este caso, de un elemento), df1 son los gl del numerador y df2 son los grados de libertad del denominador de la distribución F (cuya forma matemática puede verificarse en la documentación de R; véase https://stat.ethz.ch/R-manual/R-devel/library/stats/html/Fdist.html).
(2*pf(razon.2,n[1]-1,n[2]-1)) ###Aquí se calcula el valor p manualmente.
###Realizando de forma automatizada el procedimiento anterior:
var.test(ventas~ipc1)
detach(estudios)
###Para aceptar o rechazar la hipótesis nula el intervalo debe contener al 1 porque la Ho afirma que la varianza de ambas muestras es igual (lo que implica que su cociente o razón debe ser 1), lo que equivale a afirmar que la diferencia real entre desviaciones (la significancia estadística de esta diferencia) es nula.
## EN EL ESCENARIO DEL ANÁLISIS DE MUESTRAS PAREADAS, ANALIZAR LOS DATOS SOBRE EL EFECTO DE DOS DROGAS EN LAS HORAS DE SUEÑO DE UN GRUPO DE PACIENTES (CONTENIDOS EN EL ARCHIVO “sleep” DE R)
attach(sleep) ###”sleep” es un archivo de datos nativo de R, por ello puede “llamarse” sin especificaciones de algún tipo.
plot(extra ~ group)
plotmeans(extra ~ group,connect=F) ###Intervalos del 95% alrededor de la media. El primer insumo (entrada) de la aplicación “plotmeans” es cualquier expresión simbólica que especifique la variable dependiente o de respuesta (continuo) y la variable independiente o de agrupación (factor). En el contexto de una función lineal, como la función “lm()” que es empleada por “plotmeans” para graficar (véase la documentación de R sobre “plotmeans”), sirve para separar la variable dependiente de la o las variables independientes, las cuales en este caso de aplicación son los factores o variables de agrupación (puesto que se está en el contexto de casos clínicos y, en este contexto, las variables independientes son las variables que sirven de criterio para determinar la forma de agrupación interna del conjunto de datos; este conjunto de datos contiene las observaciones relativas al efecto de dos drogas diferentes sobre las horas de sueño del conjunto de pacientes-).
A = sleep[sleep$group == 1,] ###El símbolo “$” sirve para acceder a una variable (columna) de la matriz de datos, en este caso la número 1 (por ello el “1”).
B = sleep[sleep$group == 2,]
plot(1:10,A$extra,type=”l”,col=”red”,ylim=c(-2,7),main=”Gráfico 1
Horas de sueño entre pacientes con el tratamiento A y B”,ylab=”Horas”,xlab=”Numero de paciente”,cex.main=0.8)
lines(B$extra,col=”blue”)
legend(1,6,legend=c(“A”,”B”),col=c(“red”,”blue”),lwd=1,box.col=”black”,cex=1)
t.test(A$extra,B$extra)
t.test(A$extra,B$extra,paired=T)
t.test(A$extra-B$extra,mu=0)
###Una variable de agrupación (también llamada variable de codificación, variable de grupo o simplemente variable) clasifica las observaciones dentro de los archivos de datos en categorías o grupos. Le dice al sistema informático (sea cual fuere) cómo el usuario ha clasificado los datos en grupos. Las variables de agrupación pueden ser categóricas, binarias o numéricas.
###Cuando se desea realizar un comando dentro del texto (en un contexto de formato Rmd) se utiliza así,por ejemplo se podría decir que la media del sueño extra es `r mean(sleep$extra)` y la cantidad de datos son `r length(sleep$extra)`
## ESTIMACIÓN DE LA POTENCIA DE UNA PRUEBA DE HIPÓTESIS (PROBABILIDAD BETA DE COMETER ERROR TIPO II)
library(pwr) ###”pwr” es una base de datos nativa de R
delta=3 ###Nivel de Resolución de la prueba. Para un valor beta (probabilidad de cometer error tipo II) establecido el nivel de resolución es la distancia mínima que se desea que la prueba sea capaz de detectar, es decir, que si existe una distancia entre los promedios tal que la prueba muy probablemente rechace la hipótesis nula Ho. Para el cálculo manual de la probabilidad beta véase el complemento de este documento (FUNDAMENTOS GENERALES DEL PROCESO DE ESTIMACIÓN Y PRUEBA DE HIPÓTESIS EN R STUDIO. PARTE I, TEORÍA ESTADÍSTICA)
s=10.2 ###Desviación estándar muestral
(d=delta/s) #Tamano del efecto.
pwr.t.test(n=NULL,d=d,power =0.9,type=”one.sample”)
## ESTIMAR CON EL VALOR ÓPTIMO PARA EL NIVEL DE RESOLUCIÓN, PARTIENDO DE n=40 Y MANTENIENDO LA POTENCIA DE 0.9
(potencia=pwr.t.test(n=40,d=NULL,power =0.9,type=”one.sample”))
potencia$d*s #Delta
## GRAFICAR LAS DIFERENTES COMBINACIONES DE TAMAÑO DE MUESTRA Y NIVEL DE RESOLUCIÓN PARA UNA POTENCIA DE LA PRUEBA FIJA
s=10.2
deltas=seq(2,6,length=30)
n=numeric(30)
for(i in 1:30) {
(d[i]=deltas[i]/s)
w=pwr.t.test(n=NULL,d=d[i],power =0.9,type=”one.sample”)
n[i]=w$n
}
plot(deltas,n,type=”l”)
## SUPÓNGASE QUE SE QUIERE PROBAR SI DOS GRUPOS PRESENTAN DIFERENCIAS ESTADÍSTICAMENTE SIGNIFICATIVAS EN LOS NIVELES PROMEDIO DE AMILASA, PARA LO CUAL SE CONSIDERA IMPORTANTE DETECTAR DIFERENCIAS DE 15 UNIDADES/ML O MÁS ENTRE LOS PROMEDIOS
s2p=290.9 ###Varianza ponderada de los dos grupos
(sp=sqrt(s2p)) ###Desviación estándar ponderada de los dos grupos
delta=15
(d=delta/sp)
pwr.t.test(n=NULL,d=d,power =0.9,type=”two.sample”)