Aquí tienes el texto completo y actualizado, con las versiones en inglés y español listas para copiar y pegar en WordPress. He incorporado todos los cambios metodológicos y los hallazgos críticos (Horseshoe, DFM, PCA y HP-GC) que discutimos.
PROBLEM STATEMENT AND OBJECTIVES
The article addresses the lack of a theoretically grounded criterion for determining which economic activities should be included or excluded when estimating the long-term Marxist average rate of profit (ARoP). The main objective is to provide a standard Marxist decision criterion for the inclusion and exclusion of economic activities in the calculation of the ARoP, applied to the case of U.S. economic sectors between 1960 and 2020.
THEORETICAL FRAMEWORK
The study is based on Marxist theory, specifically on the Marxist definition of productive labor, its location in the circuit of capital, and its relationship with the production of surplus value. Emphasis is placed on the distinction between productive and unproductive labor, as well as the difference between productive and unproductive consumption.
METHODS AND TECHNIQUES
The study uses a variety of advanced econometric and time series analysis techniques:
Daubechies wavelet transform filters with increased symmetry.
Empirical Mode Decomposition (EMD).
Hodrick-Prescott filter embedded in an unobserved components model (HP-GC).
Various unit root tests.
Principal Component Analysis (PCA) via Singular Value Decomposition (SVD) with Heavy-tailed Distribution Analysis (Gamma/Weibull) and Information Theory (Entropy).
Regularized Horseshoe Regression (RHR) for variable selection in high-multicollinearity environments.
Dynamic Factor Models (DFM) for structural validation and latent signal detection.
RESULTS
Criteria were established for the inclusion and exclusion of economic sectors in the calculation of the Marxist ARoP.
The application of these criteria to the U.S. economy resulted in the exclusion of sectors such as wholesale and retail trade, finance and insurance, real estate, and government.
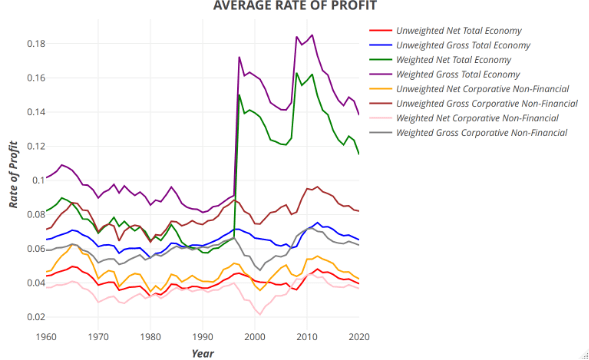
The ARoP calculated with the sectors included according to the established criteria showed a long-term decreasing trend, consistent with Marxist theory.
Econometric analyses revealed a structural duality: while Regularized Horseshoe Regression identified a productive causal core aligned with value theory, DFM and PCA showed that the macroscopic phenomenological dynamics are dominated by rentier (Real Estate) and government sectors. However, the declining trend of the Rate of Profit manifests in both nuclei.
PCA analysis demonstrated that qualitative systemic variance (Gamma/Weibull distributions) is driven by a small subset of sectors (Top 10-15%), while the bulk of the economy (PC1) represents inertial noise or ‘Brownian motion’.
CONCLUSIONS
The proposed criteria for the inclusion and exclusion of sectors in the calculation of the Marxist ARoP are gnoseologically and econometrically valid for the case of the U.S. economy between 1960 and 2020.
The study satisfies the Coherence Theory of Truth, as the new proposition (Marxist criteria) harmonizes logically with theory and statistically with complex objective evidence.
The criteria demonstrated objective consistency regarding which sectors are structurally relevant, distinguishing between the productive essence (identified by Horseshoe) and the rentier appearance (identified by DFM).
The long-term decreasing trend of the ARoP was confirmed by non-parametric filters (EMD, Wavelets); exceptions of flat trends observed with the HP-GC filter in rentier series were identified as artifacts of the filter’s rigidity regarding asset price inertia, rather than signs of economic health.
The study provides a solid methodological basis for future research on the ARoP and the dynamics of capitalism from a Marxist perspective.
PLANTEAMIENTO DEL PROBLEMA Y OBJETIVOS
El artículo aborda la falta de un criterio teóricamente fundamentado para determinar qué actividades económicas deben incluirse o excluirse al estimar la tasa media de ganancia (TMG) marxista a largo plazo. El objetivo principal es proporcionar un criterio de decisión estándar marxista para la inclusión y exclusión de actividades económicas en el cálculo de la TMG, aplicado al caso de los sectores económicos de Estados Unidos entre 1960 y 2020.
MARCO TEÓRICO
El estudio se basa en la teoría marxista, específicamente en la definición marxista de trabajo productivo, su ubicación en el circuito del capital y su relación con la producción de plusvalía. Se hace hincapié en la distinción entre trabajo productivo e improductivo, así como en la diferencia entre consumo productivo e improductivo.
MÉTODOS Y TÉCNICAS
El estudio utiliza una variedad de técnicas econométricas y de análisis de series temporales avanzadas:
Filtros de transformada wavelet de Daubechies con simetría aumentada.
Descomposición en Modos Empíricos (EMD).
Filtro Hodrick-Prescott incrustado en un modelo de componentes no observables (HP-GC).
Diversas pruebas de raíz unitaria.
Análisis de Componentes Principales (ACP) vía Descomposición en Valores Singulares (DVS) con Análisis de Distribuciones de Cola Pesada (Gamma/Weibull) y Teoría de la Información (Entropía).
Regresión Horseshoe Regularizada (RHR) para selección de variables en entornos de alta multicolinealidad.
Modelos de Factores Dinámicos (DFM) para validación estructural y detección de señales latentes.
RESULTADOS
Se establecieron criterios para la inclusión y exclusión de sectores económicos en el cálculo de la TMG marxista.
La aplicación de estos criterios a la economía estadounidense resultó en la exclusión de sectores como el comercio mayorista y minorista, finanzas y seguros, bienes raíces, y el gobierno.
La TMG calculada con los sectores incluidos según los criterios establecidos mostró una tendencia decreciente a largo plazo, consistente con la teoría marxista.
Los análisis econométricos revelaron una dualidad estructural: mientras la Regresión Horseshoe identificó un núcleo causal productivo alineado con la teoría del valor, el DFM y el ACP evidenciaron que la dinámica macroscópica fenomenológica está dominada por sectores rentistas (Bienes Raíces) y gubernamentales. Sin embargo, la tendencia decreciente de la Tasa de Ganancia se manifiesta en ambos núcleos.
El análisis de ACP demostró que la varianza sistémica cualitativa (distribuciones Gamma/Weibull) es impulsada por un pequeño subconjunto de sectores (Top 10-15%), mientras que el grueso de la economía (PC1) representa ruido inercial o ‘movimiento browniano’.
CONCLUSIONES
Los criterios propuestos para la inclusión y exclusión de sectores en el cálculo de la TMG marxista son válidos gnoseológica y econométricamente para el caso de la economía estadounidense entre 1960 y 2020.
La investigación satisface la Teoría de la Coherencia de la Verdad, ya que la nueva proposición (criterios marxistas) armoniza lógicamente con la teoría y estadísticamente con la evidencia objetiva compleja.
Los criterios demostraron consistencia objetiva, distinguiendo entre la esencia productiva (identificada por Horseshoe) y la apariencia rentista (identificada por DFM) en la dinámica económica capitalista.
Se confirmó la tendencia decreciente a largo plazo de la TMG mediante filtros no paramétricos (EMD, Wavelets); las excepciones de tendencia plana observadas con el filtro HP-GC en series rentistas se identificaron como artefactos de la rigidez del filtro ante la inercia de precios de activos, y no como signos de salud económica.
El estudio proporciona una base metodológica sólida para futuras investigaciones sobre la TMG y la dinámica del capitalismo desde una perspectiva marxista.
carchedi-roberts-inflation-presentation-finalDownload The purpose of this post is to ensure our understanding of Marxist categories remains precise and that all our investigations are rigorous.
As usual it won’t be possible to report on all the many sessions at this year’s London Historical Materialism conference that took place last weekend. I could only attend a few sessions and concentrated, naturally, on ones to do with Marxist economics. Also, I was participating in two sessions myself that clashed with others that […]
Una idea muy extendida en Argentina es que la elevada inflación se debe, en gran medida, a los “formadores de precios”. Se trataría de oligopolios que aumentan “de manera unilateral” los precios de sus productos, desatando una cadena de subas en cascada en el resto de la economía. La “unilateralidad” en el establecimiento de esos […]
Más allá de la interesante curiosidad de que alguien que no considera válido el teorema fundamental de la economía política marxista (la ley de la tendencia decreciente de la tasa media de ganancia) acuda a los fundamentos del Marxismo para refutar la idea de la existencia del poder de monopolio, un error gnoseológico fundamental que exhibe el artículo en cuestión es olvidar, como a menudo los economistas “marxistas” lo hacen, de que si bien la inflación tiene su fundamento último en el sector real, no es menos cierto que el poder económico que les procura a los grandes capitalistas su dominancia en el sector real se transmite al sector financiero por cuanto estos sectores están íntimamente vinculados (con dominancia, en última instancia, del sector real sobre el sector financiero -y los cracks bursátiles son, precisamente, el mecanismo mediante el cual los sistemas de economía política corrigen la violación al postulado anterior-), así como tampoco es menos cierto que la ciencia en cuestión no se llama economía (ni siquiera los amos y amas de casa hacemos economía, porque siempre hay relaciones de poder, en una sociedad de clases, inherentes a todo fenómeno de distribución del ingreso -probablemente en las tribus del Amazonía es diferente-), sino economía política y en tal sentido posee la implicación de relaciones de poder, de relaciones de dominantes y dominados que expresan una determinada estructura de clases que se corresponde a un determinado grado de desarrollo de las fuerzas productivas del trabajo, relaciones de poder que son también técnicas, puesto que lo político es un fenómeno exclusivo de las sociedades humanas y, por consiguiente, un fenómeno de estudio de las ciencias sociales, y como tal posee inherentemente una explicación científica, íntimamente ligada a la de los fenómenos económicos, de ahí que la ciencia se llame, insisto, economía política.
El mismo articulista, en otro artículo, ha planteado la interesante hipótesis de que la inflación ocurre para que las innovaciones tecnológicas repercutan en la tasa media de ganancia, es decir, para que se materialice la plusvalía relativa. Más allá de que la hipótesis en cuestión sea planteada en un escenario de valores y no de precios de producción, además del hecho de que Rosdolsky ha señalado (fundamentalmente en el apartado relativo a los salarios reales dentro de su estudio de los Grundrisse) que la caída de los salarios reales no es una tendencia generalizada a escala planetaria (o alza, en el caso que la innovación no provenga de las ramas productivas que producen mercancías que componen la canasta salarial, al menos durante el período de rezago de la transmisión de la innovación a las ramas productivas que componen la canasta en cuestión), es razonable esperar que el escenario de precios de producción simplemente complejice y/o complique el mecanismo mediante el cual la relación entre la plusvalía relativa y la inflación se expresa, así como también que se pueda justificar que en los países desarrollados los salarios reales no caigan en términos del mecanismo mediante el cual ocurre un proceso de nivelación tendencial a nivel mundial de los salarios (en la primera página del capítulo VIII del tomo III de El Capital, en la antesala a su planteamiento sobre el surgimiento de los precios de producción -capítulo IX de la misma fuente antes referida-), específicamente explicando que en los grandes centros industriales los salarios reales no decaen porque las ganancias de los capitalistas de estos centros, mermadas por tal efecto, son compensadas por las ganancias que estos mismos capitalistas obtienen de sus inversiones en los países de la perisferia (perisferias de tales centros). Sin embargo, lo curioso del planteamiento del articulista es que en tal artículo se dice explícitamente que para que esto ocurra los bancos centrales deben garantizar un determinado nivel de inflación (y se hace alusión a la “regla de Taylor” que siguen muchos bancos centrales -con independencia que no es el único régimen monetario existente en los países capitalistas y que los planteamientos en cuestión deberán ser generalizados considerando esos otros regímenes monetarios-). Más allá que el articulista no explica los criterios técnicos bajo los cuales los bancos centrales fijan determinada tasa de inflación a la luz de su hipótesis de la innovación tecnológica como causa fundamental de la inflación (lo cual es fundamental para que la hipótesis se sostenga), cualquier persona que tenga conocimiento práctico y objetivo de cómo se trabaja al interior de los bancos centrales (a nivel de los economistas jefe, gerencia, presidencia y junta directiva) sabe que muchas políticas monetarias se toman en tales instituciones bajo el único criterio de procurarles mayores ganancias a los grandes capitalistas (por ejemplo, las devaluaciones cambiarias que ocurren en muchos países -como parte de una política cambiaria- en determinados momentos del año, como en el caso particular del escenario en que ocurre una depreciación del dólar estadounidense, los bancos privados en determinados países tienen sus posiciones dolarizadas y el banco central devalúa la moneda nacional para que las ganancias de los bancos privados no se vean afectadas -y en muchos casos aumenten-), sin que existan de por medio, ni siquiera por asomo, el riesgo de que por no realizarse tal política monetaria las condiciones de reproducción del proceso de acumulación de capital se rompan y la economía pueda entrar en crisis, o que en ausencia de tales políticas monetarias los inversionitas decidiecen abandonar el país, etc., es decir, sin que exista ningún fundamento técnico-económico de por medio, aunque sí un fundamento técnico-político. Insistimos, por ello se llama economía política y no meramente economía. Esto no significa que la hipótesis planteada por el articulista citado sobre la naturaleza tecnológica (y, por consiguiente, real) de la inflación no pueda ser el elemento central (de hecho, el elemento central de la inflación es una cuestión técnica-económica proveniente del sector real, sea a través de la hipótesis citada o de otra hipótesis de la misma naturaleza), sino que no es lo único que constituye el fenómeno en cuestión, por el contrario, tal fenómeno tiene dos aristas, ambas totalmente materiales y objetivas (en donde la política está supeditada a la económica por cuanto las relaciones de clase existen en cuanto al interior del proceso de producción existe una distinta vinculación con los medios de producción por parte de dos sectores de la sociedad humana), ambas regidas por criterios científico-técnicos.
Esto me recuerda a aquella célebre frase de Lenin, citada por Rosdolsky, que describía cómo los “marxistas”, a causa de no leer a Hegel, seguían (para aquella época) sin entender a Marx, cuestión que sigue siendo válida para los “marxistas” de hoy en día (e incluso de los anteriores a Lenin, célebre es también la frase de Marx de “Si estos son marxistas, yo no soy marxista”), especialmente para los economistas. La lógica dialéctica-materialista no es una lógica dicotómica, es decir, no es del tipo “o es una relación regulada rigurosamente por un criterio técnico-económico o es subjetivismo”, por cuanto la base económica y la superestructura ideológica están íntimamente ligadas (supeditándose la superestructura, en última instancia, a la base), tanto como lo está lo económico a lo político, puesto que un sistema económico de clases (de economía política) no puede subsistir sin una dictadura, es decir, sin que una clase A (la dominante) imponga a otra clase B (la dominada) sus intereses (intereses que son antagónicos entre sí) con independencia del medio usado para ello, porque aunque la independencia antes expresada exista, lo ideológico (expresado como alienación, concepto teórico que Marx desarrolla en los Manuscritos Económicos y Filosóficos de 1844) es el elemento indispensable para garantizar la existencia fáctica de la dictadura (en dictaduras militares, es decir, en dictaduras formales, evidentemente lo ideológico juega un papel menos preponderante -no por ello deja de ser preponderante, porque al fin y al cabo la rebelión contra las dictaduras militares es, en la enorme mayoría de casos, contra la no-inclusión política, no contra la estructura distributiva y menos contra las relaciones sociales de producción-, mientras que en dictaduras fácticas -las democracias burguesas- lo ideológico cobra aún más relevancia), por lo que existe una retroalimentación entre la base económica y la superestructura ideológica, en cuanto la ideología sólo son las condiciones materiales de existencia (la existencia se define como lo que es, lo que no es, lo que será, lo que no será, lo probable, lo posible y lo lógico) de períodos de tiempo pasados cristalizadas en el presente, bajo determinada teleología (causa final, finalidad, que en sociedades de clase, para el caso de la ideología dominante -que es la ideología que en promedio permea la sociedad-, es la alienación), en la cabeza de los individuos. No por ello significa que la superestructura no esté sometida, en última instancia, a la base económica, así como existe una retroalimentación de la misma índole entre la fuerza de trabajo y los medios de producción (siendo estos últimos crisálidas en el tiempo de la primera) y no por ello Marx afirmó que el capital podía crear valor, sino todo lo contrario como es (o debería ser) ampliamente conocido. Que la propiedad privada, tal como Marx replicó a Proudhon, no sea un robo sino una necesidad histórica, no significa que no puedan operarse robos a través de ella (entendiendo estos como apropiaciones de trabajo ajeno que no obedecen rigurosamente a necesidades de acumulación -es decir, sin las cuales las condiciones de reproducción se romperían-, sino que obedecen a motivos subjetivos del capitalista, explicados estos a su vez de forma objetiva por la psicología que genera la categoría económica que los capitalistas personifican, que imprime en ellos la necesidad de ser voraces, codiciosos y ambiciosos; puesto que la ética es parte de la superestructura y esta ya se definió en términos objetivos, materiales y temporales, no existe contradicción entre esta afirmación y lo antes expuesto). ¿Acaso el violento, mugriento y sangriento proceso de acumulación originaria de capital descrito por Marx (que no sólo ocurrió en Europa, también en toda América Latina, aunque con una fenomenología parcialmente diferente) no requiere de un sistema ético en la cabeza de los individuos que la llevaron a cabo?, ¿o es que acaso un consecuente y devoto monge franciscano, o un pacifista, podrían haber llevado a cabo un genocidio de tal índole y magnitud? Roma no terminó de ser Roma por las lanzas que llevaban sus legiones, sino por las ideas que esas legiones, con esas lanzas, imponían en la cabeza de los pueblos que conquistaban, más no por ello es menos cierto que esas lanzas existían gracias a las condiciones materiales de existencia del Imperio mismo.
Para que no quede duda de la afirmación anterior, el mismo articulista, que no se ruboriza al hablar de dialéctica sin citar a Hegel, ha expresado abiertamente en su blog (específicamente en respuesta a comentarios que yo esgrimí en una de sus publicaciones), que la ley de la tendencia decreciente de la tasa media de ganancia no es válida científicamente. Más allá que existen sobradas verificaciones empíricas de que esta tendencia es objetiva, verificaciones que no sólo provienen de escuelas marxistas que son antagónicas en su uso instrumental de las matemáticas (como la escuela temporalista y la escuela simultaneista, por ejemplo), sino también de macroeconometristas neoclásicos como Mankiw o Blanchard (este último fue economista jefe del Fondo Monetario Internacional, que representa la ortodoxia financiera a nivel institucional supranacional), afirmar eso es precisamente ser lego en lógica dialéctica; muchos economistas buscan emplear una lógica sublime (que termina siendo muchas cosas, menos sublime), pero olvidan que la realidad existe y que hay que “contaminarse” de ella. Lo anterior es así por cuanto la sociedad comunista sin clases es la teleología histórica-social de la humanidad desde la perspectiva de Marx y, para que ello se verifique, debe existir un fundamento material y objetivo de la inviabilidad a largo plazo del modo de producción capitalista, es precisamente este fundamento la ley de la tendencia decreciente de la tasa media de ganancia, ley que cualquier empresario que posea un cierto nivel mínimo de acumulación de capital y de elevada composición orgánica del mismo, comprende con total claridad. Esta ley, planteada por vez primera por Adam Smith (según el mismo Marx), no fue simplemente resultado observacional del comportamiento de los capitalistas en la época de Marx, tampoco fue simplemente el resultado de teorizar sobre los datos que Engels enviaba a Marx sobre la estructura y dinámica productiva de sus empréstitos fabriles (lo que puede ser verificado en la correspondencia entre ellos), tampoco fue una mera continuación de los postulados clásicos sobre dicha tendencia, es también el resultado lógico de la ingeniería inversa que Marx realiza al sistema hegeliano, por cuanto los valores (que en el sistema hegeliano son la esencia, esencia que Hegel retoma de Spinoza) son “diluidos” en un mecanismo (que Hegel crea sintetizando orgánicamente todos los sistemas filosóficos que le precedieron, especialmente el metafísico de Aristóteles, que es conciliado con los requerimientos instrumentales del sistema kantiano; para el caso del sistema económico capitalista es la competencia capitalista misma) en que la premisa se presenta depurada dialécticamente en el resultado (los precios de producción, para el caso del sistema económico capitalista). Establecido lo anterior (no sólo a nivel conceptual, sino a nivel de las estructuras matemáticas con que se representan), si la dinámica económica capitalista se estudia en presencia de perpetua innovación tecnológica (que es lo que ocurre en la realidad objetiva, por ejemplo, con el caso de los teléfonos inteligentes, por mostrar un ejemplo simple y cotidiano) es inexorable que la tasa media de ganancia del sistema caiga (capítulo XIII del tomo III de El Capital), aunque como también establecería Marx en los capítulos XIV y XV de la misma fuente citada, esta ley es contarrestada a causa del desarrollo de las contradicciones internas de los componentes integrantes. Los “marxistas” (a quienes es preciso, en términos gnoseológicos, mejor llamar neo-marxistas), no comprenden que el sistema de Marx, al igual que el sistema hegeliano, es “de una sola pieza” (indivisible, o conjunto conexo, como se conoce a ciertos sistemas de conjuntos en Matemáticas), puesto que la gran fortaleza del sistema de Marx es la unificación orgánica de la ontología (la doctrina del Ser), la lógica y la teoría del conocimiento, gnoseología o epistemología, de la misma forma en que en mecánica cuántica al hablar de “Momento” no se puede hablar del “Momento” de una de las fuerzas fundamentales de la Naturaleza, porque dentro de la integral a través de la cual se calcula dicho Momento, no es posible separar dentro de la función objetivo las fuerzas fundamentales a través de ella modelada, a diferencia de lo que ocurría en mecánica clásica en que sí es posible separar las fuerzas que actúan sobre un sistema físico (por ejemplo, una palanca). Esto expresa una ontología, una lógica y una gnoseología muy clara: que la Naturaleza es orgánica e indivisible a nivel de su esencia (entendiendo la esencia, al igual que Hegel, como el fundamento de la existencia), aunque por supuesto sea posible dividir las partículas que la componen a nivel local (y que incluso, como señaló Lenin en Materialismo y Empiriocriticismo, el potencial de esta división sea tendencialmente inagotable), puesto que si no fuese posible se incurriría en una visión leibniziana de la existencia, es decir, en una visión monista extrema. Se hace referencia a otro tipo de sistemas, porque cualquier persona que posee conocimientos básicos de dialéctica sabe que la misma es una metalógica multinivel recursiva hacia el pasado o, en términos más simples, que la verdad está en lo absoluto, en la totalidad.
Así, retomando lo relativo a las sociedades humanas, la teleología intra-histórica (a nivel de un modo de producción, en este caso el capitalista, que tiene como finalidad la acumulación, concentración y centralización de capital) se somete a la teleología inter-histórica, por cuanto el mismo proceso de acumulación de capital genera las condiciones para el derrumbe económico y político del capitalismo y el surgimiento, desde las mismas entrañas del capitalismo, de una nueva sociedad, de la sociedad comunista sin clases y con ello, como expresa Marx en el prólogo de Contribución a la Crítica de la Economía Política, se pondrá fin a la prehistoria de la humanidad y se dará comienzo a un nuevo ciclo de las sociedades humanas, superando el ciclo de las sociedades de clase (aunque este nuevo ciclo generado desde ellas, desde lo que se supera), generadas desde las sociedades sin clase (a causa de la precariedad tecnológica, lo cual se explica magistralmente en El Origen de la Familia, la Propiedad Privada y el Estado). Un mundo mejor es posible y no sólo es posible, sino que también se gestará y la lucha de clases será su partera, no como un hecho histórico que emanará esencialmente de la conciencia de los individuos, sino de la necesidad histórica (objetivas y materiales) de la sociedad humana en general (como establece Engels, la violencia es la partera de la Historia, lo cual ocurre también en física fundamental, por ejemplo, con el papel que los agujeros negros supermasivos al fondo de la galaxia desempeñan en las órbitras de los cuerpos celestes y estas últimas en el surgimiento de la vida, así como también a nivel más abstracto con los operadores de aniquilación halmitonianos de partículas), como la premisa que se presenta en el resultado de forma depurada y que determina dicho resultado, como una necesidad histórica que se cristalizará en la conciencia de los seres humanos cuando exista el suficiente grado de desarrollo de las fuerzas productivas del trabajo. En palabras de Marx, el monopolio feudal engendró la libre competencia capitalista, esta última engendró los monopolios capitalistas y, así, se establecen gradual y progresivamente (no sin retrocesos, puesto que la evolución dialéctica de la existencia en general y en particular ocurre a manera de espiral; Lenin señaló que concebir un desarrollo lineal, uniforme y sin retrocesos es antidialéctico, anticientífico y teóricamente falso) las condiciones para esa sociedad que dará luz, justicia y dignidad a los seres humanos, la sociedad de Rimbaud y Neruda, que hará que la poesía no haya cantado en vano.
Esta sección de la obra en construcción trata sobre los fundamentos del Marxismo en el contexto de la interpretación filosófica de la Mecánica Cuántica y de la Cosmología, específicamente sobre la interpretación dialéctica-materialista del colapso de onda y sobre el principio y fin del Universo.
Este, y otros capítulos antes subidos, pertenecen a un libro en proceso de construcción titulado “EL SISTEMA DIALÉCTICO-MATERIALISTA COMO PROGRAMA DE DEMARCACIÓN DE LAS CIENCIAS. CASO DE APLICACIÓN: LA DEFINICIÓN SUBJETIVA DEL VALOR DE LAS MERCANCÍAS COMO PRINCIPIO PSEUDOCIENTÍFICO“.
Este artículo busca estimular el debate sobre cómo valuar las mercancías siguiendo la interpretación temporal y de sistema único (TSSI, por sus siglas en inglés) de la teoría del valor de Marx. Sugiero que, aun cuando Andrew Kliman y Alan Freeman siguen la TSSI de Marx, sus enfoques sobre el cálculo del valor de las mercancías son distintos. Para ilustrar esta diferencia considero un modelo simple de una economía con acervos de mercancías no vendidas que se acarrean de un periodo al otro. Concluyo que esta diferencia en el enfoque indica cuán interesante sigue siendo la investigación sobre la TSSI de Marx.
Como señala (Kaplan, 1985, pág. 297), cuando se introducen coordenadas curvilíneas los métodos matriciales ya no resultan adecuados para el análisis de las operaciones vectoriales fundamentales. El análisis deseado se puede llevar a cabo con la ayuda de las estructuras matemáticas conocidas como tensores.
Los tensores son el resultado de un producto tensorial denotado como A⨂B. Un producto tensorial generaliza la noción de producto cartesiano o producto directo A × B y de suma directa A⨁B para espacios de coordenadas curvilíneas conocidos como variedades (como por ejemplo, las variedades pseudo-riemannianas bajo la cual está modelada la Teoría General de la Relatividad); lo anterior se afirma porque si se verifican las propiedades de un tensor u operador tensorial se podrá verificar que se comporta como una suma, pero su resultado (el espacio o conjunto generado) se comporta como una multiplicación. Esto está relacionado con poder generalizar nociones geométricas (que a nivel de matrices de datos tiene implicaciones en poder medir las longitudes entre los datos –y todo lo que eso implica, ni más ni menos que la base de las mediciones de todo tipo-), como por ejemplo la ortogonalidad entre vectores para una gama más general de superficies entre muchísimas otras cuestiones; de hecho, una variedad generaliza el concepto de superficie. En el lenguaje de programación R, un array multidimensional es un tensor, es decir, el resultado de un producto tensorial entre vectores, mientras que una matriz es resultado de un producto cartesiano entre vectores y es por ello que los primeros se pueden concebir geométricamente como un cubo n-dimensional o una estructura cúbica de medición con n-coordenadas, que además pueden ser curvilíneas. Una matriz es un tensor de dos dimensiones o coordenadas lineales.
Un vector es una flecha que representa una cantidad con magnitud y dirección, en donde la longitud de la flecha es proporcional a la magnitud del vector y la orientación de la flecha revela la dirección del vector.
También se puede representar con vectores otras cosas, como áreas y volúmenes. Para hacer esto, se debe hacer a la longitud del vector una magnitud proporcional a la magnitud del área a calcular y la dirección del vector debe ser ortogonal a la superficie o región de la cual se desea estimar el área o volumen.
Los vectores base o vectores unitarios (cuando la base del espacio lineal es canónica, es decir, que cada vector que conforma la base está compuesto en su pertinente coordenada por la unidad y en el resto por ceros) tienen longitud 1. Estos vectores son los vectores directores del sistema de coordenadas (porque le dan dirección a cada uno de los ejes del plano, puesto que precisamente cada uno representa un eje).
Para encontrar los componentes de un vector (en el caso de un sistema de tres coordenadas, el componente x, el componente y, el componente z) se proyecta el vector sobre el eje que corresponde al componente a encontrar, por ejemplo, si se desea encontrar el componente x del vector, la proyección se realiza sobre X. Entre mayor sea el ángulo entre un vector y un eje de referencia (X,Y,Z), menor será la magnitud del componente correspondiente a dicho eje (este componente, en este ejemplo, puede ser x, y o z); el inverso también es cierto. La magnitud de cualquier vector dentro del plano real o complejo puede determinarse como combinación lineal de los vectores base con el campo de los reales o los complejos, respectivamente. Esto implica que la magnitud de un vector (y por consiguiente de los componentes dentro del mismo, al ser una estructura lineal) puede expresarse como determinada cantidad de vectores unitarios (de longitud 1) de los diferentes ejes de coordenadas, en donde cada componente del vector se expresará unívocamente en una cantidad determinada de vectores unitarios del eje correspondiente a dicho componente.
Para generalizar los resultados anteriores a un vector de vectores A (que entre otras cosas permite agruparlos en una misma estructura matemática -por ello a nivel del programa R los arrays tienen contenido del mismo tipo y relacionado entre sí[1]-), se establece que dicho vector A tendrá los componentes A_X, A_Y, A_Z, que representan a los componentes X, Y y Z, respectivamente. Se requiere establecer un índice para cada vector (el índice es en este caso el subíndice) porque sólo existe un indicador direccional (es decir, un vector base) por componente (porque cada componente se corresponde con su respectivo eje).
Esto es lo que hace a los vectores ser tensores de rango 1, que tienen un índice o un vector base por componente. Bajo la misma lógica, los escalares pueden ser considerados tensores de rango cero, porque los escalares no tienen ningún indicador direccional (son una cantidad con magnitud, pero sin sentido) y, por consiguiente, no necesitan índice.
Los tensores son combinaciones entre componentes auxiliares de naturaleza diversa (parámetros, coeficientes, pendientes, que son en última instancia algún elemento de algún campo escalar o anillo) y componentes centrales (los miembros de la base del espacio vectorial o módulo, que expresan las variables fundamentales del sistema que se describe), que sirven para estimar de forma más robusta (en términos de precisión cuantitativa y especificidad cualitativa) las coordenadas de un sistema de referencia.
El número de índices de cada tensor será igual al número de vectores base por componente (en el caso de los tensores, los componentes y los vectores base no tienen necesariamente una relación uno-a-uno, por lo que a un componente le puede corresponder más de un vector base o vector director del sistema de coordenadas).
Considérense, por ejemplo, las fuerzas que actúan al interior de un objeto sólido cualquiera en un espacio de tres dimensiones. Este interior está segmentado en términos de superficies (que son regiones de dicho espacio a manera de planos) por los vectores base de tipo área X, Y, Z. Asúmase además que cada una de las fuerzas actúa en cada una de las regiones del espacio (esto no necesariamente es así, sólo se usa un ejemplo así para que sea más fácilmente capturable a la intuición; aunque lógico-formalmente sí es así, filosóficamente y en términos de las ciencias aplicadas no necesariamente). Lo anterior significa que, debido a la diferente dirección de los vectores base, la acción de dichas fuerzas tiene orientaciones diferentes según la región del espacio de la que se trate. Esto es así porque cada vector base tiene una dirección diferente (al menos si su dirección se estudia cuando está anclado al origen) y cada vector base determina la dirección de la acción de cada fuerza en la región del espacio que a dicho vector base le corresponde (una región -lo que de forma más general puede concebirse como una caracterización dentro de un sistema referencial- estudiada puede estar compuesta por subregiones bajo el efecto de fuerzas diferentes). Así, para poder caracterizar completamente las fuerzas que actúan dentro del objeto sólido (lo que equivale precisamente a caracterizar completamente al objeto sólido mismo -bajo las limitaciones que la teoría tiene frente a la práctica-), es necesario que cada fuerza pueda ser expresada en términos de todas las regiones del espacio en las que actúa (cada región se corresponde con un vector director o vector base), por lo que cada fuerza se debe vincular a la correspondiente cantidad regiones del sólido en las que actúa (se debe vincular a la correspondiente cantidad de vectores base a los que está asociada).
Así, los tensores permiten caracterizar completamente todas las fuerzas posibles y todas las regiones posibles sobre las que actúan tales fuerzas.
Los tensores permiten que todos los observadores en todos los sistemas de coordenadas de referencia (marco referencial, de ahora en adelante) puedan estar de acuerdo sobre las coordenadas establecidas. El acuerdo no consiste en un acuerdo sobre los vectores base (que pueden variar de un espacio a otro), tampoco en los componentes (que pueden variar según el campo escalar), sino en las combinaciones entre vectores base y componentes. La razón de lo anterior radica en que al aplicar una transformación sobre los vectores base (para pasar de un sistema referencial a otro de alguna forma equivalente), en el contexto de los tensores, la estructura algebraica resultante tendrá invariablemente una única dirección sin importar el marco referencial; por su parte, al transformar un componente se logran mantener las combinaciones entre componentes y vectores base para todos los observadores (i.e., para todos los marcos referenciales -cada observador está en un marco referencial-).
Por tanto, los tensores expresan matemáticamente (i.e., lógico-formalmente) la unidad a nivel del fenómeno (social o natural) de las fuerzas contrarias entre sí que lo componen, así como también la tensión que implica la lucha de tales fuerzas por imponerse la una a la otra durante el proceso evolutivo del fenómeno estudiado.
Como se señala en (Universidad de Granada, 2022), en el contexto de la estadística aplicada, un array es un tipo de dato estructurado que permite almacenar un conjunto de datos homogéneo, es decir, todos ellos del mismo tipo y relacionados. Cada uno de los elementos que componen un vector pueden ser de tipo simple como caracteres, entero o real, o de tipo compuesto o estructurado como son vectores, estructuras, listas.
A los datos almacenados en un array se les denomina elementos; al número de elementos de un array se les denomina tamaño o rango del vector; este rango puede determinarse de forma equivalente, en el caso de arrays multidimensionales (tensores), a través del número de ejes. Para acceder a los elementos individuales de un array se emplea un índice que será un número entero no negativo que indicará la posición del elemento dentro del array. Para referirse a una posición particular o elemento dentro del array, se especifica el nombre del array y el número de posición del elemento particular dentro del mismo, el índice.
Los arrays en gran parte se definen como las variables ordinarias, excepto en que cada array debe acompañarse de una especificación de tamaño (número de elementos). Para un array unidimensional, el tamaño se especifica con una expresión entera positiva encerrada entre paréntesis cuadrados. La expresión es normalmente una constante entera positiva.
En suma, cada dimensión de un tensor/array multidimensional (que, al ser en sí mismo una estructura de datos con las propiedades usuales de los números, es también un espacio vectorial, específicamente un espacio euclidiano) está compuesta por un número de filas y columnas especificado.
En la mayoría de los casos, los tensores se pueden considerar como matrices anidadas de valores que pueden tener cualquier número de dimensiones. Un tensor con una dimensión se puede considerar como un vector, un tensor con dos dimensiones como una matriz y un tensor con tres dimensiones se puede considerar como un paralelepípedo. El número de dimensiones que tiene un tensor se llama su rango y la longitud en cada dimensión describe su forma. El rango de un tensor es el número de índices necesarios para seleccionar de forma única cada elemento del tensor (TensorFlow, 2022). El rango también se conoce como “orden” o “grado”; como se señaló antes, otra forma de ver los tensores es como arrays multidimensionales (RStudio, 2022).
Como señala (Weisstein, 2022), formalmente hablando el rango de un tensor es el número total de índices contravariantes y covariantes de un tensor, relativos a los vectores contravariantes y covariantes, respectivamente. El rango R de un tensor es independiente del número de dimensiones N del espacio subyacente en el que el tensor se localice. Adicionalmente, se señala en la documentación R sobre el paquete ‘tensor’, que el producto tensorial de dos arrays es teóricamente un producto exterior de tales arrays colapsados en extensiones específicas al sumar a lo largo de las diagonales apropiadas. Por ejemplo, un producto matricial es el producto tensorial a lo largo de la segunda extensión de la primera matriz y la primera extensión de la segunda matriz.
Fuente: (java T point, 2022).Fuente: (java T point, 2022).Fuente: (java T point, 2022).Fuente: (geeksforgeeks, 2022).Fuente: (Patidar, 2019).Fuente: (Paul, 2018).
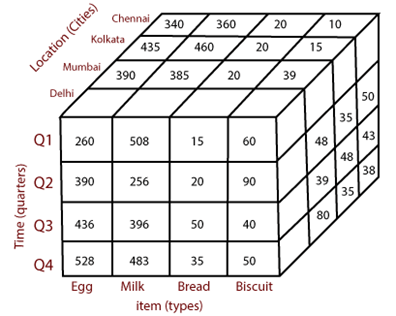
En el modelo de datos multidimensional, los datos se organizan en una jerarquía que representa diferentes niveles de detalles. Un modelo multidimensional visualiza los datos en forma de cubo de datos. Un cubo de datos permite modelar y visualizar datos en múltiples dimensiones. Se define por dimensiones y hechos.
Las dimensiones son las perspectivas o entidades sobre las cuales una organización mantiene registros. Por ejemplo, una tienda puede crear un almacén de datos de ventas para mantener registros de las ventas de la tienda para la dimensión de tiempo, artículo y ubicación. Estas dimensiones permiten registro para realizar un seguimiento de las cosas, por ejemplo, las ventas mensuales de artículos y las ubicaciones en las que se vendieron los artículos. Cada dimensión tiene una tabla relacionada con ella, llamada tabla dimensional, que describe la dimensión con más detalle.
Universidad de Granada. (25 de Marzo de 2022). Arrays y cadenas. Obtenido de Departamento de Ciencias de la Computación e Inteligencia Artificial de la Universidad de Granada: https://ccia.ugr.es/~jfv/ed1/c/cdrom/cap5/f_cap52.htm.
# PROCESO DE SELECCIÓN DE VARIABLES EXPLICATIVAS
## Introducción: Sobre la necesidad de un proceso de selección de predictores
Usualmente se tiene interés en explicar los datos de la forma más simple, lo cual en el contexto de la teoría de las probabilidades (especialmente en la teoría bayesiana de probabilidades) se conoce como el *principio de parsimonia*, el cual está inspirado en el principio filosófico conocido como *navaja de Ockham*, la cual establece que en igualdad de condiciones la explicación más simple suele ser la más probable. El principio de parsimonia adopta diferentes formas según el área de estudio del análisis inferencial en el que se encuentre un investigador. Por ejemplo, una parametrización parsimoniosa es aquella que usa el número óptimo de parámetros para explicar el conjunto de datos de los que se dispone, pero "parsimonia" también puede referirse a modelos de regresión parsimoniosos, es decir, modelos que utilizan como criterio de optimización emplear la mínima cantidad de coeficientes de regresión para explicar una respuesta condicional Y. El principio de parsimonia, los procesos matemáticos de optimización regidos por el criterio de alcanzar un mínimo y la navaja de Ockham son un mismo tipo de lógica aplicado en escalas de la existencia (que podríamos llamar en general "materia", como lo hace Landau en sus curso de física teórica) cualitativamente diferentes. La historia de la Filosofía demuestra que el único sistema que podría ser aplicado así exitosamente es el sistema hegeliano (lo que obedece a que parcialmente sigue la lógica de la existencia misma, como han demostrado Marx, Engels, Lenin, Levins, Lewontin y el mismo Hegel en su extensa obra). ¿Cómo es posible la vinculación en distintas escalas cualitativas de la realidad del principio de la navaja de Ockham? A que todas esas ideas responden a la escuela filosófica de Ockham, que era la escuela nominalista. Retomando lo que señalan (Rosental & Iudin. Diccionario Filosófico, Editorial Tecolut, 1971. p.341; véase https://www.filosofia.org/enc/ros/nom.htm), el nominalismo fue una corriente de la filosofía medieval que consideraba (ya es una escuela extinta) que los conceptos generales tan sólo son nombres de los objetos singulares. Los nominalistas afirmaban que sólo poseen existencia real las cosas en sí, con sus cualidades individuales (es decir, las generalizaciones para ellos no tenían valor gnoseológico en sí mismas sino como recurso gnoseológico). Los nominalistas van más allá, planteando que las generalizaciones no sólo no existen con independencia de los objetos particulares (esta afirmación en correcta, lo que no es correcto es pensar que lo inverso sí es cierto), sino que ni siquiera reflejan las propiedades y cualidades de las cosas. El nominalisto se hallaba indisolublemente vinculado a las tendencias materialistas, ya que reconocía la prioridad de la cosa y el carácter secundario del concepto. Por supuesto, las generalizaciones aunque menos reales que los objetos particulares (y de ahí la sujeción de la teoría a la práctica en un concepto que las une conocido en la teoría marxista como *praxis*) no deja por ello de ser real en cuanto busca ser una representación aproximada (a largo plazo cada vez más aproximada a medida se desarrollan las fuerzas productivas) de la estructura general (interna y externa, métrica y topológica) común que tienen tales fenómenos naturales o sociales. Marx señaló que el nominalismo fue la primera expresión del materialismo de la Edad Media. Con todo, los nominalistas no comprendían que los conceptos generales reflejan cualidades reales de cosas que existen objetivamente y que las cosas singulares no pueden separarse de lo general, pues lo contienen en sí mismas (y esto no tiene un carácter únicamente marxista, sino que incluso el célebre formalista David Hilbert señaló, según la célebre biógrafa de matemáticos Constance Reid que "The art of doing mathematics consists in finding that special case which contains all the germs of generality"). Así, el defecto fundamental de la navaja de Ockham es el no considerar algún conjunto de restricciones que complementen al criterio de selección de la explicación basado en que sea la idea más simple. Como se señala en https://www.wikiwand.com/en/Occam%27s_razor,
"En química, la navaja de Occam es a menudo una heurística importante al desarrollar un modelo de mecanismo de reacción (...) Aunque es útil como heurística en el desarrollo de modelos de mecanismos de reacción, se ha demostrado que falla como criterio para seleccionar entre algunos modelos publicados seleccionados (...) En este contexto, el propio Einstein expresó cautela cuando formuló la Restricción de Einstein: "Difícilmente se puede negar que el objetivo supremo de toda teoría es hacer que los elementos básicos irreductibles sean tan simples y tan pocos como sea posible sin tener que renunciar a la representación adecuada de un dato único de experiencia"."
La clave en la expresión anterior de Einstein es "sin tener que renunciar a...", lo que se cristaliza nítidamente en una frase que señala la fuente citada es atribuida a Einstein, pero no ha sido posible su verificación: "Todo debe mantenerse lo más simple posible, pero no lo más simple". Como se verifica en https://www.statisticshowto.com/parsimonious-model/, en general, existe un *trade-off* entre la bondad de ajuste de un modelo y la parsimonia: los modelos de baja parsimonia (es decir, modelos con muchos parámetros) tienden a tener un mejor ajuste que los modelos de alta parsimonia, por lo que es necesario buscar un equilibrio.
La parsimonia estadística es deseada porque un mínimo de coeficientes de regresión implica un mínimo de variables y un mínimo de estos implica un mínimo de variables explicativas, lo que puede ser útil en casos de que exista colinealidad entre las variables explicativas, así como también permite ahorrar tiempo y dinero en lo relativo a la inversión de recursos destinada al estudio, aunque no necesariamente garantice que en general (considerando el impacto posterior de las decisiones tomadas con base en el estudio y otros factores) se ahorre tiempo y dinero.
## Modelos Jerárquicos
Existen diferentes tipos de modelos jerárquicos. Los hay de diferente tipo, algunos más complejos que otros (complejidad a nivel teórico, matemático y computacional); ejemplos de tales modelos son las mixturas de probabilidad y se pueden estudiar en https://marxistphilosophyofscience.com/wp-content/uploads/2020/12/sobre-los-estimadores-de-bayes-el-analisis-de-grupos-y-las-mixturas-gaussianas-isadore-nabi.pdf. Aquí se tratará con modelos jerárquicos más simples, como los abordados en (Kutner, Nachtsheim, Neter & Li. p.294-305).
Como señalan los autores referidos en la p.294., los modelos de regresión polinomial tienen dos tipos básicos de usos: 1. Cuando la verdadera función de respuesta curvilínea es de hecho una función polinomial. 2. Cuando la verdadera función de respuesta curvilínea es desconocida (o compleja), pero una función polinomial es una buena aproximación a la función verdadera. El segundo tipo de uso, donde la función polinomial se emplea como una aproximación cuando se desconoce la forma de la verdadera función de respuesta curvilínea, es muy común. Puede verse como un enfoque no paramétrico para obtener información sobre la forma de la función que modela la variable de respuesta. Un peligro principal en el uso de modelos de regresión polinomial es que las extrapolaciones pueden ser peligrosas con estos modelos, especialmente en aquellos con términos de orden superior, es decir, en aquellos cuyas potencias sean iguales o mayores a 2. Los modelos de regresión polinomial pueden proporcionar buenos ajustes para los datos disponibles, pero pueden girar en direcciones inesperadas cuando se extrapolan más allá del rango de los datos.
Así, como señalan los autores referidos en la p.305, el uso de modelos polinomiales no está exento de inconvenientes. Estos modelos pueden ser más costosos en grados de libertad que los modelos no-lineales alternativos o los modelos lineales con variables transformadas. Otro inconveniente potencial es que puede existir multicolinealidad grave incluso cuando las variables predictoras están centradas. Una alternativa al uso de variables centradas en la regresión polinomial es usar polinomios ortogonales. Los polinomios ortogonales están no-correlacionados, puesto que la ortogonalidad de sus términos implica independencia lineal entre los mismos. Algunos paquetes de computadora usan polinomios ortogonales en sus rutinas de regresión polinomial y presentan los resultados ajustados finales en términos tanto de los polinomios ortogonales como de los polinomios originales. Los polinomios ortogonales se discuten en textos especializados como (Drapper & Smith, Applied Linear Regression). A veces, se ajusta una función de respuesta cuadrática con el fin de establecer la linealidad de la función de respuesta cuando no se dispone de observaciones repetidas para probar directamente la linealidad de la función de respuesta.
## Caso de Aplicación
### 1. Conversión de Matriz de Datos a Marco de Datos
La base ´Vida.Rdata´ contiene datos para los 50 estados de los Estados Unidos. Estos datos son proporcionados por U.S. Bureau of the Census. Se busca establecer las relaciones que existen entre ciertas variables del Estado que se analice y la esperanza de vida. A continuación, se presenta una descripción de las variables que aparecen en la base en el orden en que
aparecen:
+ **esper**: esperanza de vida en años (1969-71).
+ **pob**: población al 1 de Julio de 1975.
+ **ingre**: ingreso per capita (1974).
+ **analf**: porcentaje de la población analfabeta (1970).
+ **crim**: tasa de criminalidad por 100000 (1976).
+ **grad**: porcentaje de graduados de secundaria (1970).
+ **temp**: número promedio de días con temperatura mínima por debajo de los 32 grados (1931-1960) en la capital del estado.
+ **area**: extensión en millas cuadradas.
Debe comenzarse leyendo el archivo de datos pertinente mediante la sintaxis `load("Vida.Rdata")`. Si se observa la estructura de la base de datos, se verifica que es simplemente una matriz. Por tanto, si se utiliza la sintaxis `names(base)` no se obtiene información alguna, mientras que si se trata de llamar a alguna de las variables por su nombre, como por ejemplo `base$esper`, R informa de un error y lo mismo ocurre si se usa `attach(base)`. Esto sucede porque la estructura de datos invocada no está definida como un marco de datos o `data.frame`. Por ello, debe comenzarse por convertir dicha matriz de datos en un marco de datos o `data.frame`y posteriormente puede verificarse si las sintaxis antes mencionadas son ahora operativas.
“`{r} setwd(“C:/Users/User/Desktop/Carpeta de Estudio/Mis Códigos en R”) load(“Vida.Rdata”) names(base) base=data.frame(base) names(base) “`
### 2. Obtención de todos los modelos posibles dado un determinado conjunto de variables dentro del marco de datos
Pueden obtenerse los $R^2$ ajustados de todos los modelos posibles con las 7 variables disponibles. Para hacerlo, puede construirse primero un objeto con todos los predictores y llamarlo **X** para posteriormente construir un objeto llamado **sel** aplicando la función `leaps` (perteneciente a la librería con el mismo nombre) de la siguiente forma: `sel=leaps(x,y, method="adjr2")`. Nótese que el objeto construido mediante la sintaxis `leaps`, es decir, **sel**, es una lista con 4 componentes cuyos nombres pueden obtenerse con la sintaxis `names(sel)`. Así, puede llamarse a cada uno de tales componentes por separado usando el signo `$`, por ejemplo, `sel$which`. Antes de proceder a realizar los cálculos definidos antes, se estudiará a nivel general la sintaxis `leaps`.
La sintaxis `leaps` usa un algoritmo eficiente (parsimonioso) de ramificación y cota para realizar una búsqueda exhaustiva de los mejores subconjuntos de las variables contenidas en el marco de datos para predecir y realizar análisis de regresión lineal; este tipo de algoritmo, según https://www.wikiwand.com/en/Branch_and_bound, es un paradigma de diseño de algoritmos para problemas de optimización discreta y combinatoria, así como optimización matemática. Un algoritmo de ramificación y acotación consiste en una enumeración sistemática de soluciones candidatas mediante la búsqueda en el espacio de estados: se piensa que el conjunto de soluciones candidatas forma un árbol enraizado con el conjunto completo en la raíz; "si las cosas fuesen tal y como se presentan ante nuestros ojos, la ciencia entera sobraría" dijo Marx alguna vez. El algoritmo explora las ramas del árbol representado por los subconjuntos del conjunto de soluciones posibles al problema de optimización. Antes de enumerar las soluciones candidatas de una rama, el algoritmo sigue el siguiente proceso descarte de ramas: la rama se compara con los límites estimados superior e inferior de la solución óptima y se descarta (la rama en su conjunto) si no ella puede producir una solución mejor que la mejor encontrada hasta ahora por el algoritmo (véase https://cran.r-project.org/web/packages/leaps/leaps.pdf, p.1). Como se señala en la documentación antes citada, dado que el algoritmo devuelve el mejor modelo de cada tamaño (aquí se refiere a los modelos estadísticamente más robustos según un número de variables fijo que se considere) no importa si desea utilizar algún criterio de información (como el AIC, BIC, CIC o DIC). El algoritmo depende de una estimación eficiente de los límites superior e inferior de las regiones/ramas del espacio de búsqueda. Si no hay límites disponibles, el algoritmo degenera en una búsqueda exhaustiva.
A pesar de lo señalado relativo a que la búsqueda realiza por `leaps` es independiente de cualquier criterio de información utilizado, puede omitirse este hecho con la finalidad de que sea posible incorporar a esta práctica el estudio de los criterios de información. A continuación, se presenta una lista de los mejores modelos siguiendo el criterio de $R^2$ ajustado más alto, lo que se indica al interior de la sintaxis `leaps` mediante methods="adjr2".
Adicionalmente, es posible construir una matriz, almacenarla bajo el nombre **mat** con el contenido de las filas `sel$which` y `sel$adjr2`, agregando un contador para identificar cada modelo mediante la sintaxis `cbind`. La estructura de datos **mat** contiene todos los diferentes modelos de regresión lineal (a diferentes tamaños de los mismos) mediante la sintaxis `leaps` para la base de datos utilizada.
“`{r} k=nrow(sel$which) k mat=data.frame(cbind(n=1:k,sel$which,round(sel$adjr2,2))) mat
head(mat[order(-mat$V9),],10) “`
Así, puede construirse un subconjunto de **mat** que contenga sólo los modelos cuyo coeficiente de determinación ajustado sea mayor o igual que 0.68.
Nótese que los cuatro modelos con el $R^2$ ajustado más alto son los modelos 28, 38, 39, y 40, cuyo tamaño oscila entre 4 o 5 variables explicativas; si se utiliza la sintaxis `print` es posible verificar que en las filas está el modelo como tal (si la variable se toma en consideración tiene asignado un "1", mientras que en caso contrario un "0"), mientras que en las columnas se localizan las posibles variables a utilizar.
### 3. Estadístico de Mallows
Como se puede verificar en https://support.minitab.com/es-mx/minitab/18/help-and-how-to/modeling-statistics/regression/supporting-topics/goodness-of-fit-statistics/what-is-mallows-cp/, el Estadístico $C_p$ de Mallows sirve como ayuda para elegir entre múltiple modelos de regresión. Este estadístico ayuda a alcanzar un equilibrio importante con el número de predictores en el modelo. El $C_p$ de Mallows compara la precisión y el sesgo del modelo completo con modelos que incluyen un subconjunto de los predictores. Por lo general, deben buscarse modelos donde el valor del $C_p$ de Mallows sea pequeño y esté cercano al número de predictores del modelo más la constante $p$. Un valor pequeño del $C_p$ de Mallows indica que el modelo es relativamente preciso (tiene una varianza pequeña) para estimar los coeficientes de regresión verdaderos y pronosticar futuras respuestas. Un valor del $C_p$ de Mallows que esté cerca del número de predictores más la constante indica que, relativamente, el modelo no presenta sesgo en la estimación de los verdaderos coeficientes de regresión y el pronóstico de respuestas futuras. Los modelos con falta de ajuste y sesgo tienen valores de $C_p$ de Mallows más grandes que p. A continuación se presenta un ejemplo.
#Figura 1: Ejemplo del uso del Estadístico de Mallows para evaluar un modelo #Fuente: https://support.minitab.com/es-mx/minitab/18/help-and-how-to/modeling-statistics/regression/supporting-topics/goodness-of-fit-statistics/what-is-mallows-cp/
Así, para el ejemplo aquí utilizado (que responde a la base de datos antes especificada) puede obtenerse el estadístico $C_p$ de Mallows para todos los modelos posibles con las 7 variables disponibles. Para ello puede usarse la función `leaps`; nótese que no es necesario indicarle a R que obtenga el estadístico de Mallows mediante la sintaxis `method=Cp` puesto que este método es el establecido por defecto en la programación de R, por lo que en el escenario en que no se indique un "method" en específico el programa utilizará por defecto el criterio del estadístico de Mallows.
“`{r} sel = leaps(X,esper) names(sel) sel$Cp “`
Complementariamente, puede construirse una nueva matriz **mat** que en lugar de los criterios `sel$which` y `sel$adjr2` siga los criterios `sel$which`, `sel$Cp` y `sel$size`, agregando al igual que antes un contador para identificar cada modelo. Esto implicará la sobreeescritura de la matriz **mat**. Pueden seleccionarse con antelación únicamente las filas de **mat** que se corresponden con los modelos seleccionados en el punto anterior y comparar la columna del $C_p$ con la columna $size$ que corresponde al número de coeficientes (p). En cada caso puede determinarse si el modelo es sesgado o no, sin perder de vista que un modelo es sesgado según el estadístico de Mallows si $C_p>p$. De lo anterior se desprende que se está buscando un conjunto de modelos insesgados para los cuales se verifica la condición $C_p<p$ antes mencionada.
Como puede observarse, en todos los modelos arrojados por la sintaxis `leaps` cumplen con la condición antes especificada, por lo que es posible afirmar que, sobre todo respecto a los modelos 28, 38, 39 y 40, que son buenos candidatos para ser utilizados (los mejores modelos son los mismos cuatro que en el literal anterior).
### 4. Suma de Cuadrados Residuales de Predicción (PRESS)
####4.1. Aproximación Gráfica
Como se señala en (https://pj.freefaculty.org/guides/stat/Regression/RegressionDiagnostics/OlsHatMatrix.pdf, p.9), la PRESS no es otra cosa que el error de estimación correspondiente a un valor particular de la variable condicional $Y$; la estimación de PRESS a veces es útil como una medida resumida de la capacidad de un modelo para predecir nuevas observaciones. Las líneas de comando presentadas a continuación expresan la configuración de la función personalizada `plot.press`, que es una función empírica que se aproxima gráficamente a los PRESS mediante el siguiente procedimiento:
a) Crea un modelo solamente con la variable **ingre**.
b) Toma el Estado i-ésimo y crea otro modelo basado en los demás Estados (excepto el i-ésimo).
c) Grafica las dos líneas de regresión y marca la observación del Estado i-ésimo en rojo para que se observe como se diferencian las dos líneas a la altura del ingreso de ese Estado.
d) Estima el promedio de la esperanza de vida para el i-ésimo Estado usando las dos ecuaciones.
“`{r} plot.press=function(i){ mod =lm(esper~ingre,base) mod1=lm(esper ~ ingre,base[-i,])
plot(base$ingre,base$esper,pch=18,xlab=”ingreso”,ylab=”esperanza”) points(base$ingre[i],base$esper[i],pch=18,col=2) abline(mod) abline(mod1,lty=2,col=2) abline(v=base$ingre[i],col=4,lty=2) legend(3000,max(esper),c(“completo”,paste(“falta el “,i,sep=””)),col=c(1,2),lty=c(1,2),bty=”n”)
#### 4.2. Aproximación Inferencial vía Residuos Estandarizados
Como señala https://www.statisticshowto.com/what-is-a-standardized-residuals/, los residuos estandarizados permiten normalizar el conjunto de datos de estudio en el contexto del análisis de regresión y de la ejecución de pruebas de hipótesis chi-cuadrado $χ^2$. Un residuo estandarizado es una razón: la diferencia entre el valor observado y el valor esperado (condicional, a posteriori) sobre la desviación estándar del valor esperado en la prueba de chi-cuadrado.
Como se señala en https://online.stat.psu.edu/stat501/lesson/11/11.4, existen varias medidas para identificar valores extremos de X (observaciones de alto $leverage$ o $influencia$) y valores de Y inusuales (valores atípicos). Al intentar identificar valores atípicos, un problema que puede surgir es cuando existe un valor atípico potencial que influye en el modelo de regresión hasta tal punto que la función de regresión estimada se "arrastrada" hacia el valor atípico potencial, de modo que no se marca como un valor atípico utilizando el criterio usual de residuos estandarizados. Para abordar este problema, los residuos eliminados ofrecen un criterio alternativo para identificar valores atípicos. La idea básica de esto es eliminar las observaciones una a la vez, reajustando cada vez el modelo de regresión en las n – 1 observaciones restantes. Luego, se comparan los valores de respuesta observados con sus valores ajustados basados en los modelos con la i-ésima observación eliminada. Esto produce residuos eliminados (no estandarizados). La estandarización de los residuos eliminados produce residuos eliminados studentizados, como se verá teóricamente a continuación.
Formalmente, es un resultado conocido del álgebra lineal que $y=Xβ+ε$, en donde $X_{n×p}$, $\hat{β}=(X'X)^{-1}X-y$ y $\hat{y}=X\hat{β}=X(X'X)^{-1}X'y=Hy$, donde $H=X(X'X)^{-1}X'$ es la matriz conocida como *matriz sombrero*. Los residuos son $e=y-\hat{y}=y-Hy=(I-H)y$. Adicionalmente, se sabe que la varianza poblacional $σ^2$ es desconocida y puede estimarse mediante la suma de cuadrados medios del error $MSE$. Así, los residuos pueden ser expresados mediante la ecuación $e_i^*=\frac{e_i}{\sqrt{MSE}}$ y se conocen como *residuos semistudentizados*. Puesto que la varianza de los residuos depende tanto de $σ^2$ como de $X$, la varianza estimada es $\hat{V}(e_i)=MSE(1-h_{ii})$, donde $h_{ii}$ es el $i$-ésimo elemento de la diagonal principal de la matriz sombrero. Así, los residuos estandarizados, también conocidos como *residuos internamente studentizados*, tienen la forma $r_i=\frac{e_i}{\sqrt{MSE(1-h_{ii})}}$. Sin embargo, se sabe que es imposible que un residuo individual y el MSE (que es la varianza del conjunto de residuos) no estén correlacionados (existe dependencia lineal) y, por consiguiente, es imposible que $r_i$ siga una distribución t de Student. Lo anterior representa un impedimento para realizar pruebas de significancia estadística de los coeficientes de regresión, puesto que la distribución t es junto con la F los dos tipos de distribución más utilizados (y no sólo en el contexto de regresión) para realizar pruebas de hipótesis, dentro de las cuales las pruebas de significancia de coeficientes son un tipo de ellas. La solución a la problemática antes descrita consiste en eliminar la $i$-ésima observación, ajustar la función de regresión a las $n-1$ observaciones restantes y luego obtener nuevas $\hat{y}$'s que pueden ser denotadas como $\hat{y}_{i(i)}$. La diferencia $d_i=y_i-\hat{y}_{i(i)}$ es llamada *residuo eliminado*. Una expresión equivalente que no requiere recomputación es: $d_i=\frac{e_i}{1-h_{ii}}$.
Los residuos eliminados expresados de la forma anterior son la base para encontrar los residuos conocidos como *residuos eliminados studentizados* o *resiudos studentizados externamente*, los cuales adoptan la forma $t_i=\frac{d_i}{\sqrt{{\frac{MSE}{1-h_{ii}}}}}\sim{\sf t_{n-p-1}}$ o $t_i=\frac{e_i}{\sqrt{{{MSE(1-h_{ii})}}}}\sim{\sf t_{n-p-1}}$; véase https://stats.stackexchange.com/questions/99717/whats-the-difference-between-standardization-and-studentization/99723.
En lo que a la estimación de los diferentes tipos de residuos se refiere, debe comenzarse por obtener las **influencias** o **leverage** del modelo usando `hatvalues(mod)`; debe recordarse que las influencias son utilizadas para determinar que tanto impacto tiene una observación sobre los resultados de la regresión. Precisamente el análisis descriptivo anterior, en el que en una de las rectas de regresión (de las dos que aparecen en cada una de las cincuenta gráficas posibles) se omitía un Estado, tenía como finalidad verificar cuánto impactaba su ausencia (la del Estado sustraido) en la estimación realizada sobre la media condicional de $Y$. Al utilizar la sintaxis "mod=lm(esper~ingre,base)" se está planteando un modelo con la totalidad de Estados, del cual se calculan sus valores sombrero mediante la sintaxis `h = hatvalues(mod)`, sus residuos mediante `r=mod$res`, se estima el residuo de un modelo en el que no se considera el Estado i-ésimo en el análisis (en este caso Alaska) mediante `pred.r = r[2]/(1-h[2])` y, finalmente, la validez estadística de la estimación `pred.r = r[2]/(1-h[2])` se determina contrastándola con respecto al resultado de restarle a la media estimada $\hat{Y}_2$ (porque en este caso para Alaska, que ocupa la fila dos en la base de datos, que es una base de datos de corte transversal) la media estimada $\hat{Y}$ del modelo que no considera al i-ésimo Estado (aquí es Alaska).
“`{r} mod=lm(esper~ingre,base) h = hatvalues(mod) r=mod$res pred.r = r[2]/(1-h[2]) round(pred.r,2)
esper[2]-73.07
plot.press(2) “`
Finalmente, puede obtenerse la Suma de Cuadrados Residuales de Predicción $PRESS$ utilizando los residuos eliminados globales (no únicamente para el Estado de Alaska) mediante la siguiente ecuación: $$PRESS=\sum{( \frac{r_i}{1-h_i}} )^2$$.
“`{r} d=r/(1-h) press=t(d)%*%d round(press,2) “`
### 5. Comparación de Modelos vía $PRESS$
Es posible comparar el modelo que únicamente contempla la variable ingreso **ingre** con el que se obtiene en un modelo que contenga en su lugar la cantidad de población del Estado **pop** y su tasa de criminalidad **crim**. Esto con el fin de verificar cuál de los dos modelos es más sensible a valores extremos de X al realizar estimaciones de la media condicional $\hat{Y}$ de la variable *esperanza de vida*.
Se observa que el modelo `mod` es más sensible, puesto que su PRESS es más alto (89.32).
Debe decirse que la matriz "d" es conocida también como *matriz de Gramm*, por lo que su determinante es igual al producto de sí y su transpuesta, es decir, `t(d)%*%d`. Como se verifica en https://www.wikiwand.com/en/Gram_matrix, la matriz de Gramm cuyos elementos pertenecen a los reales tiene la característica de ser simétrica (matriz cuadrada que es igual a su transpuesta); la matriz de Gramm de cualquier base ortonormal (conjunto de vectores linealmente independientes que generan un espacio lineal -conocido como *span lineal*- denso dentro del espacio de referencia) es una matriz identidad.
El modelo anterior puede expandirse en predictores considerando ahora población **pop**, nivel de ingreso **ingre**, porcentaje de población analfebeta **analf** y la extensión en millas cuadradas **area** para explicar la esperanza de vida (medida en años).
El modelo `mod0` es aún más sensible a los datos provistos por el Estado de Alaska que el modelo `mod`
Así como se amplió la cantidad de variables en consideración al pasar del modelo `mod` al modelo `mod0`, también podría realizarse el procedimiento anterior para un modelo que considere la totalidad de las variables disponibles. Una forma para evitar escribir todas las variable en es usar un punto después de **~**, además de indicar de cuál base provienen los datos. De esta forma R entiende que debe considerar todas las variables de esa base como predictores, con excepción de la variable que se indica como respuesta.
Como se verifica de las pruebas antes realizadas, el modelo completo `mod_comp` tiene una $PRESS$ menor (más bajo) que el modelo que utiliza 4 predictores (*i.e.*, `mod0`) para explicar la media condicional de la esperanza de vida, lo que indica menor *leverage* en relación al Estado de Alaska.
### 6. Construcción Escalonada de Modelos de Predicción
#### 6.1. Aspectos Teóricos Generales
Como se conoce de los cursos de álgebra lineal, el mecanismo de *eliminación gaussiana* o *reducción de por filas*, es un proceso secuencial de *operaciones elementales entre filas* realizadas sobre la correspondiente matriz de coeficientes con la finalidad de estimar el rango de la matriz, el determinante de una matriz cuadrada y la inversa de una matriz invertible, en cuanto este mecanismo prepara las condiciones para resolver el sistema de ecuaciones; sobre los orígenes históricos de este mecanismo debe decirse que, como se señala en https://en.wikipedia.org/wiki/Gaussian_elimination, casos particulares de este método se conocían descubiertos por matemáticos chinos (sin prueba formal) en el año 179 de la era común C.E. (que es una forma no-cristiana de expresar la era que inicia en el año en que se supone nació Jesucristo).
Los mecanismos matemáticos anteriores, utilizados en el procedimiento estadístico de selección de los predictores de la media condicional de alguna variable de respuesta, se conocen como *regresión escalonada*. Como se señala en https://en.wikipedia.org/wiki/Stepwise_regression, la regresión escalonada es un método de ajuste de modelos de regresión en el que la elección de las variables predictivas se realiza mediante un procedimiento automático (...) En cada paso, se considera una variable para sumar o restar del conjunto de variables explicativas basado en algún criterio preespecificado. Por lo general, esto toma la forma de una secuencia hacia adelante, hacia atrás o combinada de pruebas F o pruebas t. La práctica frecuente de ajustar el modelo final seleccionado seguido de reportar estimaciones e intervalos de confianza sin ajustarlos para tener en cuenta el proceso de construcción del modelo ha llevado a llamadas a dejar de usar la construcción escalonada de modelos por completo (...) o al menos asegurarse de que en el modelo la incertidumbre se refleja correctamente (...) Las alternativas incluyen otras técnicas de selección de modelos, como $R^2$ ajustado, ek criterio de información de Akaike, el criterio de información bayesiano, el $C_p$ de Mallows, la $PRESS$ o la *tasa de falso descubrimiento*.
La construcción escalonada de un modelo puede suscitarse fundamentalmente de tres maneras:
1.*Selección hacia adelante*, que implica comenzar sin variables en el modelo, comprobar lo que ocurre al adicionar cada variable utilizando un criterio de ajuste del modelo elegido, agregando la variable (si la hubiese) cuya inclusión permita la mejora estadísticamente más significativa del ajuste y repetir este proceso hasta ningún predictor mejore el modelo de manera estadísticamente significativa. Véase https://www.analyticsvidhya.com/blog/2021/04/forward-feature-selection-and-its-implementation/
2. *Eliminación hacia atrás*, que implica comenzar con todas las variables candidatas, probar la eliminación de cada variable utilizando un criterio de ajuste del modelo elegido, eliminar la variable (si la hubiese) cuya pérdida produce el deterioro más insignificante estadísticamente del ajuste del modelo, y repetir este proceso hasta que no se pueden eliminar más variables sin una pérdida de ajuste estadísticamente insignificante. Véase https://www.analyticsvidhya.com/blog/2021/04/backward-feature-elimination-and-its-implementation/?utm_source=blog&utm_medium=Forward_Feature_Elimination.
3. *Eliminación bidireccional*, una combinación de 1 y 2, probando en cada paso las variables que se incluirán o excluirán.
#### 6.2. Método de Eliminación Hacia Atrás en R
##### 6.2.1. Eliminación Hacia Atrás con Probabilidad F
Para eliminar variables secuencialmente se usa la función `drop1`, que proporciona el estadístico F correspondiente a la eliminación de una única variable explicativa; el estadístico F arrojado por esta sintaxis debe interpretarse como la probabilidad de materialización de la probabilidad de rechazar $H_0:β_1=B_2=⋯=B_i=0$ siendo esta verdadera. A causa de lo anterior, un valor F alto indica que la probabilidad de la materialización antes descrita es alta y, ante semejante riesgo, la decisión racional es fallar en rechazar $H_0$ sobre la significancia estadística nula global de los coeficientes de regresión. Fallar en rechazar $H_0$ implica que probabilísticamente hablando no existen consecuencias relevantes (a nivel de capacidad predictiva) si se elimina el modelo en cuestión, por lo que un F mayor que el nivel de significancia $α$ preestablecido (que es la probabilidad de cometer error tipo I, fijada por el investigador con base a la información histórica y a criterios de experto experimentado) significa que ese coeficiente de regresión no es estadísticamente relevante y puede eliminarse.
Puede escribirse el modelo completo (con los 7 predictores) y luego utilizar `drop1(mod,test="F")` para verificar cuál es la primera variable que se recomienda eliminar tras el proceso antes descrito. Como se adelantó, se deben eliminar aquellos predictores cuyo valor de probabilidad F sea más alto.
Si se comparan los resultados de la sintaxis `drop1` con los de `summary`, se puede verificar que las probabilidades F y t coinciden. Esto sucede en este ejemplo porque no hay variables categóricas con más de 2 categorías; sin embargo, cuando se cuenta con variables categóricas con más de 2 categorías, no se debe usar `summary` porque en tal caso las probabilidades F y t no son equivalentes.
“`{r} summary(moda) “`
De los resultados anteriores se desprende que el primer predictor a ser eliminado es la variable **area**, pues tiene la probabilidad F más alta. Para materializar la eliminación se puede actualizar el modelo anterior mediante `moda=update(moda,.~.-area)`.
Y así puede continuarse hasta que, por ejemplo, todas las probabilidades sean menores a 0.15 (o a algún valor$α$ preestablecido de la forma antes descrita).
Finalmente, se obtiene que el modelo sugerido contempla las variables **pop**, **crim**, **grad** y **temp**.
##### 6.2.2. Eliminación Hacia Atrás con AIC
Adicionalmente, en lugar de usar el criterio de la probabilidad F se pueden usar criterios de información. Para usar el criterio de Akaike (AIC) simplemente no se indica nada en `test`, pues el AIC es el criterio por defecto que utiliza `drop1`. En este caso, la columna de AIC indica el valor del AIC que se obtendría si se elimina esa variable. Puesto que el objetivo es aumentar el AIC (porque eso haría al predictor candidato de ser eliminado), entonces se elimina la variable que más disminuye el AIC, generando luego un nuevo modelo (con las variables que menos disminuyen el AIC) que se compara con el modelo anterior, y así sucesivamente, hasta que la eliminación de cualquier variable aumenta el AIC con respecto al modelo anterior en lugar de disminuirlo, puesto que esta es la señal que en términos de robustez estadística del modelo no es recomendable eliminar más predictores.
El procedimiento antes descrito se puede realizar de forma automática con la sintaxis `step` mediante`step(mod)`. Tras ello, puede almacenarse el resultado en una estructura de datos (aquí llamada "mod4"#") y aplicar `summary` sobre dicho objeto.
“`{r} mod4=step(mod3) summary(mod4) “`
##### 6.2.2. Eliminación Hacia Atrás con BIC
###### 6.2.2.1. Aspectos Teóricos Relevantes del BIC
Si en lugar del criterio AIC se desease utilizar el criterio bayesiano de información (BIC) se debe indicar en la sintaxis `step` mediante `k=log(n)`. Debe agregarse que, como se señala en (Bishop, Christopher M. Pattern Recognition and Machine Learning. 2006, p. 217), el criterio bayesiano de información penaliza la complejidad del modelo y es el criterio expuesto por Bishop en el lugar referido el que muestra la penalización que el BIC ejerce sobre la complejidad del modelo y que se conoce como *factor de Occam*.
“`{r} knitr::include_graphics(“FOTO4.JPG”) “`
#Figura 2: Evaluación de la log-verosimilitud empleando parámetros optimizados #Fuente: Bishop, Christopher M. Pattern Recognition and Machine Learning. 2006, p. 216-17.
Debe decirse sobre el factor de Occam que, como puede verificarse en [David J. Spiegelhalter, Nicola G. Best, Bradley P. Carlin & Angelika Van Der Linde. Bayesian measures of model complexity and fit. Journal of Royal Statistical Society, Series B (Statistical Methodology); https://rss.onlinelibrary.wiley.com/doi/pdf/10.1111/1467-9868.00353] y en (van der Linde, Angelika. A Bayesian view of model complexity. Statistica Neerlandica xx, year xx-xx, special issue: All Models Are Wrong...; https://statmodeling.stat.columbia.edu/wp-content/uploads/2013/08/snavdlmc.pdf), no existe una definición analítica para el mismo, *i.e.*, una definición que pueda ser sustentada lógicamente desde algún marco teórico en congruencia clara y directa con un marco matemático autodemostrable dentro de teoría de conjuntos ZF-C (Zermelo-Fraenkel con Axioma de Elección) que la modele.
En este sentido, la investigación de Spiegelhalter et al es una de las investigaciones más importantes de al menos las últimas dos décadas a nivel de la teoría de las probabilidades y su importancia es aún mayor si el marco de referencia es únicamente la teoría bayesiana de probabilidades. En síntesis, los autores y autora de la investigación concluyen que la medida de complejidad bayesiana (que es la estructura matemática que aparece en la obra citada de Christopher Bishop) tiene como trasfondo común con el criterio DIC (que es la versión generalizada del AIC, de naturaleza teórica frecuentista, que tiene su propia penalización de la complejidad del modelo y por consiguiente su propia medición de dicha complejidad) la teoría de la información (rama de la teoría de las probabilidades que versa sobre las estructuras matemáticas que rigen la transmisión y el procesamiento de la información y se ocupa de la medición de la información y de la representación de la misma, así como también de la capacidad de los sistemas de comunicación para transmitir y procesar información; véase https://es.wikipedia.org/wiki/Teor%C3%ADa_de_la_informaci%C3%B3n), que el DIC y el BIC tienen una justificación lógica similar aunque el DIC tiene una campo de aplicación más amplio. Adicionalmente, se señala que la metodología de medición de complejidad bayesiana que ellos proponen es aplicable a toda la clase de modelos y que únicamente requiere de un trabajo analítico "despreciable" (p. 613) relativo a la configuración de un muestreo del tipo Monte Carlo basado en cadenas de Markov. Además, existe un problema señalado por los autores y autora relativo a que es difícil explicar si las diferencias entre los criterios de medición de complejidad del BIC y del DIC son realmente diferentes en términos estadísticos, puesto que es aún más difícil determinar el error del DIC en pruebas Monte Carlo (para ello se cita una investigación previa que señala esta dificultad). La publicación de este documento de investigación generó la apertura de un debate alrededor del mismo, que contó con la participación de S. Brooks (University of Cambridge), Jim Smith (University of Warwick), Aki Vehtari (Helsinki University of Technology), Martyn Plummer (International Agency of Research on Cancer, Lyon), Mervyn Stone (University College London), Christian P. Robert (Université Paris Dauphine) y D. M. Titterington (University of Glasgow), el mismísimo J. A. Nelder en persona (Impercial College of Science, Techonology and Medicine, London), Anthony Atkinson (London School of Economics and Political Science), A. P. David (University College London), José M. Bernardo (Universitat de València), Sujit K. Sahu (University of Southampton), Sylvia Richardson (Imperial College School of Medicine, London), Peter Green (University of Bristol), Kenneth P. Burnham (US Geological Survey and Colorado State University, Fort Collins), María Delorio (University of Oxford) y Christian P. Robert (Université Paris Dauphine), David Draper (University of California, Santa Cruz), Alan E. Gelfand (Duke University Durkham) y Matilde Travisani (University of Trieste), Jim Hodges (University of Minesota, Minneapolis), Youngjo Lee (Seoul National University), Xavier de Luna (Uméa University) y, finalmente, Xiao-Li Meng (Harvard University, University of Chicago); tremendo crossover, mucho mejor que *Crisis en Tierras Infinitas (1985-86)*... palabras mayores. Los posicionamientos de los autores y autoras participantes son diversas y profundas, sin embargo, se hará una recapitulación de aquellos que señalen debilidades la medición bayesiana de complejidad de un modelo estadístico.
Brooks (p. 616-18) plantea que la investigación (como casi toda buena investigación) deja preguntas abiertas, específicamente él señala que la ecuación 9 de la página 587 utiliza para calcular dicha complejidad el valor esperado, pero ¿por qué no la moda o la mediana?, ¿cuál es la justificación teórica de ello?, y de ello se deriva también ¿cómo se debe decidir entonces que el parámetro estimado debe ser la media, la moda o la mediana?, lo cual es relevante en cuanto podría conducir a diferencias importantes con el DIC; finalmente, ¿cómo se pueden ser comparables el análisis del modelo bajo el DIC con el análisis del modelo bajo las probabilidades posteriores (enfoque bayesiano) y por qué difieren?, ¿pueden ambas ser "correctas" de alguna manera significativa?
Por su parte, Jim Smith (p. 619-20) señala que no encontró errores técnicos (*i.e.*, matemáticos), pero que encontró cuatro problemas fundacionales. El primero que señala es que las implicaciones predictivas de todas las configuraciones del prior relativas a las variaciones en los ejemplos resueltos en la Sección 8 son increíbles (no en un sentido que podría considerarse positivo), puesto que según Smith no representan juicios de expertos cuidadosamente obtenidos, sino las opiniones de un usuario de software vacío. También señala que, al principio de la Sección 1, los autores afirman que quieren identificar modelos sucintos que parecen describir la información [¿acerca de valores de parámetros "verdaderos" incorrectos (ver Sección 2.2)?] en los datos con precisión, sin embargo, señala también que en un análisis bayesiano, la separación entre la información de los datos y el prior es artificial e inapropiada; señala que "Un análisis bayesiano en nombre de un experto en auditoría remota (Smith, 1996) podría requerir la selección de un prior que sea robusto dentro de una clase de creencias de diferentes expertos (por ejemplo, Pericchi y Walley (1991)). A veces, los prior predeterminados pueden justificarse para modelos simples. Incluso entonces, los modelos dentro de una clase de selección deben tener parametrizaciones compatibles: ver Moreno et al. (1998). Sin embargo, en los ejemplos en los que "el número de parámetros supera en número a las observaciones", afirman que sus enfoques de enfoque, es poco probable los prior predeterminados (por defecto) muestren alguna robustez (estadística). En particular, fuera del dominio de la estimación local vaga o de la estimación de la varianza de separación (discutida en la Sección 4), aparentemente los antecedentes por defecto pueden tener una fuerte influencia en las implicaciones del modelo y, por lo tanto, en la selección.", de lo cual se deriva una razonable insatisfacción ante la expresión la afirmación de los autores y autora sobre la baja probabilidad de que los prior muestren robustez.
Martyn Plummer (p. 621) señala lo que a su juicio son debilidades en la derivación heurística del DIC y de ello se deriva su señalamiento de sustento formal ;como señalan (Rosental & Iudin. Diccionario Filosófico. Editorial Tecolut, 1971. p. 215-216),
en términos históricos la palabra "heurística" proviene del griego εὑρίσκω, que significa "discuto". Es el arte de sostener una discusión y floreció sobre todo entre los sofistas de la antigua Grecia. Surgida como medio de buscar la verdad a través de la polémica, se escindió pronto en dialéctica y sofística. Sócrates, con su método, desarrolló la primera. En cambio, la sofística, tendiente sólo a alcanzar la victoria sobre el contrincante en la discusión, redujo la heurística a una suma de procedimientos que podían aplicarse con el mismo éxito tanto para demostrar una aseveración, cualquiera que fuese, como para refutarla. De ahí que ya Aristóteles no estableciera ninguna diferencia entre heurística y sofística. En la actualidad, al hablar de métodos heurísticos se hace referencia a una especie de atajos para las derivaciones rigurosas que implican mayor costo computacional, por lo que su carácter de verdad es siempre de corto plazo (provisional).
Mervyn Stone (p. 621) señala que la investigación de 2002 "bastante económico" en lo relativo a la *verdad fundamental* (véase https://marxistphilosophyofscience.com/wp-content/uploads/2020/12/sobre-los-estimadores-de-bayes-el-analisis-de-grupos-y-las-mixturas-gaussianas-isadore-nabi.pdf, p. 43-44), que si la sección 7.3 pudiera desarrollarse rigurosamente (puesto que le parece gnoseológicamente cuestionable el uso de $E_Y$), "(...) otra conexión (a través de la ecuación $(33)$) podría ser que $DIC ≈ −2A$. Pero, dado que la sección 7.3 invoca el supuesto de "buen modelo" y pequeños $|\hat{θ}-θ|$ para la expansión de la serie de Taylor (es decir, $n$ grande), tal conexión sería tan artificial como la de $A$ con el criterio de información de Akaike: ¿por qué no seguir con la forma prístina (hoy en día calculable) de $A$, que no necesita $n$ grande o verdad? , ¿y cuál acomoda la estimación de θ en el nivel de independencia de un modelo bayesiano jerárquico? Si la sensibilidad del logaritmo a probabilidades insignificantes es objetable, los bayesianos deberían estar felices de sustituirlo por una medida subjetivamente preferible de éxito predictivo." Es imposible cuestionar a Stone en cuanto a que, dado el enseñoramiento que en la teoría bayesiana de probabilidades tiene la escuela bayesiana subjetiva, el promedio del gremio bayesiano estaría filosóficamente satisfecha con renunciar a elementos objetivos (en este caso son requerimientos preestablecidos por la teoría del aprendizaje estadístico que condicionan la validez gnoseológica del modelo propuesto como un todo, como una muestra grande y/o una verdad fundamental) si representan un punto de discordia y pueden ser sustituidos por algún criterio de decisión que pueda ser determinado; que en paz descanse su alma https://www.ucl.ac.uk/statistics/sites/statistics/files/meryvn-stone-obituary.pdf.
Christian P. Robert y D. M. Titterington (p. 621) señalan que la estructura matemática planteada por los autores de la investigación para determinar la complejidad de un modelo desde la perspectiva bayesiana parecería hacer un uso duplicado (repetido en dos ocasiones) del conjunto de datos, la primera vez lo hacen para determinar la distribución posterior y la segunda para calcular la verosimilitud observada (o verosimilitud a priori, sin considerar información adicional). Este uso duplicado del conjunto de datos puede conducir a un sobreajuste del modelo; señalan que este tipo específico de problemática surgió antes en la investigación de (Aitkin, 1991).
Seguramente el invitado más célebre entre todos los que asistieron a este maravilloso coloquio académico fue John Nelder, padre de los modelos lineales generalizados. Antes de exponer su planteamiento, deben introducirse algunas cuestiones. En primer lugar, el *escape de amoníaco* en aplicaciones industriales es a lo que los autores se refieren (y se refirará Nelder) como *stack loss* (p. 609). En segundo lugar, la tabla 2 a la que se referirá Nelder es la siguiente:
“`{r} knitr::include_graphics(“TABLA2.JPG”) “`
#Figura 3: Tabla 2. Resultados de desviación para los datos de pérdida de amoníaco. #Fuente: Spiegelhalter, Best, Carlin & van der Linde. Bayesian measures of model complexity and fit, p. 610.
Así, Nelder (p. 622) señala: "Mi colega, el profesor Lee, ha planteado algunos puntos generales que conectan el tema de este artículo con nuestro trabajo sobre modelos lineales generalizados jerárquicos basados en la probabilidad. Quiero plantear un punto específico y dos generales. (a) El profesor Dodge ha demostrado que, de las 21 observaciones en el conjunto de datos de pérdida de amoníaco, ¡solo cinco no han sido declaradas como valores atípicos por alguien! Sin embargo, existe un modelo simple en el que ninguna observación aparece como un valor atípico. Es un modelo lineal generalizado con distribución gamma, log-link y predictor lineal x2 + log.x1 / Å log.x3 /: Esto da las siguientes entradas para la Tabla 2 en el documento: 98.3 92.6 6.2 104.5 (estoy en deuda con el Dr. Best por calcularlos). Es claramente mejor que los modelos existentes usados en la Tabla 2. (b) Este ejemplo ilustra mi primer punto general. Creo que ha pasado el tiempo en que bastaba con asumir un vínculo de identidad para los modelos y permitir que la distribución solo cambiara. Deberíamos tomar como nuestro conjunto de modelos de línea base al menos la clase de modeloos lineales generalizados definida por distribución, enlace y predictor lineal, con la elección de escalas para las covariables en el caso del predictor lineal. (c) Mi segundo punto general es que, para mí, no hay suficiente verificación de modelos en el artículo (supongo que el uso de tales técnicas no va en contra de las reglas bayesianas). Por ejemplo, si un conjunto de efectos aleatorios es suficientemente grande en número y el modelo postula que están distribuidos normalmente, sus estimaciones deben graficarse para ver si se parecen a una muestra de tal
distribución. Si parecen, por ejemplo, fuertemente bimodales, entonces el modelo debe revisarse." Que en paz descanse su alma.
Anthony Atkinson (p. 622) señala que dirige su participación al contexto de la regresión, concluyendo que este criterio de selección de modelos (el BIC planteado por los autores, que es el estimado mediante la sintaxis de R) es un primer paso, que necesita ser complementado
mediante pruebas de diagnóstico y gráficos. Para finalizar plantea que "Estos ejemplos muestran que la búsqueda hacia adelante es una herramienta extremadamente poderosa para este propósito. También requiere muchos ajustes del modelo a subconjuntos de datos. ¿Puede combinarse con los apreciables cálculos de los métodos de Monte Carlo de la cadena de Markov de los autores?" Que en paz descanse su alma.
A.P. Dawid plantea que el artículo debería haberse titulado "Medidas de la complejidad y el ajuste del modelo bayesiano", ya que según él son los modelos, no las medidas, los que son bayesianos. Una vez que se han especificado los ingredientes de un problema, cualquier pregunta relevante tiene una respuesta bayesiana única. La metodología bayesiana debe centrarse en cuestiones de especificación o en formas de calcular o aproximar la respuesta. No se requiere nada más (...) Un lugar donde un bayesiano podría querer una medida de la complejidad del modelo es como un sustituto de p en la aproximación del criterio de información de Bayes a la probabilidad marginal, por ejemplo, para modelos jerárquicos. Pero en tales casos, la definición del tamaño de muestra $n$ puede ser tan problemática como la de la dimensión del modelo $p$. Lo que necesitamos es un mejor sustituto del término completo $p⋅log(n)$". En línea con la gnoseología marxiana, lo adecuado parecería ser considerar que tanto los modelos como las medidas son bayesianos (o de otra escuela de filosofía de las probabilidades).
Las participaciones restantes son no tanto relativas a cuestiones metodológicas como a cuestiones filosóficas-fundacionales de la teoría bayesiana de las probabilidades y de la teoría de las probabilidades en general (puesto que el DIC, que es un criterio de información presentado por los mismos autores que presentan el BIC, no es bayesiano debido a que es una generalización del AIC -que es frecuentista-); de hecho, la transición de cuestiones metodológicas a filosóficas-fundacionales se expresa en el planteamiento de Dawid, quien aunque aborda cuestiones metodológicas lo hace con base en la lógica filosófica de que los modelos y no las medidas son los que pueden ser (o no) bayesianos. Por supuesto, estas últimas son las participaciones más importantes, sin embargo, abordalas escapa a los límites de esta investigación, por lo que para tan importante tarea se dedicará indudablemente un trabajo posterior.
###### 6.2.2.2. Ejecución de la Eliminación Hacia Atrás con el BIC
“`{r} n = nrow(base) mod5=step(mod3,k=log(n)) summary(mod5) “`
#### 6.3. Método de Selección Hacia Adelante en R
A propósito de lo señalado por Anthony Atkinson, para realizar un proceso de selección hacia adelante se puede usar la función `add1` inciando con un modelo que no contenga ninguna variable e indicando en `scope` cuales son todas las variables disponibles. Ello se realiza de la siguiente forma: `add1(modb, scope=~pop + ingre + analf + crim + grad + temp + area)`.
En este caso se escoge agregar la variable que disminuya más el AIC. En este caso es **crim**. Se actualiza el modelo y se continúa hasta que todas tengan un AIC más bajo que el anterior: `modb=update(modb,.~.+crim)`.
De forma similar se puede usar `step` para indicar `scope` (además de indicar `direction="forward"`) de la siguiente forma: `step(mod6,direction="forward",scope=~pop + ingre + analf + crim + grad + temp + area)`. `scope` "define la gama de modelos examinados en la búsqueda por pasos. Debe ser una fórmula única o una lista que contenga los componentes superior e inferior, ambas fórmulas. Consulte los detalles sobre cómo especificar las fórmulas y cómo se utilizan." (véase https://stat.ethz.ch/R-manual/R-devel/library/MASS/html/stepAIC.html).
En este caso, tiene la logica del modelo hacia adelante, se va ingresando las variables que reducen el AIC y luego quedan las que no estan en el modelo, osea las que incrementaria el AIC.
One of my basic theses about modern capitalism is that since 2008, the major capitalist economies have been in what I call a Long Depression. In my book of 2016 of the same name, I distinguish between what economists call recessions or slumps in production, investment and employment; and depressions. Under the capitalist mode of […]