When the 2022 NBA draft happened almost a month ago, I thought to myself: do players picked earlier in the draft (i.e. higher-ranked) actually end up having better/longer careers?
If data wasn’t an issue, the way I would do it would be to look at players chosen in the draft lottery (top 60 picks) in the past 10/20 years. For each player, I would look at how many years he played in the NBA and see if there was a correlation between that and draft position. (Here, number of years in the NBA is a proxy for how successful an NBA career is. There are other possible ways to define success, e.g. minutes played, points scored.)
Unfortunately data is an issue, so I ended up looking at a related question: What are the draft positions of players currently in the NBA? If players picked earlier in the draft are more…
# PROCESO DE SELECCIÓN DE VARIABLES EXPLICATIVAS
## Introducción: Sobre la necesidad de un proceso de selección de predictores
Usualmente se tiene interés en explicar los datos de la forma más simple, lo cual en el contexto de la teoría de las probabilidades (especialmente en la teoría bayesiana de probabilidades) se conoce como el *principio de parsimonia*, el cual está inspirado en el principio filosófico conocido como *navaja de Ockham*, la cual establece que en igualdad de condiciones la explicación más simple suele ser la más probable. El principio de parsimonia adopta diferentes formas según el área de estudio del análisis inferencial en el que se encuentre un investigador. Por ejemplo, una parametrización parsimoniosa es aquella que usa el número óptimo de parámetros para explicar el conjunto de datos de los que se dispone, pero "parsimonia" también puede referirse a modelos de regresión parsimoniosos, es decir, modelos que utilizan como criterio de optimización emplear la mínima cantidad de coeficientes de regresión para explicar una respuesta condicional Y. El principio de parsimonia, los procesos matemáticos de optimización regidos por el criterio de alcanzar un mínimo y la navaja de Ockham son un mismo tipo de lógica aplicado en escalas de la existencia (que podríamos llamar en general "materia", como lo hace Landau en sus curso de física teórica) cualitativamente diferentes. La historia de la Filosofía demuestra que el único sistema que podría ser aplicado así exitosamente es el sistema hegeliano (lo que obedece a que parcialmente sigue la lógica de la existencia misma, como han demostrado Marx, Engels, Lenin, Levins, Lewontin y el mismo Hegel en su extensa obra). ¿Cómo es posible la vinculación en distintas escalas cualitativas de la realidad del principio de la navaja de Ockham? A que todas esas ideas responden a la escuela filosófica de Ockham, que era la escuela nominalista. Retomando lo que señalan (Rosental & Iudin. Diccionario Filosófico, Editorial Tecolut, 1971. p.341; véase https://www.filosofia.org/enc/ros/nom.htm), el nominalismo fue una corriente de la filosofía medieval que consideraba (ya es una escuela extinta) que los conceptos generales tan sólo son nombres de los objetos singulares. Los nominalistas afirmaban que sólo poseen existencia real las cosas en sí, con sus cualidades individuales (es decir, las generalizaciones para ellos no tenían valor gnoseológico en sí mismas sino como recurso gnoseológico). Los nominalistas van más allá, planteando que las generalizaciones no sólo no existen con independencia de los objetos particulares (esta afirmación en correcta, lo que no es correcto es pensar que lo inverso sí es cierto), sino que ni siquiera reflejan las propiedades y cualidades de las cosas. El nominalisto se hallaba indisolublemente vinculado a las tendencias materialistas, ya que reconocía la prioridad de la cosa y el carácter secundario del concepto. Por supuesto, las generalizaciones aunque menos reales que los objetos particulares (y de ahí la sujeción de la teoría a la práctica en un concepto que las une conocido en la teoría marxista como *praxis*) no deja por ello de ser real en cuanto busca ser una representación aproximada (a largo plazo cada vez más aproximada a medida se desarrollan las fuerzas productivas) de la estructura general (interna y externa, métrica y topológica) común que tienen tales fenómenos naturales o sociales. Marx señaló que el nominalismo fue la primera expresión del materialismo de la Edad Media. Con todo, los nominalistas no comprendían que los conceptos generales reflejan cualidades reales de cosas que existen objetivamente y que las cosas singulares no pueden separarse de lo general, pues lo contienen en sí mismas (y esto no tiene un carácter únicamente marxista, sino que incluso el célebre formalista David Hilbert señaló, según la célebre biógrafa de matemáticos Constance Reid que "The art of doing mathematics consists in finding that special case which contains all the germs of generality"). Así, el defecto fundamental de la navaja de Ockham es el no considerar algún conjunto de restricciones que complementen al criterio de selección de la explicación basado en que sea la idea más simple. Como se señala en https://www.wikiwand.com/en/Occam%27s_razor,
"En química, la navaja de Occam es a menudo una heurística importante al desarrollar un modelo de mecanismo de reacción (...) Aunque es útil como heurística en el desarrollo de modelos de mecanismos de reacción, se ha demostrado que falla como criterio para seleccionar entre algunos modelos publicados seleccionados (...) En este contexto, el propio Einstein expresó cautela cuando formuló la Restricción de Einstein: "Difícilmente se puede negar que el objetivo supremo de toda teoría es hacer que los elementos básicos irreductibles sean tan simples y tan pocos como sea posible sin tener que renunciar a la representación adecuada de un dato único de experiencia"."
La clave en la expresión anterior de Einstein es "sin tener que renunciar a...", lo que se cristaliza nítidamente en una frase que señala la fuente citada es atribuida a Einstein, pero no ha sido posible su verificación: "Todo debe mantenerse lo más simple posible, pero no lo más simple". Como se verifica en https://www.statisticshowto.com/parsimonious-model/, en general, existe un *trade-off* entre la bondad de ajuste de un modelo y la parsimonia: los modelos de baja parsimonia (es decir, modelos con muchos parámetros) tienden a tener un mejor ajuste que los modelos de alta parsimonia, por lo que es necesario buscar un equilibrio.
La parsimonia estadística es deseada porque un mínimo de coeficientes de regresión implica un mínimo de variables y un mínimo de estos implica un mínimo de variables explicativas, lo que puede ser útil en casos de que exista colinealidad entre las variables explicativas, así como también permite ahorrar tiempo y dinero en lo relativo a la inversión de recursos destinada al estudio, aunque no necesariamente garantice que en general (considerando el impacto posterior de las decisiones tomadas con base en el estudio y otros factores) se ahorre tiempo y dinero.
## Modelos Jerárquicos
Existen diferentes tipos de modelos jerárquicos. Los hay de diferente tipo, algunos más complejos que otros (complejidad a nivel teórico, matemático y computacional); ejemplos de tales modelos son las mixturas de probabilidad y se pueden estudiar en https://marxistphilosophyofscience.com/wp-content/uploads/2020/12/sobre-los-estimadores-de-bayes-el-analisis-de-grupos-y-las-mixturas-gaussianas-isadore-nabi.pdf. Aquí se tratará con modelos jerárquicos más simples, como los abordados en (Kutner, Nachtsheim, Neter & Li. p.294-305).
Como señalan los autores referidos en la p.294., los modelos de regresión polinomial tienen dos tipos básicos de usos: 1. Cuando la verdadera función de respuesta curvilínea es de hecho una función polinomial. 2. Cuando la verdadera función de respuesta curvilínea es desconocida (o compleja), pero una función polinomial es una buena aproximación a la función verdadera. El segundo tipo de uso, donde la función polinomial se emplea como una aproximación cuando se desconoce la forma de la verdadera función de respuesta curvilínea, es muy común. Puede verse como un enfoque no paramétrico para obtener información sobre la forma de la función que modela la variable de respuesta. Un peligro principal en el uso de modelos de regresión polinomial es que las extrapolaciones pueden ser peligrosas con estos modelos, especialmente en aquellos con términos de orden superior, es decir, en aquellos cuyas potencias sean iguales o mayores a 2. Los modelos de regresión polinomial pueden proporcionar buenos ajustes para los datos disponibles, pero pueden girar en direcciones inesperadas cuando se extrapolan más allá del rango de los datos.
Así, como señalan los autores referidos en la p.305, el uso de modelos polinomiales no está exento de inconvenientes. Estos modelos pueden ser más costosos en grados de libertad que los modelos no-lineales alternativos o los modelos lineales con variables transformadas. Otro inconveniente potencial es que puede existir multicolinealidad grave incluso cuando las variables predictoras están centradas. Una alternativa al uso de variables centradas en la regresión polinomial es usar polinomios ortogonales. Los polinomios ortogonales están no-correlacionados, puesto que la ortogonalidad de sus términos implica independencia lineal entre los mismos. Algunos paquetes de computadora usan polinomios ortogonales en sus rutinas de regresión polinomial y presentan los resultados ajustados finales en términos tanto de los polinomios ortogonales como de los polinomios originales. Los polinomios ortogonales se discuten en textos especializados como (Drapper & Smith, Applied Linear Regression). A veces, se ajusta una función de respuesta cuadrática con el fin de establecer la linealidad de la función de respuesta cuando no se dispone de observaciones repetidas para probar directamente la linealidad de la función de respuesta.
## Caso de Aplicación
### 1. Conversión de Matriz de Datos a Marco de Datos
La base ´Vida.Rdata´ contiene datos para los 50 estados de los Estados Unidos. Estos datos son proporcionados por U.S. Bureau of the Census. Se busca establecer las relaciones que existen entre ciertas variables del Estado que se analice y la esperanza de vida. A continuación, se presenta una descripción de las variables que aparecen en la base en el orden en que
aparecen:
+ **esper**: esperanza de vida en años (1969-71).
+ **pob**: población al 1 de Julio de 1975.
+ **ingre**: ingreso per capita (1974).
+ **analf**: porcentaje de la población analfabeta (1970).
+ **crim**: tasa de criminalidad por 100000 (1976).
+ **grad**: porcentaje de graduados de secundaria (1970).
+ **temp**: número promedio de días con temperatura mínima por debajo de los 32 grados (1931-1960) en la capital del estado.
+ **area**: extensión en millas cuadradas.
Debe comenzarse leyendo el archivo de datos pertinente mediante la sintaxis `load("Vida.Rdata")`. Si se observa la estructura de la base de datos, se verifica que es simplemente una matriz. Por tanto, si se utiliza la sintaxis `names(base)` no se obtiene información alguna, mientras que si se trata de llamar a alguna de las variables por su nombre, como por ejemplo `base$esper`, R informa de un error y lo mismo ocurre si se usa `attach(base)`. Esto sucede porque la estructura de datos invocada no está definida como un marco de datos o `data.frame`. Por ello, debe comenzarse por convertir dicha matriz de datos en un marco de datos o `data.frame`y posteriormente puede verificarse si las sintaxis antes mencionadas son ahora operativas.
“`{r} setwd(“C:/Users/User/Desktop/Carpeta de Estudio/Mis Códigos en R”) load(“Vida.Rdata”) names(base) base=data.frame(base) names(base) “`
### 2. Obtención de todos los modelos posibles dado un determinado conjunto de variables dentro del marco de datos
Pueden obtenerse los $R^2$ ajustados de todos los modelos posibles con las 7 variables disponibles. Para hacerlo, puede construirse primero un objeto con todos los predictores y llamarlo **X** para posteriormente construir un objeto llamado **sel** aplicando la función `leaps` (perteneciente a la librería con el mismo nombre) de la siguiente forma: `sel=leaps(x,y, method="adjr2")`. Nótese que el objeto construido mediante la sintaxis `leaps`, es decir, **sel**, es una lista con 4 componentes cuyos nombres pueden obtenerse con la sintaxis `names(sel)`. Así, puede llamarse a cada uno de tales componentes por separado usando el signo `$`, por ejemplo, `sel$which`. Antes de proceder a realizar los cálculos definidos antes, se estudiará a nivel general la sintaxis `leaps`.
La sintaxis `leaps` usa un algoritmo eficiente (parsimonioso) de ramificación y cota para realizar una búsqueda exhaustiva de los mejores subconjuntos de las variables contenidas en el marco de datos para predecir y realizar análisis de regresión lineal; este tipo de algoritmo, según https://www.wikiwand.com/en/Branch_and_bound, es un paradigma de diseño de algoritmos para problemas de optimización discreta y combinatoria, así como optimización matemática. Un algoritmo de ramificación y acotación consiste en una enumeración sistemática de soluciones candidatas mediante la búsqueda en el espacio de estados: se piensa que el conjunto de soluciones candidatas forma un árbol enraizado con el conjunto completo en la raíz; "si las cosas fuesen tal y como se presentan ante nuestros ojos, la ciencia entera sobraría" dijo Marx alguna vez. El algoritmo explora las ramas del árbol representado por los subconjuntos del conjunto de soluciones posibles al problema de optimización. Antes de enumerar las soluciones candidatas de una rama, el algoritmo sigue el siguiente proceso descarte de ramas: la rama se compara con los límites estimados superior e inferior de la solución óptima y se descarta (la rama en su conjunto) si no ella puede producir una solución mejor que la mejor encontrada hasta ahora por el algoritmo (véase https://cran.r-project.org/web/packages/leaps/leaps.pdf, p.1). Como se señala en la documentación antes citada, dado que el algoritmo devuelve el mejor modelo de cada tamaño (aquí se refiere a los modelos estadísticamente más robustos según un número de variables fijo que se considere) no importa si desea utilizar algún criterio de información (como el AIC, BIC, CIC o DIC). El algoritmo depende de una estimación eficiente de los límites superior e inferior de las regiones/ramas del espacio de búsqueda. Si no hay límites disponibles, el algoritmo degenera en una búsqueda exhaustiva.
A pesar de lo señalado relativo a que la búsqueda realiza por `leaps` es independiente de cualquier criterio de información utilizado, puede omitirse este hecho con la finalidad de que sea posible incorporar a esta práctica el estudio de los criterios de información. A continuación, se presenta una lista de los mejores modelos siguiendo el criterio de $R^2$ ajustado más alto, lo que se indica al interior de la sintaxis `leaps` mediante methods="adjr2".
Adicionalmente, es posible construir una matriz, almacenarla bajo el nombre **mat** con el contenido de las filas `sel$which` y `sel$adjr2`, agregando un contador para identificar cada modelo mediante la sintaxis `cbind`. La estructura de datos **mat** contiene todos los diferentes modelos de regresión lineal (a diferentes tamaños de los mismos) mediante la sintaxis `leaps` para la base de datos utilizada.
“`{r} k=nrow(sel$which) k mat=data.frame(cbind(n=1:k,sel$which,round(sel$adjr2,2))) mat
head(mat[order(-mat$V9),],10) “`
Así, puede construirse un subconjunto de **mat** que contenga sólo los modelos cuyo coeficiente de determinación ajustado sea mayor o igual que 0.68.
Nótese que los cuatro modelos con el $R^2$ ajustado más alto son los modelos 28, 38, 39, y 40, cuyo tamaño oscila entre 4 o 5 variables explicativas; si se utiliza la sintaxis `print` es posible verificar que en las filas está el modelo como tal (si la variable se toma en consideración tiene asignado un "1", mientras que en caso contrario un "0"), mientras que en las columnas se localizan las posibles variables a utilizar.
### 3. Estadístico de Mallows
Como se puede verificar en https://support.minitab.com/es-mx/minitab/18/help-and-how-to/modeling-statistics/regression/supporting-topics/goodness-of-fit-statistics/what-is-mallows-cp/, el Estadístico $C_p$ de Mallows sirve como ayuda para elegir entre múltiple modelos de regresión. Este estadístico ayuda a alcanzar un equilibrio importante con el número de predictores en el modelo. El $C_p$ de Mallows compara la precisión y el sesgo del modelo completo con modelos que incluyen un subconjunto de los predictores. Por lo general, deben buscarse modelos donde el valor del $C_p$ de Mallows sea pequeño y esté cercano al número de predictores del modelo más la constante $p$. Un valor pequeño del $C_p$ de Mallows indica que el modelo es relativamente preciso (tiene una varianza pequeña) para estimar los coeficientes de regresión verdaderos y pronosticar futuras respuestas. Un valor del $C_p$ de Mallows que esté cerca del número de predictores más la constante indica que, relativamente, el modelo no presenta sesgo en la estimación de los verdaderos coeficientes de regresión y el pronóstico de respuestas futuras. Los modelos con falta de ajuste y sesgo tienen valores de $C_p$ de Mallows más grandes que p. A continuación se presenta un ejemplo.
#Figura 1: Ejemplo del uso del Estadístico de Mallows para evaluar un modelo #Fuente: https://support.minitab.com/es-mx/minitab/18/help-and-how-to/modeling-statistics/regression/supporting-topics/goodness-of-fit-statistics/what-is-mallows-cp/
Así, para el ejemplo aquí utilizado (que responde a la base de datos antes especificada) puede obtenerse el estadístico $C_p$ de Mallows para todos los modelos posibles con las 7 variables disponibles. Para ello puede usarse la función `leaps`; nótese que no es necesario indicarle a R que obtenga el estadístico de Mallows mediante la sintaxis `method=Cp` puesto que este método es el establecido por defecto en la programación de R, por lo que en el escenario en que no se indique un "method" en específico el programa utilizará por defecto el criterio del estadístico de Mallows.
“`{r} sel = leaps(X,esper) names(sel) sel$Cp “`
Complementariamente, puede construirse una nueva matriz **mat** que en lugar de los criterios `sel$which` y `sel$adjr2` siga los criterios `sel$which`, `sel$Cp` y `sel$size`, agregando al igual que antes un contador para identificar cada modelo. Esto implicará la sobreeescritura de la matriz **mat**. Pueden seleccionarse con antelación únicamente las filas de **mat** que se corresponden con los modelos seleccionados en el punto anterior y comparar la columna del $C_p$ con la columna $size$ que corresponde al número de coeficientes (p). En cada caso puede determinarse si el modelo es sesgado o no, sin perder de vista que un modelo es sesgado según el estadístico de Mallows si $C_p>p$. De lo anterior se desprende que se está buscando un conjunto de modelos insesgados para los cuales se verifica la condición $C_p<p$ antes mencionada.
Como puede observarse, en todos los modelos arrojados por la sintaxis `leaps` cumplen con la condición antes especificada, por lo que es posible afirmar que, sobre todo respecto a los modelos 28, 38, 39 y 40, que son buenos candidatos para ser utilizados (los mejores modelos son los mismos cuatro que en el literal anterior).
### 4. Suma de Cuadrados Residuales de Predicción (PRESS)
####4.1. Aproximación Gráfica
Como se señala en (https://pj.freefaculty.org/guides/stat/Regression/RegressionDiagnostics/OlsHatMatrix.pdf, p.9), la PRESS no es otra cosa que el error de estimación correspondiente a un valor particular de la variable condicional $Y$; la estimación de PRESS a veces es útil como una medida resumida de la capacidad de un modelo para predecir nuevas observaciones. Las líneas de comando presentadas a continuación expresan la configuración de la función personalizada `plot.press`, que es una función empírica que se aproxima gráficamente a los PRESS mediante el siguiente procedimiento:
a) Crea un modelo solamente con la variable **ingre**.
b) Toma el Estado i-ésimo y crea otro modelo basado en los demás Estados (excepto el i-ésimo).
c) Grafica las dos líneas de regresión y marca la observación del Estado i-ésimo en rojo para que se observe como se diferencian las dos líneas a la altura del ingreso de ese Estado.
d) Estima el promedio de la esperanza de vida para el i-ésimo Estado usando las dos ecuaciones.
“`{r} plot.press=function(i){ mod =lm(esper~ingre,base) mod1=lm(esper ~ ingre,base[-i,])
plot(base$ingre,base$esper,pch=18,xlab=”ingreso”,ylab=”esperanza”) points(base$ingre[i],base$esper[i],pch=18,col=2) abline(mod) abline(mod1,lty=2,col=2) abline(v=base$ingre[i],col=4,lty=2) legend(3000,max(esper),c(“completo”,paste(“falta el “,i,sep=””)),col=c(1,2),lty=c(1,2),bty=”n”)
#### 4.2. Aproximación Inferencial vía Residuos Estandarizados
Como señala https://www.statisticshowto.com/what-is-a-standardized-residuals/, los residuos estandarizados permiten normalizar el conjunto de datos de estudio en el contexto del análisis de regresión y de la ejecución de pruebas de hipótesis chi-cuadrado $χ^2$. Un residuo estandarizado es una razón: la diferencia entre el valor observado y el valor esperado (condicional, a posteriori) sobre la desviación estándar del valor esperado en la prueba de chi-cuadrado.
Como se señala en https://online.stat.psu.edu/stat501/lesson/11/11.4, existen varias medidas para identificar valores extremos de X (observaciones de alto $leverage$ o $influencia$) y valores de Y inusuales (valores atípicos). Al intentar identificar valores atípicos, un problema que puede surgir es cuando existe un valor atípico potencial que influye en el modelo de regresión hasta tal punto que la función de regresión estimada se "arrastrada" hacia el valor atípico potencial, de modo que no se marca como un valor atípico utilizando el criterio usual de residuos estandarizados. Para abordar este problema, los residuos eliminados ofrecen un criterio alternativo para identificar valores atípicos. La idea básica de esto es eliminar las observaciones una a la vez, reajustando cada vez el modelo de regresión en las n – 1 observaciones restantes. Luego, se comparan los valores de respuesta observados con sus valores ajustados basados en los modelos con la i-ésima observación eliminada. Esto produce residuos eliminados (no estandarizados). La estandarización de los residuos eliminados produce residuos eliminados studentizados, como se verá teóricamente a continuación.
Formalmente, es un resultado conocido del álgebra lineal que $y=Xβ+ε$, en donde $X_{n×p}$, $\hat{β}=(X'X)^{-1}X-y$ y $\hat{y}=X\hat{β}=X(X'X)^{-1}X'y=Hy$, donde $H=X(X'X)^{-1}X'$ es la matriz conocida como *matriz sombrero*. Los residuos son $e=y-\hat{y}=y-Hy=(I-H)y$. Adicionalmente, se sabe que la varianza poblacional $σ^2$ es desconocida y puede estimarse mediante la suma de cuadrados medios del error $MSE$. Así, los residuos pueden ser expresados mediante la ecuación $e_i^*=\frac{e_i}{\sqrt{MSE}}$ y se conocen como *residuos semistudentizados*. Puesto que la varianza de los residuos depende tanto de $σ^2$ como de $X$, la varianza estimada es $\hat{V}(e_i)=MSE(1-h_{ii})$, donde $h_{ii}$ es el $i$-ésimo elemento de la diagonal principal de la matriz sombrero. Así, los residuos estandarizados, también conocidos como *residuos internamente studentizados*, tienen la forma $r_i=\frac{e_i}{\sqrt{MSE(1-h_{ii})}}$. Sin embargo, se sabe que es imposible que un residuo individual y el MSE (que es la varianza del conjunto de residuos) no estén correlacionados (existe dependencia lineal) y, por consiguiente, es imposible que $r_i$ siga una distribución t de Student. Lo anterior representa un impedimento para realizar pruebas de significancia estadística de los coeficientes de regresión, puesto que la distribución t es junto con la F los dos tipos de distribución más utilizados (y no sólo en el contexto de regresión) para realizar pruebas de hipótesis, dentro de las cuales las pruebas de significancia de coeficientes son un tipo de ellas. La solución a la problemática antes descrita consiste en eliminar la $i$-ésima observación, ajustar la función de regresión a las $n-1$ observaciones restantes y luego obtener nuevas $\hat{y}$'s que pueden ser denotadas como $\hat{y}_{i(i)}$. La diferencia $d_i=y_i-\hat{y}_{i(i)}$ es llamada *residuo eliminado*. Una expresión equivalente que no requiere recomputación es: $d_i=\frac{e_i}{1-h_{ii}}$.
Los residuos eliminados expresados de la forma anterior son la base para encontrar los residuos conocidos como *residuos eliminados studentizados* o *resiudos studentizados externamente*, los cuales adoptan la forma $t_i=\frac{d_i}{\sqrt{{\frac{MSE}{1-h_{ii}}}}}\sim{\sf t_{n-p-1}}$ o $t_i=\frac{e_i}{\sqrt{{{MSE(1-h_{ii})}}}}\sim{\sf t_{n-p-1}}$; véase https://stats.stackexchange.com/questions/99717/whats-the-difference-between-standardization-and-studentization/99723.
En lo que a la estimación de los diferentes tipos de residuos se refiere, debe comenzarse por obtener las **influencias** o **leverage** del modelo usando `hatvalues(mod)`; debe recordarse que las influencias son utilizadas para determinar que tanto impacto tiene una observación sobre los resultados de la regresión. Precisamente el análisis descriptivo anterior, en el que en una de las rectas de regresión (de las dos que aparecen en cada una de las cincuenta gráficas posibles) se omitía un Estado, tenía como finalidad verificar cuánto impactaba su ausencia (la del Estado sustraido) en la estimación realizada sobre la media condicional de $Y$. Al utilizar la sintaxis "mod=lm(esper~ingre,base)" se está planteando un modelo con la totalidad de Estados, del cual se calculan sus valores sombrero mediante la sintaxis `h = hatvalues(mod)`, sus residuos mediante `r=mod$res`, se estima el residuo de un modelo en el que no se considera el Estado i-ésimo en el análisis (en este caso Alaska) mediante `pred.r = r[2]/(1-h[2])` y, finalmente, la validez estadística de la estimación `pred.r = r[2]/(1-h[2])` se determina contrastándola con respecto al resultado de restarle a la media estimada $\hat{Y}_2$ (porque en este caso para Alaska, que ocupa la fila dos en la base de datos, que es una base de datos de corte transversal) la media estimada $\hat{Y}$ del modelo que no considera al i-ésimo Estado (aquí es Alaska).
“`{r} mod=lm(esper~ingre,base) h = hatvalues(mod) r=mod$res pred.r = r[2]/(1-h[2]) round(pred.r,2)
esper[2]-73.07
plot.press(2) “`
Finalmente, puede obtenerse la Suma de Cuadrados Residuales de Predicción $PRESS$ utilizando los residuos eliminados globales (no únicamente para el Estado de Alaska) mediante la siguiente ecuación: $$PRESS=\sum{( \frac{r_i}{1-h_i}} )^2$$.
“`{r} d=r/(1-h) press=t(d)%*%d round(press,2) “`
### 5. Comparación de Modelos vía $PRESS$
Es posible comparar el modelo que únicamente contempla la variable ingreso **ingre** con el que se obtiene en un modelo que contenga en su lugar la cantidad de población del Estado **pop** y su tasa de criminalidad **crim**. Esto con el fin de verificar cuál de los dos modelos es más sensible a valores extremos de X al realizar estimaciones de la media condicional $\hat{Y}$ de la variable *esperanza de vida*.
Se observa que el modelo `mod` es más sensible, puesto que su PRESS es más alto (89.32).
Debe decirse que la matriz "d" es conocida también como *matriz de Gramm*, por lo que su determinante es igual al producto de sí y su transpuesta, es decir, `t(d)%*%d`. Como se verifica en https://www.wikiwand.com/en/Gram_matrix, la matriz de Gramm cuyos elementos pertenecen a los reales tiene la característica de ser simétrica (matriz cuadrada que es igual a su transpuesta); la matriz de Gramm de cualquier base ortonormal (conjunto de vectores linealmente independientes que generan un espacio lineal -conocido como *span lineal*- denso dentro del espacio de referencia) es una matriz identidad.
El modelo anterior puede expandirse en predictores considerando ahora población **pop**, nivel de ingreso **ingre**, porcentaje de población analfebeta **analf** y la extensión en millas cuadradas **area** para explicar la esperanza de vida (medida en años).
El modelo `mod0` es aún más sensible a los datos provistos por el Estado de Alaska que el modelo `mod`
Así como se amplió la cantidad de variables en consideración al pasar del modelo `mod` al modelo `mod0`, también podría realizarse el procedimiento anterior para un modelo que considere la totalidad de las variables disponibles. Una forma para evitar escribir todas las variable en es usar un punto después de **~**, además de indicar de cuál base provienen los datos. De esta forma R entiende que debe considerar todas las variables de esa base como predictores, con excepción de la variable que se indica como respuesta.
Como se verifica de las pruebas antes realizadas, el modelo completo `mod_comp` tiene una $PRESS$ menor (más bajo) que el modelo que utiliza 4 predictores (*i.e.*, `mod0`) para explicar la media condicional de la esperanza de vida, lo que indica menor *leverage* en relación al Estado de Alaska.
### 6. Construcción Escalonada de Modelos de Predicción
#### 6.1. Aspectos Teóricos Generales
Como se conoce de los cursos de álgebra lineal, el mecanismo de *eliminación gaussiana* o *reducción de por filas*, es un proceso secuencial de *operaciones elementales entre filas* realizadas sobre la correspondiente matriz de coeficientes con la finalidad de estimar el rango de la matriz, el determinante de una matriz cuadrada y la inversa de una matriz invertible, en cuanto este mecanismo prepara las condiciones para resolver el sistema de ecuaciones; sobre los orígenes históricos de este mecanismo debe decirse que, como se señala en https://en.wikipedia.org/wiki/Gaussian_elimination, casos particulares de este método se conocían descubiertos por matemáticos chinos (sin prueba formal) en el año 179 de la era común C.E. (que es una forma no-cristiana de expresar la era que inicia en el año en que se supone nació Jesucristo).
Los mecanismos matemáticos anteriores, utilizados en el procedimiento estadístico de selección de los predictores de la media condicional de alguna variable de respuesta, se conocen como *regresión escalonada*. Como se señala en https://en.wikipedia.org/wiki/Stepwise_regression, la regresión escalonada es un método de ajuste de modelos de regresión en el que la elección de las variables predictivas se realiza mediante un procedimiento automático (...) En cada paso, se considera una variable para sumar o restar del conjunto de variables explicativas basado en algún criterio preespecificado. Por lo general, esto toma la forma de una secuencia hacia adelante, hacia atrás o combinada de pruebas F o pruebas t. La práctica frecuente de ajustar el modelo final seleccionado seguido de reportar estimaciones e intervalos de confianza sin ajustarlos para tener en cuenta el proceso de construcción del modelo ha llevado a llamadas a dejar de usar la construcción escalonada de modelos por completo (...) o al menos asegurarse de que en el modelo la incertidumbre se refleja correctamente (...) Las alternativas incluyen otras técnicas de selección de modelos, como $R^2$ ajustado, ek criterio de información de Akaike, el criterio de información bayesiano, el $C_p$ de Mallows, la $PRESS$ o la *tasa de falso descubrimiento*.
La construcción escalonada de un modelo puede suscitarse fundamentalmente de tres maneras:
1.*Selección hacia adelante*, que implica comenzar sin variables en el modelo, comprobar lo que ocurre al adicionar cada variable utilizando un criterio de ajuste del modelo elegido, agregando la variable (si la hubiese) cuya inclusión permita la mejora estadísticamente más significativa del ajuste y repetir este proceso hasta ningún predictor mejore el modelo de manera estadísticamente significativa. Véase https://www.analyticsvidhya.com/blog/2021/04/forward-feature-selection-and-its-implementation/
2. *Eliminación hacia atrás*, que implica comenzar con todas las variables candidatas, probar la eliminación de cada variable utilizando un criterio de ajuste del modelo elegido, eliminar la variable (si la hubiese) cuya pérdida produce el deterioro más insignificante estadísticamente del ajuste del modelo, y repetir este proceso hasta que no se pueden eliminar más variables sin una pérdida de ajuste estadísticamente insignificante. Véase https://www.analyticsvidhya.com/blog/2021/04/backward-feature-elimination-and-its-implementation/?utm_source=blog&utm_medium=Forward_Feature_Elimination.
3. *Eliminación bidireccional*, una combinación de 1 y 2, probando en cada paso las variables que se incluirán o excluirán.
#### 6.2. Método de Eliminación Hacia Atrás en R
##### 6.2.1. Eliminación Hacia Atrás con Probabilidad F
Para eliminar variables secuencialmente se usa la función `drop1`, que proporciona el estadístico F correspondiente a la eliminación de una única variable explicativa; el estadístico F arrojado por esta sintaxis debe interpretarse como la probabilidad de materialización de la probabilidad de rechazar $H_0:β_1=B_2=⋯=B_i=0$ siendo esta verdadera. A causa de lo anterior, un valor F alto indica que la probabilidad de la materialización antes descrita es alta y, ante semejante riesgo, la decisión racional es fallar en rechazar $H_0$ sobre la significancia estadística nula global de los coeficientes de regresión. Fallar en rechazar $H_0$ implica que probabilísticamente hablando no existen consecuencias relevantes (a nivel de capacidad predictiva) si se elimina el modelo en cuestión, por lo que un F mayor que el nivel de significancia $α$ preestablecido (que es la probabilidad de cometer error tipo I, fijada por el investigador con base a la información histórica y a criterios de experto experimentado) significa que ese coeficiente de regresión no es estadísticamente relevante y puede eliminarse.
Puede escribirse el modelo completo (con los 7 predictores) y luego utilizar `drop1(mod,test="F")` para verificar cuál es la primera variable que se recomienda eliminar tras el proceso antes descrito. Como se adelantó, se deben eliminar aquellos predictores cuyo valor de probabilidad F sea más alto.
Si se comparan los resultados de la sintaxis `drop1` con los de `summary`, se puede verificar que las probabilidades F y t coinciden. Esto sucede en este ejemplo porque no hay variables categóricas con más de 2 categorías; sin embargo, cuando se cuenta con variables categóricas con más de 2 categorías, no se debe usar `summary` porque en tal caso las probabilidades F y t no son equivalentes.
“`{r} summary(moda) “`
De los resultados anteriores se desprende que el primer predictor a ser eliminado es la variable **area**, pues tiene la probabilidad F más alta. Para materializar la eliminación se puede actualizar el modelo anterior mediante `moda=update(moda,.~.-area)`.
Y así puede continuarse hasta que, por ejemplo, todas las probabilidades sean menores a 0.15 (o a algún valor$α$ preestablecido de la forma antes descrita).
Finalmente, se obtiene que el modelo sugerido contempla las variables **pop**, **crim**, **grad** y **temp**.
##### 6.2.2. Eliminación Hacia Atrás con AIC
Adicionalmente, en lugar de usar el criterio de la probabilidad F se pueden usar criterios de información. Para usar el criterio de Akaike (AIC) simplemente no se indica nada en `test`, pues el AIC es el criterio por defecto que utiliza `drop1`. En este caso, la columna de AIC indica el valor del AIC que se obtendría si se elimina esa variable. Puesto que el objetivo es aumentar el AIC (porque eso haría al predictor candidato de ser eliminado), entonces se elimina la variable que más disminuye el AIC, generando luego un nuevo modelo (con las variables que menos disminuyen el AIC) que se compara con el modelo anterior, y así sucesivamente, hasta que la eliminación de cualquier variable aumenta el AIC con respecto al modelo anterior en lugar de disminuirlo, puesto que esta es la señal que en términos de robustez estadística del modelo no es recomendable eliminar más predictores.
El procedimiento antes descrito se puede realizar de forma automática con la sintaxis `step` mediante`step(mod)`. Tras ello, puede almacenarse el resultado en una estructura de datos (aquí llamada "mod4"#") y aplicar `summary` sobre dicho objeto.
“`{r} mod4=step(mod3) summary(mod4) “`
##### 6.2.2. Eliminación Hacia Atrás con BIC
###### 6.2.2.1. Aspectos Teóricos Relevantes del BIC
Si en lugar del criterio AIC se desease utilizar el criterio bayesiano de información (BIC) se debe indicar en la sintaxis `step` mediante `k=log(n)`. Debe agregarse que, como se señala en (Bishop, Christopher M. Pattern Recognition and Machine Learning. 2006, p. 217), el criterio bayesiano de información penaliza la complejidad del modelo y es el criterio expuesto por Bishop en el lugar referido el que muestra la penalización que el BIC ejerce sobre la complejidad del modelo y que se conoce como *factor de Occam*.
“`{r} knitr::include_graphics(“FOTO4.JPG”) “`
#Figura 2: Evaluación de la log-verosimilitud empleando parámetros optimizados #Fuente: Bishop, Christopher M. Pattern Recognition and Machine Learning. 2006, p. 216-17.
Debe decirse sobre el factor de Occam que, como puede verificarse en [David J. Spiegelhalter, Nicola G. Best, Bradley P. Carlin & Angelika Van Der Linde. Bayesian measures of model complexity and fit. Journal of Royal Statistical Society, Series B (Statistical Methodology); https://rss.onlinelibrary.wiley.com/doi/pdf/10.1111/1467-9868.00353] y en (van der Linde, Angelika. A Bayesian view of model complexity. Statistica Neerlandica xx, year xx-xx, special issue: All Models Are Wrong...; https://statmodeling.stat.columbia.edu/wp-content/uploads/2013/08/snavdlmc.pdf), no existe una definición analítica para el mismo, *i.e.*, una definición que pueda ser sustentada lógicamente desde algún marco teórico en congruencia clara y directa con un marco matemático autodemostrable dentro de teoría de conjuntos ZF-C (Zermelo-Fraenkel con Axioma de Elección) que la modele.
En este sentido, la investigación de Spiegelhalter et al es una de las investigaciones más importantes de al menos las últimas dos décadas a nivel de la teoría de las probabilidades y su importancia es aún mayor si el marco de referencia es únicamente la teoría bayesiana de probabilidades. En síntesis, los autores y autora de la investigación concluyen que la medida de complejidad bayesiana (que es la estructura matemática que aparece en la obra citada de Christopher Bishop) tiene como trasfondo común con el criterio DIC (que es la versión generalizada del AIC, de naturaleza teórica frecuentista, que tiene su propia penalización de la complejidad del modelo y por consiguiente su propia medición de dicha complejidad) la teoría de la información (rama de la teoría de las probabilidades que versa sobre las estructuras matemáticas que rigen la transmisión y el procesamiento de la información y se ocupa de la medición de la información y de la representación de la misma, así como también de la capacidad de los sistemas de comunicación para transmitir y procesar información; véase https://es.wikipedia.org/wiki/Teor%C3%ADa_de_la_informaci%C3%B3n), que el DIC y el BIC tienen una justificación lógica similar aunque el DIC tiene una campo de aplicación más amplio. Adicionalmente, se señala que la metodología de medición de complejidad bayesiana que ellos proponen es aplicable a toda la clase de modelos y que únicamente requiere de un trabajo analítico "despreciable" (p. 613) relativo a la configuración de un muestreo del tipo Monte Carlo basado en cadenas de Markov. Además, existe un problema señalado por los autores y autora relativo a que es difícil explicar si las diferencias entre los criterios de medición de complejidad del BIC y del DIC son realmente diferentes en términos estadísticos, puesto que es aún más difícil determinar el error del DIC en pruebas Monte Carlo (para ello se cita una investigación previa que señala esta dificultad). La publicación de este documento de investigación generó la apertura de un debate alrededor del mismo, que contó con la participación de S. Brooks (University of Cambridge), Jim Smith (University of Warwick), Aki Vehtari (Helsinki University of Technology), Martyn Plummer (International Agency of Research on Cancer, Lyon), Mervyn Stone (University College London), Christian P. Robert (Université Paris Dauphine) y D. M. Titterington (University of Glasgow), el mismísimo J. A. Nelder en persona (Impercial College of Science, Techonology and Medicine, London), Anthony Atkinson (London School of Economics and Political Science), A. P. David (University College London), José M. Bernardo (Universitat de València), Sujit K. Sahu (University of Southampton), Sylvia Richardson (Imperial College School of Medicine, London), Peter Green (University of Bristol), Kenneth P. Burnham (US Geological Survey and Colorado State University, Fort Collins), María Delorio (University of Oxford) y Christian P. Robert (Université Paris Dauphine), David Draper (University of California, Santa Cruz), Alan E. Gelfand (Duke University Durkham) y Matilde Travisani (University of Trieste), Jim Hodges (University of Minesota, Minneapolis), Youngjo Lee (Seoul National University), Xavier de Luna (Uméa University) y, finalmente, Xiao-Li Meng (Harvard University, University of Chicago); tremendo crossover, mucho mejor que *Crisis en Tierras Infinitas (1985-86)*... palabras mayores. Los posicionamientos de los autores y autoras participantes son diversas y profundas, sin embargo, se hará una recapitulación de aquellos que señalen debilidades la medición bayesiana de complejidad de un modelo estadístico.
Brooks (p. 616-18) plantea que la investigación (como casi toda buena investigación) deja preguntas abiertas, específicamente él señala que la ecuación 9 de la página 587 utiliza para calcular dicha complejidad el valor esperado, pero ¿por qué no la moda o la mediana?, ¿cuál es la justificación teórica de ello?, y de ello se deriva también ¿cómo se debe decidir entonces que el parámetro estimado debe ser la media, la moda o la mediana?, lo cual es relevante en cuanto podría conducir a diferencias importantes con el DIC; finalmente, ¿cómo se pueden ser comparables el análisis del modelo bajo el DIC con el análisis del modelo bajo las probabilidades posteriores (enfoque bayesiano) y por qué difieren?, ¿pueden ambas ser "correctas" de alguna manera significativa?
Por su parte, Jim Smith (p. 619-20) señala que no encontró errores técnicos (*i.e.*, matemáticos), pero que encontró cuatro problemas fundacionales. El primero que señala es que las implicaciones predictivas de todas las configuraciones del prior relativas a las variaciones en los ejemplos resueltos en la Sección 8 son increíbles (no en un sentido que podría considerarse positivo), puesto que según Smith no representan juicios de expertos cuidadosamente obtenidos, sino las opiniones de un usuario de software vacío. También señala que, al principio de la Sección 1, los autores afirman que quieren identificar modelos sucintos que parecen describir la información [¿acerca de valores de parámetros "verdaderos" incorrectos (ver Sección 2.2)?] en los datos con precisión, sin embargo, señala también que en un análisis bayesiano, la separación entre la información de los datos y el prior es artificial e inapropiada; señala que "Un análisis bayesiano en nombre de un experto en auditoría remota (Smith, 1996) podría requerir la selección de un prior que sea robusto dentro de una clase de creencias de diferentes expertos (por ejemplo, Pericchi y Walley (1991)). A veces, los prior predeterminados pueden justificarse para modelos simples. Incluso entonces, los modelos dentro de una clase de selección deben tener parametrizaciones compatibles: ver Moreno et al. (1998). Sin embargo, en los ejemplos en los que "el número de parámetros supera en número a las observaciones", afirman que sus enfoques de enfoque, es poco probable los prior predeterminados (por defecto) muestren alguna robustez (estadística). En particular, fuera del dominio de la estimación local vaga o de la estimación de la varianza de separación (discutida en la Sección 4), aparentemente los antecedentes por defecto pueden tener una fuerte influencia en las implicaciones del modelo y, por lo tanto, en la selección.", de lo cual se deriva una razonable insatisfacción ante la expresión la afirmación de los autores y autora sobre la baja probabilidad de que los prior muestren robustez.
Martyn Plummer (p. 621) señala lo que a su juicio son debilidades en la derivación heurística del DIC y de ello se deriva su señalamiento de sustento formal ;como señalan (Rosental & Iudin. Diccionario Filosófico. Editorial Tecolut, 1971. p. 215-216),
en términos históricos la palabra "heurística" proviene del griego εὑρίσκω, que significa "discuto". Es el arte de sostener una discusión y floreció sobre todo entre los sofistas de la antigua Grecia. Surgida como medio de buscar la verdad a través de la polémica, se escindió pronto en dialéctica y sofística. Sócrates, con su método, desarrolló la primera. En cambio, la sofística, tendiente sólo a alcanzar la victoria sobre el contrincante en la discusión, redujo la heurística a una suma de procedimientos que podían aplicarse con el mismo éxito tanto para demostrar una aseveración, cualquiera que fuese, como para refutarla. De ahí que ya Aristóteles no estableciera ninguna diferencia entre heurística y sofística. En la actualidad, al hablar de métodos heurísticos se hace referencia a una especie de atajos para las derivaciones rigurosas que implican mayor costo computacional, por lo que su carácter de verdad es siempre de corto plazo (provisional).
Mervyn Stone (p. 621) señala que la investigación de 2002 "bastante económico" en lo relativo a la *verdad fundamental* (véase https://marxistphilosophyofscience.com/wp-content/uploads/2020/12/sobre-los-estimadores-de-bayes-el-analisis-de-grupos-y-las-mixturas-gaussianas-isadore-nabi.pdf, p. 43-44), que si la sección 7.3 pudiera desarrollarse rigurosamente (puesto que le parece gnoseológicamente cuestionable el uso de $E_Y$), "(...) otra conexión (a través de la ecuación $(33)$) podría ser que $DIC ≈ −2A$. Pero, dado que la sección 7.3 invoca el supuesto de "buen modelo" y pequeños $|\hat{θ}-θ|$ para la expansión de la serie de Taylor (es decir, $n$ grande), tal conexión sería tan artificial como la de $A$ con el criterio de información de Akaike: ¿por qué no seguir con la forma prístina (hoy en día calculable) de $A$, que no necesita $n$ grande o verdad? , ¿y cuál acomoda la estimación de θ en el nivel de independencia de un modelo bayesiano jerárquico? Si la sensibilidad del logaritmo a probabilidades insignificantes es objetable, los bayesianos deberían estar felices de sustituirlo por una medida subjetivamente preferible de éxito predictivo." Es imposible cuestionar a Stone en cuanto a que, dado el enseñoramiento que en la teoría bayesiana de probabilidades tiene la escuela bayesiana subjetiva, el promedio del gremio bayesiano estaría filosóficamente satisfecha con renunciar a elementos objetivos (en este caso son requerimientos preestablecidos por la teoría del aprendizaje estadístico que condicionan la validez gnoseológica del modelo propuesto como un todo, como una muestra grande y/o una verdad fundamental) si representan un punto de discordia y pueden ser sustituidos por algún criterio de decisión que pueda ser determinado; que en paz descanse su alma https://www.ucl.ac.uk/statistics/sites/statistics/files/meryvn-stone-obituary.pdf.
Christian P. Robert y D. M. Titterington (p. 621) señalan que la estructura matemática planteada por los autores de la investigación para determinar la complejidad de un modelo desde la perspectiva bayesiana parecería hacer un uso duplicado (repetido en dos ocasiones) del conjunto de datos, la primera vez lo hacen para determinar la distribución posterior y la segunda para calcular la verosimilitud observada (o verosimilitud a priori, sin considerar información adicional). Este uso duplicado del conjunto de datos puede conducir a un sobreajuste del modelo; señalan que este tipo específico de problemática surgió antes en la investigación de (Aitkin, 1991).
Seguramente el invitado más célebre entre todos los que asistieron a este maravilloso coloquio académico fue John Nelder, padre de los modelos lineales generalizados. Antes de exponer su planteamiento, deben introducirse algunas cuestiones. En primer lugar, el *escape de amoníaco* en aplicaciones industriales es a lo que los autores se refieren (y se refirará Nelder) como *stack loss* (p. 609). En segundo lugar, la tabla 2 a la que se referirá Nelder es la siguiente:
“`{r} knitr::include_graphics(“TABLA2.JPG”) “`
#Figura 3: Tabla 2. Resultados de desviación para los datos de pérdida de amoníaco. #Fuente: Spiegelhalter, Best, Carlin & van der Linde. Bayesian measures of model complexity and fit, p. 610.
Así, Nelder (p. 622) señala: "Mi colega, el profesor Lee, ha planteado algunos puntos generales que conectan el tema de este artículo con nuestro trabajo sobre modelos lineales generalizados jerárquicos basados en la probabilidad. Quiero plantear un punto específico y dos generales. (a) El profesor Dodge ha demostrado que, de las 21 observaciones en el conjunto de datos de pérdida de amoníaco, ¡solo cinco no han sido declaradas como valores atípicos por alguien! Sin embargo, existe un modelo simple en el que ninguna observación aparece como un valor atípico. Es un modelo lineal generalizado con distribución gamma, log-link y predictor lineal x2 + log.x1 / Å log.x3 /: Esto da las siguientes entradas para la Tabla 2 en el documento: 98.3 92.6 6.2 104.5 (estoy en deuda con el Dr. Best por calcularlos). Es claramente mejor que los modelos existentes usados en la Tabla 2. (b) Este ejemplo ilustra mi primer punto general. Creo que ha pasado el tiempo en que bastaba con asumir un vínculo de identidad para los modelos y permitir que la distribución solo cambiara. Deberíamos tomar como nuestro conjunto de modelos de línea base al menos la clase de modeloos lineales generalizados definida por distribución, enlace y predictor lineal, con la elección de escalas para las covariables en el caso del predictor lineal. (c) Mi segundo punto general es que, para mí, no hay suficiente verificación de modelos en el artículo (supongo que el uso de tales técnicas no va en contra de las reglas bayesianas). Por ejemplo, si un conjunto de efectos aleatorios es suficientemente grande en número y el modelo postula que están distribuidos normalmente, sus estimaciones deben graficarse para ver si se parecen a una muestra de tal
distribución. Si parecen, por ejemplo, fuertemente bimodales, entonces el modelo debe revisarse." Que en paz descanse su alma.
Anthony Atkinson (p. 622) señala que dirige su participación al contexto de la regresión, concluyendo que este criterio de selección de modelos (el BIC planteado por los autores, que es el estimado mediante la sintaxis de R) es un primer paso, que necesita ser complementado
mediante pruebas de diagnóstico y gráficos. Para finalizar plantea que "Estos ejemplos muestran que la búsqueda hacia adelante es una herramienta extremadamente poderosa para este propósito. También requiere muchos ajustes del modelo a subconjuntos de datos. ¿Puede combinarse con los apreciables cálculos de los métodos de Monte Carlo de la cadena de Markov de los autores?" Que en paz descanse su alma.
A.P. Dawid plantea que el artículo debería haberse titulado "Medidas de la complejidad y el ajuste del modelo bayesiano", ya que según él son los modelos, no las medidas, los que son bayesianos. Una vez que se han especificado los ingredientes de un problema, cualquier pregunta relevante tiene una respuesta bayesiana única. La metodología bayesiana debe centrarse en cuestiones de especificación o en formas de calcular o aproximar la respuesta. No se requiere nada más (...) Un lugar donde un bayesiano podría querer una medida de la complejidad del modelo es como un sustituto de p en la aproximación del criterio de información de Bayes a la probabilidad marginal, por ejemplo, para modelos jerárquicos. Pero en tales casos, la definición del tamaño de muestra $n$ puede ser tan problemática como la de la dimensión del modelo $p$. Lo que necesitamos es un mejor sustituto del término completo $p⋅log(n)$". En línea con la gnoseología marxiana, lo adecuado parecería ser considerar que tanto los modelos como las medidas son bayesianos (o de otra escuela de filosofía de las probabilidades).
Las participaciones restantes son no tanto relativas a cuestiones metodológicas como a cuestiones filosóficas-fundacionales de la teoría bayesiana de las probabilidades y de la teoría de las probabilidades en general (puesto que el DIC, que es un criterio de información presentado por los mismos autores que presentan el BIC, no es bayesiano debido a que es una generalización del AIC -que es frecuentista-); de hecho, la transición de cuestiones metodológicas a filosóficas-fundacionales se expresa en el planteamiento de Dawid, quien aunque aborda cuestiones metodológicas lo hace con base en la lógica filosófica de que los modelos y no las medidas son los que pueden ser (o no) bayesianos. Por supuesto, estas últimas son las participaciones más importantes, sin embargo, abordalas escapa a los límites de esta investigación, por lo que para tan importante tarea se dedicará indudablemente un trabajo posterior.
###### 6.2.2.2. Ejecución de la Eliminación Hacia Atrás con el BIC
“`{r} n = nrow(base) mod5=step(mod3,k=log(n)) summary(mod5) “`
#### 6.3. Método de Selección Hacia Adelante en R
A propósito de lo señalado por Anthony Atkinson, para realizar un proceso de selección hacia adelante se puede usar la función `add1` inciando con un modelo que no contenga ninguna variable e indicando en `scope` cuales son todas las variables disponibles. Ello se realiza de la siguiente forma: `add1(modb, scope=~pop + ingre + analf + crim + grad + temp + area)`.
En este caso se escoge agregar la variable que disminuya más el AIC. En este caso es **crim**. Se actualiza el modelo y se continúa hasta que todas tengan un AIC más bajo que el anterior: `modb=update(modb,.~.+crim)`.
De forma similar se puede usar `step` para indicar `scope` (además de indicar `direction="forward"`) de la siguiente forma: `step(mod6,direction="forward",scope=~pop + ingre + analf + crim + grad + temp + area)`. `scope` "define la gama de modelos examinados en la búsqueda por pasos. Debe ser una fórmula única o una lista que contenga los componentes superior e inferior, ambas fórmulas. Consulte los detalles sobre cómo especificar las fórmulas y cómo se utilizan." (véase https://stat.ethz.ch/R-manual/R-devel/library/MASS/html/stepAIC.html).
En este caso, tiene la logica del modelo hacia adelante, se va ingresando las variables que reducen el AIC y luego quedan las que no estan en el modelo, osea las que incrementaria el AIC.
Se realizó un estudio para analizar la velocidad de nado de las personas mayores de 18 años que son miembros regulares de un equipo de natación, y se tomaron en cuenta algunas variables que pueden estar relacionadas con esta velocidad. Se hizo una prueba a los participantes y se tomó el tiempo que duraban en nadar 50m. Entonces como medida de la velocidad de nado se tiene el tiempo (en segundos) el cual se puede transformar a la velocidad dividiendo la distancia entre el tiempo. Esta variable se llama veloc. Como variables predictoras se tienen las siguientes:
edad: la edad en años cumplidos.
sexo: el sexo codificado como 0 (mujeres) y 1 (hombres).
imc: el índice de masa corporal se calcula dividiendo el peso en kilogramos entre la altura al cuadrado (en metros), lo cual da una medida en $kg/m^2$.
pierna: la longitud promedio de ambas piernas (en centímetros).
brazo: la longitud promedio de ambos brazos (en centímetros).
A.2. MÉTODOS Y TÉCNICAS ESTADÍSTICAS ESTUDIADAS Y APLICADAS
Análisis descriptivo con la sintaxis xyplot de la librería “lattice”.
Análisis descriptivo con la sintaxis scatterplot de la librería “car”.
Correlación lineal de Pearson.
Correlograma.
Estimación del valor esperado de la variable de respuesta.
Coeficientes de regresión estandarizados internamente y externamente.
Construccción manual y automatizada del modelo de regresión.
Construcción y descomposición manual de la suma de cuadrados.
Construcción manual y automatizada de intervalos de confianza t de Student.
Construcción manual y automatizada de los intervalos de predicción t de Student.
Construcción automatizada de los intervalos de tolerancia bayesianos normalmente distribuidos.
Ajuste de distribución de probabilidad.
Gráfico Q-Q.
Gráfico de probabilidad acumulada.
Gráfico P-P.
Pruebas de normalidad.
Simulación de estimación pseudo-aleatoria mediante una sintaxis de tipo bucle.
Efectos marginales.
Construcción manual de la prueba F.
Prueba de hipótesis de significancia global y local de los coeficientes de regresión.
b. ECONOMÍA POLÍTICA
B.1. cASO DE APLICACIÓN
Estudiar estadísticamente, como parte de un ejercicio pedagógico, los determinantes fundamentales lineales de la tasa media de ganancia para el caso de Estados Unidos en el período 1964-2008 mediante un análisis de regresión lineal.
B.2. MÉTODOS Y TÉCNICAS ESTADÍSTICAS ESTUDIADAS Y APLICADAS
Análisis descriptivo de tendencias con las sintaxis plot_ly y add_trace.
Análisis descriptivo de las influencias o ‘leverages’.
Construcción automatizada del modelo de regresión.
Verificación del modelo de mejor ajuste vía eliminación hacia atrás mediante el Criterio Bayesiano de Información (BIC).
Análisis de la capacidad predictiva del modelo.
Ajuste de distribución.
Contrastes de normalidad.
Distancia de Cook.
Pruebas de multicolinealidad.
Pruebas de autocorrelación.
Pruebas de heterocedasticidad.
Errores Estándar Robustos en presencia de Heterocedasticidad y Autocorrelación (Errores Estándar HAC).
Pruebas de especificación del modelo.
Construcción automatizada de intervalos de confianza t de Student.
Si las medias r-ésimas (los r-ésimos estadísticos de prueba) son únicas y existe convergencia en distribución entre las muestras en comparación distribución, estas tendrán también las mismas medias r-ésimas. Para garantizar la unicidad de los momentos debe garantizarse que la muestra y la población sean finitas o, a lo sumo, infinitas numerables (que sea posible poderla poner en correspondencia uno-a-uno con los números naturales); mientras que para garantizar que converjan en distribución debe garantizarse (aunque no es el único camino, más sí el óptimo para estos fines) antes la convergencia en media r-ésima, que para el caso de los espacios euclidianos y sus generalizaciones naturales (los espacios de Hilbert) debe ser convergencia en media cuadrática (porque la norma de tales espacios es de carácter cuadrático y sirve para estimar distancias bajo una lógica también cuadrática). Adicionalmente, en términos matemáticos, que converjan en media cuadrática garantiza que converjan en varianza. Que converjan en media cuadrática se verifica, en el contexto de los espacios ya mencionados, cuando se certifica a través de una prueba de hipótesis rigurosa que las medias de las dos poblaciones no difieren en términos estadísticamente significativos. Si el conjunto de condiciones anteriormente expuesto se cumple, entonces que dos muestras tengan la misma distribución y la misma media implica que su varianza será igual, lo que formalmente hablando implica que sus varianzas tenderán a ser iguales a medida se aproximen al tamaño de la población de la cual son parte. Debido a que una distribución no es caracterizada unívocamente por sus momentos sino por su función característica (si todos sus momentos son finitos), la cual es la solución a la ecuación integral generada tras la aplicación de la transformación de Fourier a la distribución de probabilidad en cuestión, la unicidad de los momentos implica formalmente hablando, además de la restricción antes impuesta sobre el tamaño de la muestra y la población, que las distribuciones de probabilidad tengan la misma función característica. Los parámetros de transformación de Fourier son, por definición, los mismos para todos los casos (a=1, b=1). El hecho de que las poblaciones sean o no sean homogéneas no es explícitamente relevante en términos teóricos puesto que la matemática pura no establece teoremas contemplando aspectos esenciales de los fenómenos que modela de manera abstracta-formal (garantiza que la heterogeneidad no sea un problema -en el terreno asintótico- al establecer los pre-requisitos antes mencionados, como se verá en el contexto aplicado). En términos aplicados es, sin lugar a dudas, completamente relevante porque puede tener implicaciones en que la diferencia en variabilidad de las muestras sea estadísticamente significativa; sin embargo, lo que se desprende en términos prácticos de lo expuesto teóricamente antes es que si dos muestras tienen la misma forma geométrica general (la misma distribución, que implica que los conjuntos de datos siguen el mismo patrón geométrico), más allá de variaciones de escala (producto de variaciones no significativas en los parámetros, es decir, variaciones que no cambian el tipo específico de distribución de la que se trate) y además existe convergencia en media (que es una forma rigurosa de expresar que, aproximadamente hablando, tendrán la misma media), también existirá convergencia en varianza, es decir, que las varianzas, diferirán a lo sumo, en una constante arbitraria C*, que se expresa teóricamente como el residuo de la solución a la ecuación integral antes mencionada. Por lo anterior, no es necesario realizar una prueba de potencia para la igualdad de varianzas establecida con prueba F, simplemente basta con verificar que las poblaciones sean las mismas, tengan el mismo tamaño de muestra y tengan la misma media para saber que tendrán la misma varianza o segundo momento.
Como se señala en (Eppinger & Browning, 2012, págs. 2-4), la matriz de diseño estructural (DSM de ahora en adelante, por sus siglas en inglés) es una herramienta de modelado de redes que se utiliza para representar los elementos que componen un sistema y sus interacciones, destacando así la arquitectura del sistema (o estructura diseñada). DSM se adapta particularmente bien a aplicaciones en el desarrollo de sistemas de ingeniería complejos y, hasta la fecha, se ha utilizado principalmente en el área de gestión de ingeniería. Sin embargo, en el horizonte hay una gama mucho más amplia de aplicaciones de DSM que abordan problemas complejos en la gestión de la atención médica, los sistemas financieros, las políticas públicas, las ciencias naturales y los sistemas sociales. El DSM se representa como una matriz cuadrada N x N, que mapea las interacciones entre el conjunto de N elementos del sistema. DSM, una herramienta muy flexible, se ha utilizado para modelar muchos tipos de sistemas. Dependiendo del tipo de sistema que se modele, DSM puede representar varios tipos de arquitecturas. Por ejemplo, para modelar la arquitectura de un producto, los elementos de DSM serían los componentes del producto y las interacciones serían las interfaces entre los componentes (figura 1.1.a).
Fuente: (Eppinger & Browning, 2012, pág. 1).
Para modelar la arquitectura de una organización, los elementos de DSM serían las personas o equipos de la organización, y las interacciones podrían ser comunicaciones entre las personas (figura l.1.b). Para modelar una arquitectura de proceso, los elementos del DSM serían las actividades en el proceso, y las interacciones serían los flujos de información y/o materiales entre ellos (figura l.l.c). Los modelos DSM de diferentes tipos de arquitecturas pueden incluso combinarse para representar cómo se relacionan los diferentes dominios del sistema dentro de un sistema más grande (figura l.l.d). Por tanto, el DSM es una herramienta genérica para modelar cualquier tipo de arquitectura de sistema. En comparación con otros métodos de modelado de redes, el principal beneficio de DSM es la naturaleza gráfica del formato de visualización de la matriz. La matriz proporciona una representación muy compacta, fácilmente escalable y legible de forma intuitiva de la arquitectura de un sistema. La figura l.3.a muestra un modelo DSM simple de un sistema con ocho elementos, junto con su representación gráfica dirigida equivalente (dígrafo) en la figura 1.3.b.
Fuente: (Eppinger & Browning, 2012, pág. 4).
En comparación con otros métodos de modelado de redes, el principal beneficio de DSM es la naturaleza gráfica del formato de visualización de la matriz. La matriz proporciona una representación muy compacta, fácilmente escalable y legible de forma intuitiva de la arquitectura de un sistema. La figura l.3.a muestra un modelo DSM simple de un sistema con ocho elementos, junto con su representación equivalente como grafo dirigido (dígrafo) en la figura 1.3.b. En los estudios iniciales de DSM, a muchos les resulta fácil pensar que las celdas a lo largo de la diagonal de la matriz representan los elementos del sistema, análogos a los nodos en el modelo de dígrafo; sin embargo, es necesario mencionar que, para mantener el diagrama de matriz compacto, los nombres completos de los elementos a menudo se enumeran a la izquierda de las filas (y a veces también encima de las columnas) en lugar de en las celdas diagonales. También es fácil pensar que cada celda sobre la diagonal principal de la matriz puede tener entradas que ingresan desde sus lados izquierdo y derecho y salidas que salen desde arriba y abajo. Las fuentes y destinos de estas interacciones de entrada y salida se identifican mediante marcas en las celdas fuera de la diagonal (en la figura anterior expresadas con una letra X) análogas a los arcos direccionales en el modelo de dígrafo. Examinar cualquier fila de la matriz revela todas las entradas del elemento en esa fila (que son salidas de otros elementos).
Si se observa hacia abajo, cualquier columna de la matriz muestra todas las salidas del elemento en esa columna (que se convierten en entradas para otros elementos). En el ejemplo simple de DSM que se muestra en la figura 1.3.a, los ocho elementos del sistema están etiquetados de la A a la H, y hemos etiquetado tanto las filas como las columnas de la A a la H en consecuencia. Al leer la fila D, por ejemplo, vemos que el elemento D tiene entradas de los elementos A, B y F, representados por las marcas X en la fila D, columnas A, B y F. Al leer la columna F, vemos ese elemento F tiene salidas que van a los elementos B y D. Por lo tanto, la marca en la celda fuera de la diagonal [D, F] representa una interacción que es tanto una entrada como una salida dependiendo de si se toma la perspectiva de su proveedor (columna F) o su receptor (fila D). Es importante notar que muchos recursos de DSM usan la convención opuesta, la transposición de la matriz, con las entradas de un elemento mostradas en su columna y sus salidas mostradas en su fila. Las dos convenciones transmiten la misma información, y ambas se utilizan ampliamente debido a las diversas raíces de las herramientas basadas en matrices para los sistemas de modelado.
En este sentido, como se verifica en (IBM, 2021), en diversos escenarios aplicados puede existir más de una función discriminante[1], como se muestra a continuación.
Fuente: (IBM, 2021).
En general, como se verifica en (Zhao & Maclean, 2000, pág. 841), el análisis discriminante canónico (CDA, por nombre en inglés) es una técnica multivariante que se puede utilizar para determinar las relaciones entre una variable categórica y un grupo de variables independientes. Uno de los propósitos principales de CDA es separar clases (poblaciones) en un espacio discriminante de menor dimensión. En este contexto es que cuando existe más de una función discriminante (cada una de estas puede verse como un modelo de regresión lineal), un asterisco (*) como en este caso (para el caso del programa SaaS) u otro símbolo denotará la mayor correlación absoluta de cada variable con una de las funciones canónicas. Dentro de cada función, estas variables marcadas se ordenan por el tamaño de la correlación. Para el caso de la tabla presentada en la figura anterior, su lectura debe realizarse de la siguiente manera:
“Nivel educativo” está más fuertemente correlacionado con la primera función y es la única variable más fuertemente correlacionada con esta función.
Años con empresa actual, “Edad” en años, “Ingresos del hogar” en miles, “Años” en la dirección actual, “Retirado” y “Sexo” están más fuertemente correlacionados con la segunda función, aunque “Sexo” y “Jubilación” están más débilmente correlacionados que los otros. Las demás variables marcan esta función como función de “estabilidad”.
“Número de personas en el hogar” y “Estado civil” están más fuertemente correlacionados con la tercera función discriminante, pero esta es una función sin utilidad, así que estos predictores son prácticamente inútiles.
[1] Como se verifica en (de la Fuente Fernández, pág. 1), un discriminante es cada una de las variables independientes con las que se cuenta. Además, como se verifica en (IBM, 2021), una función discriminante es aquella que, mediante las diferentes combinaciones lineales de las variables predictoras, busca realizar la mejor discriminación posible entre los grupos. No debe olvidarse que, como se señala en (Wikipedia, 2021), En el campo del aprendizaje automático, el objetivo de la clasificación estadística es utilizar las características de un objeto para identificar a qué clase (o grupo) pertenece.
Este día se publicó una investigación en el sitio web de Michael Roberts que versa, en general, sobre el papel del desarrollo tecnológico en el comercio internacional como mecanismo de acumulación de capital característico de la economía capitalista planetaria en su fase imperialista. Sobre dicha investigación se elabora la presente publicación, la cual está compuesta por tres secciones. En la primera sección se realiza un breve abordaje histórico sobre aspectos teóricos de interés abordados por Roberts en su publicación de naturaleza fundamentalmente empírica. En la segunda sección se presenta la traducción de la publicación de Roberts. Finalmente, en la tercera sección se facilita la descarga de las referencias bibliográficas presentadas por Roberts en su publicación.
I. ASPECTOS TEÓRICOS preliminares
Es importante decir que la teoría sobre el capitalismo en su fase imperialista hunde sus raíces empíricas más importantes el trabajo de Vladimir Lenin (1916) y sus raíces teóricas más importantes en el trabajo de Arghiri Emmanuel (1962). Por supuesto, el trabajo de Lenin no se limitó a ser empírico, pero fue en esta dirección la centralización de sus esfuerzos y ello conforma un punto de partida razonable para un breve análisis sobre cómo (y por qué) han evolucionado las teorías marxistas sobre el imperialismo.
Lenin fue el primer teórico del marxismo que estudió la acumulación de capital a escala planetaria considerando las relaciones centro-perisferia como una generalización económica, política, social y cultural de la lucha de clases nacional; sobre ello no existe debate relevante en el seno de la comunidad marxista. La armonía no es tal cuando se trata de abordar la obra de Arghiri Emmanuel. Cualquier persona lo suficientemente estudiosa de la historia de las ciencias sabrá que, sobre todo en ciencias sociales (con especial énfasis en economía política), la aceptación de una teoría no tiene que ver con motivos puramente académicos sino también políticos. La teoría de economía política internacional (de ahora en adelante economía geopolítica) de Emmanuel tuvo poca aceptación entre la comunidad marxista fundamentalmente no por su polémico uso de la ley del valor en el concierto internacional, sino por las conclusiones políticas que su teoría generaba. La idea central de Emmanuel es que en el concierto interncional ocurre una transformación global de valores a precios de producción como la que ocurre (salvo las particularidades naturales características del incremento en complejidad del sistema) a escala local o nacional. Es esa y no otra la idea fundamental del trabajo de Emmanuel, con independencia del grado de acuerdo (o desacuerdo) que se tenga sobre la forma en que realiza tal planteamiento. La lógica que condujo a Emmanuel a la construcción de esta idea, que no es más que una aplicación global de la lógica local de la transformación de valores en precios de producción ya dada por Marx, parecería ser la misma que la que condujo a construir, por ejemplo, la teoría de la selección natural o la teoría matemática del caos el concepto de autosimilaridad. Esta esta lógica se puede generalizar como se plantea a continuación.
Los componentes (modelados mediante ecuaciones) de una totalidad (modelada mediante un sistema de ecuaciones) comparten una esencia común (i.e., que son isomórficos entre sí) que permite su combinación integrodiferencial de forma armónica y coherente bajo una determinada estructura interna de naturaleza material (objetiva), no-lineal (la totalidad es diferente a la suma de sus partes) y dinámica (el tiempo transcurre) generada por la interacción de tales componentes dadas determinadas condiciones iniciales. La estructura interna del sistema (o totalidad de referencia) condiciona a los componentes que la generan bajo el mismo conjunto de leyes (pero generalizado, por lo que no es formalmente el mismo) que rigen la interacción entre las condiciones iniciales y las relaciones primigenias entre componentes que determinaron la gestación de dicha estructura interna. Estas leyes son: 1. Unidad y Lucha de los Contrarios (que implica emergencia y al menos autoorganización crítica), 2. Salto de lo Cuantitativo a lo Cualitativo (bifurcación), 3. Ley de la Negación de la Negación (que es una forma generalizada de la síntesis química).
SOBRE DIALÉCTICA Y COMPLEJIDAD
Antes de proceder a exponer las fuentes formales y fácticas de la poca popularidad de las teorías de Emmanuel, es necesario decir un par de cuestiones relativas al papel que desempeña el tiempo en el sistema marxiano. Las escuelas de pensamiento económico marxista se pueden clasificar según su abordaje matemático del proceso histórico de transformación de valores en precios de producción; sin embargo, aún dentro de las mismas escuelas existen divergencias teóricas importantes, fundamentalmente en relación a la MELT (Monetary Expression of Labor Time) o algún equivalente de esta. Así, las escuelas de pensamiento económico marxista son la escuela temporalista, la escuela simultaneísta y alguna combinación o punto intermedio entre ellas. Todas estas diferencias filosóficas, en contraste con lo que ocurre en Filosofía de la Estadística entre, por ejemplo, frecuentistas y bayesianos subjetivos, no solo no requieren de mucha investigación para ser verificadas empíricamente, sino que además tienen como consecuencia la gestación de sistemas matemáticos que hasta la fecha (la realidad es cambiante, indudablemente) han resultado antagónicos teóricamente respecto de ese punto (en el de transformar valores en precios de producción) y numéricamente diferentes de forma sustancial en sus predicciones (aunque cualitativamente es usual que sus diferencias no sean esenciales, salvo en el punto expuesto -que es evidentemente un aspecto medular de la teoría de Marx-).
La polémica sobre el uso de la ley del valor de Emmanuel tuvo que ver con el manejo de los supuestos que realizó y, con ello, con los escenarios teóricos que identificaba con la realidad. Esta polémica se agudizó luego de que, tras las críticas recibidas (cuyo trasfondo era teórico solo formalmente o minoritariamente en su defecto), Emmanuel publicara un sistema de ecuaciones simultáneas (con ello se ganó el rechazo de los marxistas más conservadores de la época -los cuales eran reacios al uso de las matemáticas-, que no eran minoría) para abordar la transformación de valores en precios de producción) poco ortodoxo para el oficialismo de lo que se podría denominar como “marxismo matemático”, lo que en términos netos le valió para la época (1962) incompatibilidad intelectual con la generalidad de los académicos.
El debate teórico real no es, evidentemente, si el tiempo existe o no, sino si es lo suficientemente relevante para configurar el sistema matemático alrededor del mismo o si no lo es y, por consiguiente, no existen consecuencias relevantes (tanto teóricas como numéricas) por descartarlo del modelo formal del sistema capitalista. Emmanuel define en su obra el valor como cantidad cronométrica de trabajo socialmente necesario (que es la misma definición del marxismo clásico, sólo que comprimida), sin embargo, su modelo de transformación de valores en precios de producción hace uso de las ecuaciones simultáneas (lo heterodoxo del asunto radica en que establece ex ante al trabajo como la variable fundamental del sistema, para que las ecuaciones y las incógnitas se igualen automáticamente y afirmar con ello que se implica la anterioridad histórica de la fuerza de trabajo, puesto que lo precede teóricamente), aunque tampoco por ello tenga problema en afirmar que existen “dos esencias” (el capital y el trabajo) o, en otros términos, que no sólo el trabajo crea valor. ¿Cuál fue entonces el trasfondo político?
A pesar de que en tiempos modernos pueda resultar un poco difícil de pensar, alrededor de 1962 existía un relativamente pujante movimiento obrero internacional y políticamente su unidad era cardinal en la lucha contra la explotación planeataria y el modelo de Emmanuel, guste o no, implica que el bienestar de los trabajadores de los países industrializados es sufragado indirectamente por las condiciones de miseria extrema que se viven en los países de la periferia. Por supuesto, ello se implica también a nivel local, ¿quiénes permiten que los trabajadores de las ramas productivas más intensivas en capital obtengan salarios muy por encima del promedio salarial nacional sino los trabajadores de las ramas productivas intensivas en trabajo?, en un sistema de economía política los agentes económicos guardan entre sí relaciones de suma cero, es decir, la ganancia de unos implica la pérdida de otros, aunque esto no siempre ocurre (y mucho menos se observa) de forma inmediata; este hecho fundamental no cambia en un sistema de economía geopolítica. Sin embargo, aunque la topología en ambos sistemas es fundamentalmente la misma las métricas cambian y las grandes brechas sociales observadas internacionalmente (por ejemplo, entre Noruega y Haití) no se observan en términos generales (promedio) a nivel local, lo que hace más notoria la explotación, aunque no más real. Complementariamente, debe resaltarse el hecho de que, dentro de sus propias condiciones materiales de existencia, los trabajadores de los países industrializados tienen sus propias luchas sociales.
Mi máximo cariño, aprecio y admiración a toda la comunidad marxista de aquella época, puesto que al fin y al cabo lucha de clases fáctica es nuestra misión última y todos somos producto de nuestras condiciones históricas, es decir, aunque hacemos la historia, no hacemos las condiciones bajo las cuales hacemos nuestra historia.
II. IIPPE 2021: imperialism, China and finance – michael roberts
La conferencia 2021 de la Iniciativa Internacional para la Promoción de la Economía Política (IIPPE) tuvo lugar hace un par de semanas, pero solo ahora he tenido tiempo de revisar los numerosos trabajos presentados sobre una variedad de temas relacionados con la economía política. El IIPPE se ha convertido en el canal principal para que economistas marxistas y heterodoxos ‘presenten sus teorías y estudios en presentaciones. Las conferencias de materialismo histórico (HM) también hacen esto, pero los eventos de HM cubren una gama mucho más amplia de temas para los marxistas. Las sesiones de Union for Radical Political Economy en la conferencia anual de la American Economics Association se concentran en las contribuciones marxistas y heterodoxas de la economía, pero IIPPE involucra a muchos más economistas radicales de todo el mundo.
Ese fue especialmente el caso de este año porque la conferencia fue virtual en zoom y no física (¿tal vez el próximo año?). Pero todavía había muchos documentos sobre una variedad de temas guiados por varios grupos de trabajo del IIPPE. Los temas incluyeron teoría monetaria, imperialismo, China, reproducción social, financiarización, trabajo, planificación bajo el socialismo, etc. Obviamente no es posible cubrir todas las sesiones o temas; así que en esta publicación solo me referiré a las que asistí o en las que participé.
El primer tema para mí fue la naturaleza del imperialismo moderno con sesiones que fueron organizadas por el grupo de trabajo de Economía Mundial. Presenté un artículo, titulado La economía del imperialismo moderno, escrito conjuntamente por Guglielmo Carchedi y yo. En la presentación argumentamos, con evidencia, que los países imperialistas pueden definirse económicamente como aquellos que sistemáticamente obtienen ganancias netas, intereses y rentas (plusvalía) del resto del mundo a través del comercio y la inversión. Estos países son pequeños en número y población (solo 13 o más califican según nuestra definición).
Demostramos en nuestra presentación que este bloque imperialista (IC en el gráfico a continuación) obtiene algo así como 1,5% del PIB cada año del ‘intercambio desigual’ en el comercio con los países dominados (DC en el gráfico) y otro 1,5% del PIB de intereses, repatriación de utilidades y rentas de sus inversiones de capital en el exterior. Como estas economías están creciendo actualmente a no más del 2-3% anual, esta transferencia es un apoyo considerable al capital en las economías imperialistas.
Los países imperialistas son los mismos “sospechosos habituales” que Lenin identificó en su famosa obra hace unos 100 años. Ninguna de las llamadas grandes “economías emergentes” está obteniendo ganancias netas en el comercio o las inversiones – de hecho, son perdedores netos para el bloque imperialista – y eso incluye a China. De hecho, el bloque imperialista extrae más plusvalía de China que de muchas otras economías periféricas. La razón es que China es una gran nación comercial; y también tecnológicamente atrasado en comparación con el bloque imperialista. Entonces, dados los precios del mercado internacional, pierde parte de la plusvalía creada por sus trabajadores a través del comercio hacia las economías más avanzadas. Esta es la explicación marxista clásica del “intercambio desigual” (UE).
Pero en esta sesión, esta explicación de los logros imperialistas fue discutida. John Smith ha producido algunos relatos convincentes y devastadores de la explotación del Sur Global por parte del bloque imperialista. En su opinión, la explotación imperialista no se debe a un “intercambio desigual” en los mercados entre las economías tecnológicamente avanzadas (imperialismo) y las menos avanzadas (la periferia), sino a la “superexplotación”. Los salarios de los trabajadores del Sur Global han bajado incluso de los niveles básicos de reproducción y esto permite a las empresas imperialistas extraer enormes niveles de plusvalía a través de la “cadena de valor” del comercio y los márgenes intraempresariales a nivel mundial. Smith argumentó en esta sesión que tratar de medir las transferencias de plusvalía del comercio utilizando estadísticas oficiales como el PIB de cada país era una ‘economía vulgar’ que Marx habría rechazado porque el PIB es una medida distorsionada que deja fuera una parte importante de la explotación de la economía global. Sur.
Nuestra opinión es que, incluso si el PIB no captura toda la explotación del Sur Global, nuestra medida de intercambio desigual todavía muestra una enorme transferencia de valor de las economías periféricas dependientes al núcleo imperialista. Además, nuestros datos y medidas no niegan que gran parte de esta extracción de plusvalía proviene de una mayor explotación y salarios más bajos en el Sur Global. Pero decimos que esta es una reacción de los capitalistas del Sur a su incapacidad para competir con el Norte tecnológicamente superior. Y recuerde que son principalmente los capitalistas del Sur los que están haciendo la “súper explotación”, no los capitalistas del Norte. Estos últimos obtienen una parte a través del comercio de cualquier plusvalía extra de las mayores tasas de explotación en el Sur.
De hecho, mostramos en nuestro artículo, las contribuciones relativas a la transferencia de plusvalía de tecnología superior (mayor composición orgánica del capital) y de explotación (tasa de plusvalía) en nuestras medidas. La contribución de la tecnología superior sigue siendo la principal fuente de intercambio desigual, pero la participación de diferentes tasas de plusvalía se ha elevado a casi la mitad.
Andy Higginbottom en su presentación también rechazó la teoría marxista clásica del imperialismo del intercambio desigual presentada en el artículo Carchedi-Roberts, pero por diferentes motivos. Consideró que la igualación de las tasas de ganancia a través de las transferencias de plusvalías individuales a precios de producción se realizó de manera inadecuada en nuestro método (que seguía a Marx). Por lo tanto, nuestro método podría no ser correcto o incluso útil para empezar.
En resumen, nuestra evidencia muestra que el imperialismo es una característica inherente del capitalismo moderno. El sistema internacional del capitalismo refleja su sistema nacional (un sistema de explotación): explotación de las economías menos desarrolladas por las más desarrolladas. Los países imperialistas del siglo XX no han cambiado. No hay nuevas economías imperialistas. China no es imperialista en nuestras medidas. La transferencia de plusvalía por parte de la UE en el comercio internacional se debe principalmente a la superioridad tecnológica de las empresas del núcleo imperialista pero también a una mayor tasa de explotación en el “sur global”. La transferencia de plusvalía del bloque dominado al núcleo imperialista está aumentando en términos de dólares y como porcentaje del PIB.
En nuestra presentación, revisamos otros métodos para medir el “intercambio desigual” en lugar de nuestro método de “precios de producción”, y hay bastantes. En la conferencia, hubo otra sesión en la que Andrea Ricci actualizó (ver sección III) su invaluable trabajo sobre la medición de la transferencia de plusvalía entre la periferia y el bloque imperialista utilizando tablas mundiales de insumo-producto para los sectores comerciales y medidas en dólares PPA. Roberto Veneziani y sus colegas también presentaron un modelo de equilibrio general convencional para desarrollar un “índice de explotación” que muestra la transferencia neta de valor en el comercio de los países. Ambos estudios apoyaron los resultados de nuestro método más “temporal”.
En el estudio de Ricci hay una transferencia neta anual del 4% de la plusvalía en el PIB per cápita a América del Norte; casi el 15% per cápita para Europa occidental y cerca del 6% para Japón y Asia oriental. Por otro lado, existe una pérdida neta de PIB anual per cápita para Rusia del 17%; China 10%, América Latina 5-10% y 23% para India.
En el estudio de Veneziani et al, “todos los países de la OCDE están en el centro, con un índice de intensidad de explotación muy por debajo de 1 (es decir, menos explotado que explotador); mientras que casi todos los países africanos son explotados, incluidos los veinte más explotados “. El estudio coloca a China en la cúspide entre explotados y explotados.
En todas estas medidas de explotación imperialista, China no encaja a la perfección, al menos económicamente. Y esa es la conclusión a la que también se llegó en otra sesión que lanzó un nuevo libro sobre imperialismo del economista marxista australiano Sam King. El convincente libro de Sam King propone que la tesis de Lenin era correcta en sus fundamentos, a saber, que el capitalismo se había convertido en lo que Lenin llamó “capital financiero monopolista” (si bien su libro no está disponible de forma gratuita, su tesis versa fundamentalmente sobre lo mismo). El mundo se ha polarizado en países ricos y pobres sin perspectivas de que ninguna de las principales sociedades pobres llegue a formar parte de la liga de los ricos. Cien años después, ningún país que fuera pobre en 1916 se ha unido al exclusivo club imperialista (salvo con la excepción de Corea y Taiwán, que se beneficiaron específicamente de las “bendiciones de la guerra fría del imperialismo estadounidense”).
La gran esperanza de la década de 1990, promovida por la economía del desarrollo dominante de que Brasil, Rusia, India, China y Sudáfrica (BRICS) pronto se unirían a la liga de los ricos en el siglo XXI, ha demostrado ser un espejismo. Estos países siguen siendo también rans y todavía están subordinados y explotados por el núcleo imperialista. No hay economías de rango medio, a medio camino, que puedan ser consideradas como “subimperialistas” como sostienen algunos economistas marxistas. King muestra que el imperialismo está vivo y no tan bien para los pueblos del mundo. Y la brecha entre las economías imperialistas y el resto no se está reduciendo, al contrario. Y eso incluye a China, que no se unirá al club imperialista.
Hablando de China, hubo varias sesiones sobre China organizadas por el grupo de trabajo IIPPE China. Las sesiones fueron grabadas y están disponibles para verlas en el canal de YouTube de IIPPE China. La sesión cubrió el sistema estatal de China; sus políticas de inversión extranjera; el papel y la forma de planificación en China y cómo China se enfrentó a la pandemia de COVID.
También hubo una sesión sobre ¿Es capitalista China?, en la que realicé una presentación titulada ¿Cuándo se volvió capitalista China? El título es un poco irónico, porque argumenté que desde la revolución de 1949 que expulsó a los terratenientes compradores y capitalistas (que huyeron a Formosa-Taiwán), China ya no ha sido capitalista. El modo de producción capitalista no domina en la economía china incluso después de las reformas de mercado de Deng en 1978. En mi opinión, China es una “economía de transición” como lo era la Unión Soviética, o lo son ahora Corea del Norte y Cuba.
En mi presentación defino qué es una economía de transición, como la vieron Marx y Engels. China no cumple con todos los criterios: en particular, no hay democracia obrera, no hay igualación o restricciones en los ingresos; y el gran sector capitalista no está disminuyendo constantemente. Pero, por otro lado, los capitalistas no controlan la maquinaria estatal, sino los funcionarios del Partido Comunista; la ley del valor (beneficio) y los mercados no dominan la inversión, sí lo hace el gran sector estatal; y ese sector (y el sector capitalista) tienen la obligación de cumplir con los objetivos de planificación nacional (a expensas de la rentabilidad, si es necesario).
Si China fuera simplemente otra economía capitalista, ¿cómo explicamos su fenomenal éxito en el crecimiento económico, sacando a 850 millones de chinos de la línea de pobreza ?; y evitar las recesiones económicas que las principales economías capitalistas han sufrido de forma regular? Si ha logrado esto con una población de 1.400 millones y, sin embargo, es capitalista, entonces sugiere que puede haber una nueva etapa en la expansión capitalista basada en alguna forma estatal de capitalismo que sea mucho más exitosa que los capitalismos anteriores y ciertamente más que sus pares en India, Brasil, Rusia, Indonesia o Sudáfrica. China sería entonces una refutación de la teoría marxista de la crisis y una justificación del capitalismo. Afortunadamente, podemos atribuir el éxito de China a su sector estatal dominante para la inversión y la planificación, no a la producción capitalista con fines de lucro y al mercado.
Para mí, China se encuentra en una “transición atrapada”. No es capitalista (todavía) pero no avanza hacia el socialismo, donde el modo de producción es a través de la propiedad colectiva de los medios de producción para las necesidades sociales con consumo directo sin mercados, intercambio o dinero. China está atrapada porque todavía está atrasada tecnológicamente y está rodeada de economías imperialistas cada vez más hostiles; pero también está atrapado porque no existen organizaciones democráticas de trabajadores y los burócratas del PC deciden todo, a menudo con resultados desastrosos.
Por supuesto, esta visión de China es minoritaria. Los “expertos en China” occidentales están al unísono de que China es capitalista y una forma desagradable de capitalismo para arrancar, no como los capitalismos “democráticos liberales” del G7. Además, la mayoría de los marxistas están de acuerdo en que China es capitalista e incluso imperialista. En la sesión, Walter Daum argumentó que, incluso si la evidencia económica sugiere que China no es imperialista, políticamente China es imperialista, con sus políticas agresivas hacia los estados vecinos, sus relaciones comerciales y crediticias explotadoras con países pobres y su supresión de minorías étnicas como los uyghars en la provincia de Xinjiang. Otros presentadores, como Dic Lo y Cheng Enfu de China, no estuvieron de acuerdo con Daum, y Cheng caracterizó a China como “socialista con elementos del capitalismo de Estado”, una formulación extraña que suena confusa.
Finalmente, debo mencionar algunas otras presentaciones. Primero, sobre la controvertida cuestión de la financiarización. Los partidarios de la ‘financiarización’ argumentan que el capitalismo ha cambiado en los últimos 50 años de una economía orientada a la producción a una dominada por el sector financiero y son las visiones de este sector inestable las que causan las crisis, no los problemas de rentabilidad en el sector productivo. sectores, como argumentó Marx. Esta teoría ha dominado el pensamiento de los economistas poskeynesianos y marxistas en las últimas décadas. Pero cada vez hay más pruebas de que la teoría no solo es incorrecta teóricamente, sino también empíricamente.
Y en IIPPE, Turan Subasat y Stavros Mavroudeas presentaron aún más evidencia empírica para cuestionar la “financiarización” en su artículo titulado: La hipótesis de la financiarización: una crítica teórica y empírica. Subasat y Mavroudeas encuentran que la afirmación de que la mayoría de las empresas multinacionales más grandes son “financieras” es incorrecta. De hecho, la participación de las finanzas en los EE. UU. Y el Reino Unido no ha aumentado en los últimos 50 años; y durante los últimos 30 años, la participación del sector financiero en el PIB disminuyó en un 51,2% y la participación del sector financiero en los servicios disminuyó en un 65,9% en los países estudiados. Y no hay evidencia de que la expansión del sector financiero sea un predictor significativo del declive de la industria manufacturera, que ha sido causado por otros factores (globalización y cambio técnico).
Y hubo algunos artículos que continuaron confirmando la teoría monetaria de Marx, a saber, que las tasas de interés no están determinadas por una “ tasa de interés natural ” de la oferta y la demanda de ahorros (como argumentan los austriacos) o por la preferencia de liquidez, es decir, el acaparamiento de dinero (como afirman los keynesianos), pero están limitados e impulsados por los movimientos en la rentabilidad del capital y, por lo tanto, la demanda de fondos de inversión. Nikos Stravelakis ofreció un artículo, Una reconciliación de la teoría del interés de Marx y el rompecabezas de la prima de riesgo, que mostraba que las ganancias netas corporativas están relacionadas positivamente con los depósitos bancarios y las ganancias netas a brutas están relacionadas positivamente con la tasa de depósitos de préstamos y que el 60% de las variaciones en las tasas de interés pueden explicarse por cambios en la tasa de ganancia. Y Karl Beitel mostró la estrecha conexión entre el movimiento a largo plazo de la rentabilidad en las principales economías en los últimos 100 años (cayendo) y la tasa de interés de los bonos a largo plazo (cayendo). Esto sugiere que hay un nivel máximo de tasas de interés, como argumentó Marx, determinado por la tasa de ganancia sobre el capital productivo, porque el interés proviene solo de la plusvalía.
Finalmente, algo que no estaba en IIPPE pero que agrega aún más apoyo a la ley de Marx de la tendencia a la caída de la tasa de ganancia. En el libro World in Crisis, coeditado por Carchedi y yo, muchos economistas marxistas presentaron evidencia empírica de la caída de la tasa de ganancia del capital de muchos países diferentes. Ahora podemos agregar otro. En un nuevo artículo, El crecimiento económico y la tasa de ganancia en Colombia 1967-2019, Alberto Carlos Duque de Colombia muestra la misma historia que hemos encontrado en otros lugares. El artículo encuentra que el movimiento en la tasa de ganancia está “en concordancia con las predicciones de la teoría marxista y afecta positivamente la tasa de crecimiento. Y la tasa de crecimiento del PIB se ve afectada por la tasa de ganancia y la tasa de acumulación está en una relación inversa entre estas últimas variables ”.
Por lo tanto, los resultados “son consistentes con los modelos macroeconómicos marxistas revisados en este artículo y brindan apoyo empírico a los mismos. En esos modelos, la tasa de crecimiento es un proceso impulsado por el comportamiento de la tasa de acumulación y la tasa de ganancia. Nuestros análisis econométricos brindan apoyo empírico a la afirmación marxista sobre el papel fundamental de la tasa de ganancia, y sus elementos constitutivos, en la acumulación de capital y, en consecuencia, en el crecimiento económico”.
Abril Díaz, N., Bárcena Ruiz, A., Fernández Reyes, E., Galván Cejudo, A., Jorrín Novo, J., Peinado Peinado, J., . . . Túñez Fiñana, I. (6 de Julio de 2021). Espectrofometría: Espectros de absorción y cuantificación colorimétrica de biomoléculas. Obtenido de Departamento de Bioquímica y Biología Molecular, Universidad de Córdoba: https://www.uco.es/dptos/bioquimica-biol-mol/pdfs/08_ESPECTROFOTOMETRIA.pdf
Atil Husni, I., Nyoman Budiantara, I., & Zain, I. (2018). Partial hypothesis testing of truncated spline model in nonparametric regression. College Park, Maryland: American Institute of Physics Conference Proceedings. Obtenido de https://aip.scitation.org/doi/pdf/10.1063/1.5062798
Bermúdez Cabrera, X., Fleites Ramírez, M., & Contreras Moya, A. M. (Septiembre-diciembre de 2009). ESTUDIO DEL PROCESO DE COAGULACIÓN-FLOCULACIÓN DE AGUAS RESIDUALES DE LA EMPRESA TEXTIL “DESEMBARCO DEL GRANMA” A ESCALA DE LABORATORIO. Revista de Tecnología Química, XXIX(3), 64-73. Obtenido de https://www.redalyc.org/pdf/4455/445543760009.pdf
Cepeda, Z., & Cepeda C., E. (2005). Application of Generalized Linear Models to Data Analysis in Drinking Water Treatment. Revista Colombiana de Estad ́ıstica, XXVIII(2), 233-242.
Domènech, X., & Peral, J. (2006). Química Ambiental de sistemas terrestres. (S. REVERTÉ, Ed.) Barcelona.
Li, M., Duan, N., Zhang, D., Li, C.-H., & Ming, Z. (2009). Collaborative Decoding: Partial Hypothesis Re-ranking Using Translation Consensus between Decoders. Suntec, Singapore: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. Obtenido de https://aclanthology.org/P09-1066.pdf
Aldrich, J. H., & Nelson, F. D. (1984). Linear Probability, Logit, and Probit Models. Beverly Hills: Sage University Papers Series. Quantitative Applications in the Social Sciences.
Allen, M. (2017). The SAGE Encyclopedia of COMMUNICATION RESEARCH METHODS. London: SAGE Publications, Inc.
AMERICAN PSYCHOLOGICAL ASSOCIATION. (2021, Julio 15). level. Retrieved from APA Dictionary of Pyschology: https://dictionary.apa.org/level
AMERICAN PYSCHOLOGICAL ASSOCIATION. (2021, Julio 15). factor. Retrieved from APA Dictionary of Pyschology: https://dictionary.apa.org/factor
Birnbaum, Z. W., & Sirken, M. G. (1950, Marzo). Bias Due to Non-Availability in Sampling Surveys. Journal of the American Statistical Association, 45(249), 98-111.
Hastie, T., Tibshirani, R., & Friedman, J. (2017). The Elements of Statistical Learning. Data Mining, Inference, and Prediction (Segunda ed.). New York: Springer.
Instituto Nacional de Estadística y Censos de la República Argentina. (2019). Encuesta de Actividades de Niños, Niñas y Adolescentes 2016-2017. Factores de expansión, estimación y cálculo de los errores por muestra para el dominio rural. Buenos Aires: Ministerio de Hacienda. Retrieved from https://www.indec.gob.ar/ftp/cuadros/menusuperior/eanna/anexo_bases_eanna_rural.pdf
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning with Applications in R. New York: Springer.
Kolmogórov, A. N., & Fomin, S. V. (1978). Elementos de la Teoría de Funciones y del Análisis Funcional (Tercera ed.). (q. e.-m. Traducido del ruso por Carlos Vega, Trans.) Moscú: MIR.
Liao, T. F. (1994). INTERPRETING PROBABILITY MODELS. Logit, Probit, and Other Generalized Linear Models. Iowa: Sage University Papers Series. Quantitative Applications in the Social Sciences.
Lipschutz, S. (1992). Álgebra Lineal. Madrid: McGraw-Hill.
Lohr, S. L. (2019). Sampling: Design and Analysis (Segunda ed.). Boca Raton: CRC Press.
Lohr, S. L. (2019). Sampling: Design and Analysis (Segunda ed.). Boca Raton: CRC Press.
McCullagah, P., & Nelder, J. A. (1989). Generalized Linear Models (Segunda ed.). London: Chapman and Hall.
McCullagh, P., & Nelder, J. A. (1989). Generalized Linear Models (Segunda ed.). London: Chapman and Hall.
Nelder, J. A., & Wedderburn, R. W. (1972). Generalized Linear Models. Journal of the Royal Statistical Society, 135(3), 370-384.
Ritchey, F. (2002). ESTADÍSTICA PARA LAS CIENCIAS SOCIALES. El potencial de la imaginación estadística. México, D.F.: McGRAW-HILL/INTERAMERICANA EDITORES, S.A. DE C.V.








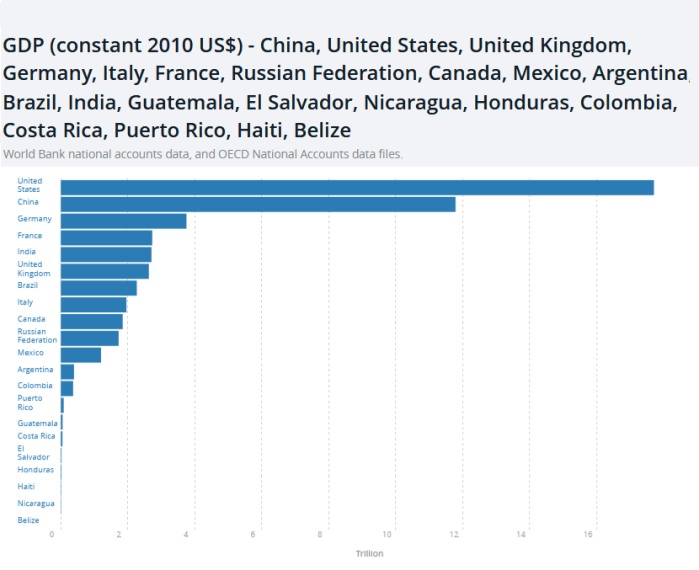

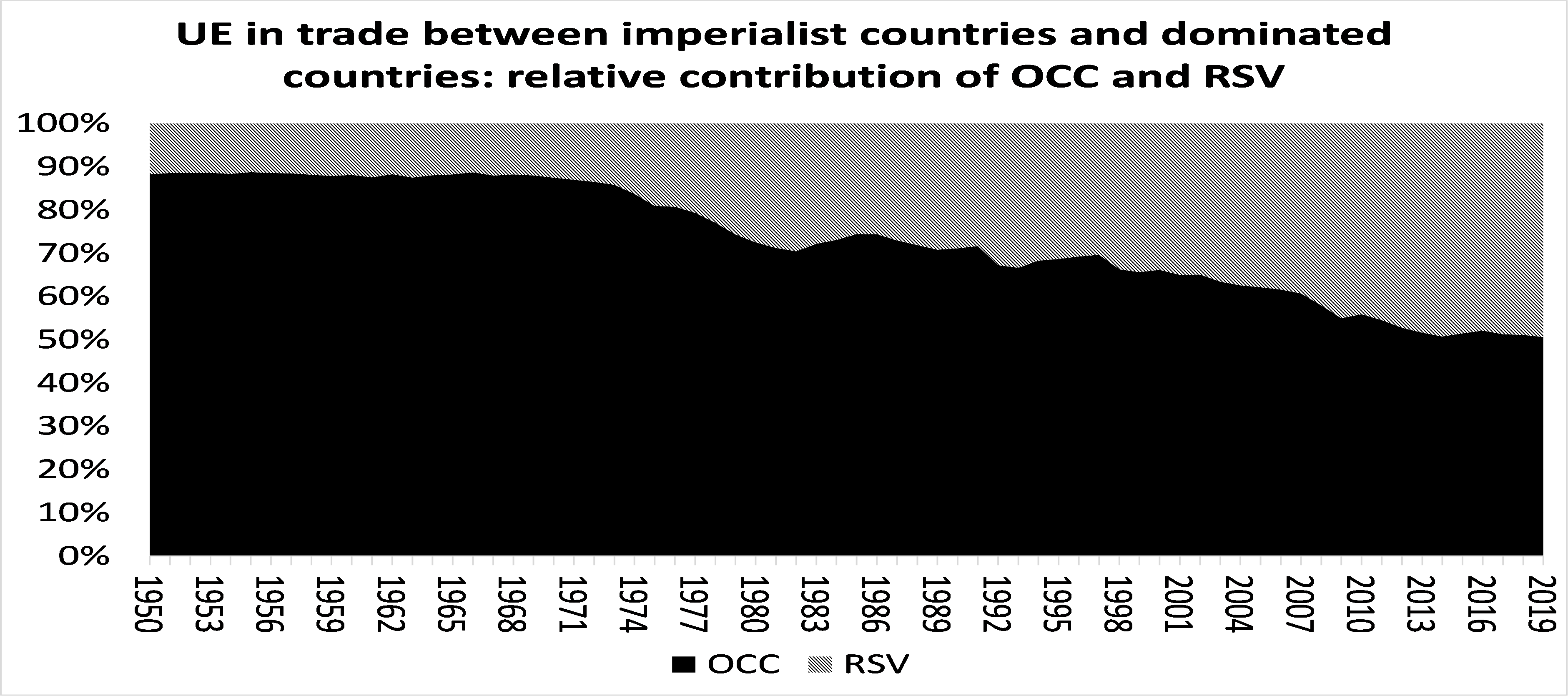




















{kind=link}