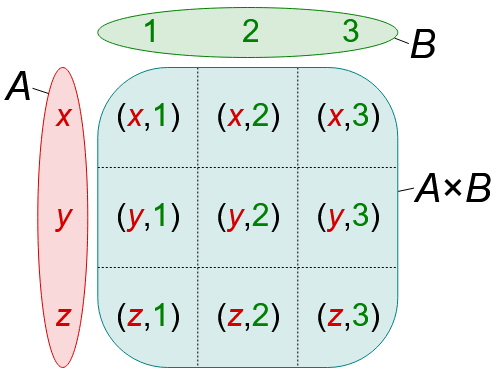
Los ítems del siguiente cuestionario han sido elaborados con base en los tramos de ingreso presentados a continuación, los cuales fueron construidos alrededor de la línea de pobreza definida gnoseológica y metodológicamente en (Nabi, 2021).
Es necesario aclarar que este cuestionario no tiene como finalidad la medición de la pobreza en su dimensión humana, la dimensión más profunda y general que requiere del uso de otro tipo de indicadores, como por ejemplo lo son los Índices de Desarrollo Humano (IDH) de las Naciones Unidas o el Índice de Pobreza Multidimensional del INEC. Este cuestionario busca capturar la información relativa a la afectación que la crisis económica, que se terminó de configurar a causa de la crisis sanitaria COVID-19, ha tenido en la sociedad según nivel de ingreso y según su clase social. En (Nabi, 2021) se determinó un punto pivote alrededor del cual se debe definir el nivel de goce de la riqueza social que posee un miembro de la sociedad, al cual los economistas denominan como línea de pobreza. Por supuesto, esta determinación utilizó las estadísticas oficiales del INEC y una metodología estándar en las Naciones Unidas y diversos países europeos como Alemania.
Además, debe destacarse que las preguntas han sido diseñadas de esta forma para que sea posible captar la estructura del ingreso de los encuestados, determinada dicha estructura por la relación que los encuestados con producción social en general: si viven de su fuerza de trabajo pertenecen a la clase trabajadora y ha diseñado el cuestionario de tal manera que clasifique a esta clase social como aquellos encuestados que viven mayoritariamente de un salario o del comercio informal (no se considera al comerciante informal como un “empresario”, en el sentido tradicional de la palabra, a causa del bajo nivel de división social del trabajo de esas unidades productivas y del bajo nivel de acumulación de capital que suele presentarse en dichas unidades), mientras que como la clase capitalista a quienes no viven mayoritariamente de su fuerza de trabajo; se dice “mayoritariamente” porque en no aisladas ocasiones las fuentes de ingreso de una persona o un hogar pueden ser mixtas. Así, se busca medir el flujo mensual de ingreso y determinar si viven de su fuerza de trabajo o no, en conjunto con la afectación que el actual escenario social ha tenido en dicho flujo.
Valor Central (Línea de Pobreza UNECE)
₡571 096,20
Número de Clases
6
Ancho de Clase
₡190 365,40
Número de Clase
Límite Inferior
Límite Superior
1
₡0,00
₡190 365,40
2
₡190 365,40
₡380 730,80
3
₡380 730,80
₡571 096,20
4
₡571 096,20
₡761 461,60
5
₡761 461,60
₡951 827,00
6
₡951 827,00
₡951,827 o más
1. En caso sus ingresos mensuales provengan mayoritariamente de un salario y/o del comercio informal, marque con una “X” la casilla correspondiente al tramo al que corresponde su nivel de ingreso mensual previo a la pandemia.
₡0
₡190 365
₡190 365
₡380 731
₡380 731
₡571 096
₡571 096
₡761 462
₡761 462
₡951 827
₡951 827
₡951,827 o más
2. En caso sus ingresos mensuales provengan mayoritariamente de un salario y/o del comercio informal, marque con una “X” la casilla correspondiente al tramo al que corresponde su nivel de ingreso mensual actual.
₡0
₡190 365
₡190 365
₡380 731
₡380 731
₡571 096
₡571 096
₡761 462
₡761 462
₡951 827
₡951 827
₡951,827 o más
3. En caso sus ingresos mensuales no provengan mayoritariamente de un salario y/o del comercio informal, marque con una “X” la casilla correspondiente al tramo al que corresponde su nivel de ingreso mensual previo a la pandemia.
₡0
₡190 365
₡190 365
₡380 731
₡380 731
₡571 096
₡571 096
₡761 462
₡761 462
₡951 827
₡951 827
₡951,827 o más
4. En caso sus ingresos mensuales no provengan mayoritariamente de un salario y/o del comercio informal, marque con una “X” la casilla correspondiente al tramo al que corresponde su nivel de ingreso mensual actual.
₡0
₡190 365
₡190 365
₡380 731
₡380 731
₡571 096
₡571 096
₡761 462
₡761 462
₡951 827
₡951 827
₡951,827 o más
5. En caso alguna persona de su núcleo familiar (incluido usted mismo) haya padecido los efectos del COVID-19 y se haya incurrido en alguno de los siguientes gastos para enfrentar la enfermedad, marque con una “X” el tipo de gasto realizado y señale qué porcentaje de su ingreso mensual representó dicho gasto.
TIPO DE GASTO
% DEL INGRESO MENSUAL
Artículos de higiene
Consulta médica
Hospitalización
Medicamentos
6. En caso de haber experimentado algún cambio en su situación laboral a causa del COVID-19, marque con una “X” cuáles fueron estos cambios (puede marcar más de una opción o ninguna).
Arias Ramírez, R. (2020). Pobreza y desigualdad en Costa Rica: una mirada más allá de la distribución de los ingresos. Estudios del Desarrollo Social: Cuba y América Latina, 1-26. Obtenido de http://scielo.sld.cu/pdf/reds/v8n1/2308-0132-reds-8-01-16.pdf
Barría, C. (16 de Mayo de 2019). Cómo Costa Rica se convirtió en uno de los países más innovadores de América Latina (y cuáles son algunos de los inventos más sorprendentes). Obtenido de BBC Mundo: https://www.bbc.com/mundo/noticias-48193736
Baumol, W. (1983). Marx and the Iron Law of Wages. The American Economic Review, 303-308.
Cochran, W. G. (1991). Técnicas de Muestreo. México, D.F.: Compañía Editorial Continental.
Delgado Jiménez, F. (2013). EL EMPLEO INFORMAL EN COSTA RICA: CARACTERÍSTICAS DE LOS OCUPADOS Y SUS PUESTOS DE TRABAJO. Ciencias Económicas, XXXI(2), 35-51.
Hidalgo Víquez, C., Andrade Pérez, L., Rodríguez Gonzáles, S., Dumani Echandi, M., Alvarado Molina, N., Cerdas Nuñez, M., & Quirós Blanco, G. (2020). Análisis de la canasta básica alimentaria de Costa Rica: oportunidades desde la alimentación y nutrición. Población y Salud en Mesoamérica, 1-24. Obtenido de https://revistas.ucr.ac.cr/index.php/psm/article/view/40822/42616
Laplante, P. A. (2001). DICTIONARY OF COMPUTER SCIENCE, ENGENEERING AND TECHNOLOGY. Boca Ratón, Florida, Estados Unidos: CRC Press.
Levins, R. (Diciembre de 1993). A Response to Orzack and Sober: Formal Analysis and the Fluidity of Science. The Quarterly Review of Biology, 68(4), 547-55.
Vargas Solís, L. P. (2016). El Proyecto Histórico Neoliberal en Costa Rica (1984-2015): Devenir histórico y crisis. Revista Rupturas, 147-162. doi:https://doi.org/10.22458/rr.v1i1.1167
Andrews, D. W. (1991). An Empirical Process Central Limit Theorem for Dependent Non-identically Distributed Random Variables . Journal of Multivariate Analysis, 187-203.
Berk, K. (1973). A CENTRAL LIMIT THEOREM FOR m-DEPENDENT RANDOM VARIABLES WITH UNBOUNDED m. The Annals of Probability, 1(2), 352-354.
Borisov, E. F., & Zhamin, V. A. (2009). Diccionario de Economía Política. (L. H. Juárez, Ed.) Nueva Guatemala de la Asunción, Guatemala, Guatemala: Tratados y Manuales Grijalbo.
Cockshott, P., & Cottrell, A. (2005). Robust correlations between prices and labor values. Cambridge Journal of Economics, 309-316.
Cockshott, P., Cottrell, A., & Valle Baeza, A. (2014). The Empirics of the Labour Theory of Value: Reply to Nitzan and Bichler. Investigación Económica, 115-134.
Dedecker, J., & Prieur, C. (2007). An empirical central limit theorem for dependent sequences. Stochastic Processes and their Applications, 117, 121-142.
Díaz, E., & Osuna, R. (2007). Indeterminacy in price–value correlation measures. Empirical Economics, 389-399.
Emmanuel, A. (1972). El Intercambio Desigual. Ensayo sobre los antagonismos en las relaciones económicas internacionales. México, D.F.: Sigloveintiuno editores, s.a.
Farjoun, E., & Marchover, M. (1983). Laws of Chaos. A Probabilistic Approach to Political Economy. Londres: Verso Editions and NLB.
Flaschel, P., & Semmler, W. (1985). The Dynamic Equalization of Profit Rates for Input-Output Models with Fixed Capital. En Varios, & W. Semmler (Ed.), Competition, Instability, and Nonlinear Cycles (págs. 1-34). New York: Springer-Verlag.
Fröhlich, N. (2012). Labour values, prices of production and the missing equalisation tendency of profit rates: evidence from the German economy. Cambridge Journal of Economics, 37(5), 1107-1126.
Glick, M., & Ehrbar, H. (1988). Profit Rate Equalization in the U.S. and Europe: An Econometric Investigation. European Journal of Political Economy, 179-201.
Gloria-Palermo, S. (2010). Introducing Formalism in Economics: The Growth Model of John von Neumann. Panoeconomicus, 153-172.
Godwin, H., & Zaremba, S. (1961). A Central Limit Theorem for Partly Dependent Variables. The Annals of Mathematical Statistics, 32(3), 677-686.
Guerrero, D. (Octubre-diciembre de 1997). UN MARX IMPOSIBLE: EL MARXISMO SIN TEORÍA LABORAL DEL VALOR. 57(222), 105-143.
Kliman, A. (2002). The law of value and laws of statistics: sectoral values and prices in the US economy, 1977-97. Cambridge Journal of Economics, 299-311.
Kliman, A. (2005). Reply to Cockshott and Cottrell. Cambridge Journal of Economics, 317-323.
Kliman, A. (2014). What is spurious correlation? A reply to Díaz and Osuna. Journal of Post Keynesian Economics, 21(2), 345-356.
KO, M.-H., RYU, D.-H., KIM, T.-S., & CHOI, Y.-K. (2007). A CENTRAL LIMIT THEOREM FOR GENERAL WEIGHTED SUMS OF LNQD RANDOM VARIABLES AND ITS APPLICATION. ROCKY MOUNTAIN JOURNAL OF MATHEMATICS, 37(1), 259-268.
Kuhn, T. (2011). La Estructura de las Revoluciones Científicas. México, D.F.: Fondo de Cultura Económica.
Kuroki, R. (1985). The Equalizartion of the Rate of Profit Reconsidered. En W. Semmler, Competition, Instability, and Nonlinear Cycles (págs. 35-50). New York: Springer-Velag.
Landau, L. D., & Lifshitz, E. M. (1994). Curso de Física Teórica. Mecánica (Segunda edición corregida ed.). (E. L. Vázquez, Trad.) Barcelona: Reverté, S.A.
Leontief, W. (1986). Input-Output Economics. Oxford, United States: Oxford University Press.
Levins, R. (Diciembre de 1993). A Response to Orzack and Sober: Formal Analysis and the Fluidity of Science. The Quarterly Review of Biology, 68(4), 547-55.
LI, X.-p. (2015). A Central Limit Theorem for m-dependent Random Variables under Sublinear Expectations. Acta Mathematicae Applicatae Sinica, 31(2), 435-444. doi:10.1007/s10255-015-0477-1
Parzen, E. (1957). A Central Limit Theorem for Multilinear Stochastic Processes. The Annals of Mathematical Statistics, 28(1), 252-256.
Pasinetti, L. (1984). Lecciones Sobre Teoría de la Producción. (L. Tormo, Trad.) México, D.F.: Fondo de Cultura Económica.
Real Academia Española. (18 de 03 de 2021). Diccionario de la lengua española. Obtenido de Edición del Tricentenario | Actualización 2020: https://dle.rae.es/transitar?m=form
Real Academia Española. (23 de Marzo de 2021). Diccionario de la lengua española. Obtenido de Edición Tricentenario | Actualización 2020: https://dle.rae.es/ecualizar?m=form
Rosental, M. M., & Iudin, P. F. (1971). DICCIONARIO FILOSÓFICO. San Salvador: Tecolut.
Rosental, M., & Iudin, P. (1971). Diccionario Filosófico. San Salvador: Tecolut.
Sánchez, C., & Ferràndez, M. N. (Octubre-diciembre de 2010). Valores, precios de producción y precios de mercado a partir de los datos de la economía española. Investigación Económica, 87-118. Obtenido de https://www.jstor.org/stable/42779601?seq=1
Sánchez, C., & Montibeler, E. E. (2015). La teoría del valor trabajo y los precios en China. Economia e Sociedade, 329-354.
Steedman, I., & Tomkins, J. (1998). On measuring the deviation of prices from values. Cambridge Journal of Economics, 379-385.
U.S. Bureau of Economic Analysis. (1 de Abril de 2021). The Domestic Supply of Commodities by Industries (Millions of dollars). Obtenido de Input-Output Accounts Data | Data Files. Supply Tables – Domestic supply of commodities by industry ● 1997-2019: 15 Industries iTable, 71 Industries iTable: https://apps.bea.gov/iTable/iTable.cfm?reqid=52&step=102&isuri=1&table_list=3&aggregation=sum
U.S. Bureau of Economic Analysis. (1 de Abril de 2021). The Domestic Supply of Commodities by Industries (Millions of dollars). Obtenido de Input-Output Accounts Data | Supplemental Estimate Tables. After Redefinition Tables. Make Tables/After Redefinitions – Production of commodities by industry after redefinition of secondary production ● 1997-2019: 71 Industries iTable: https://apps.bea.gov/iTable/iTable.cfm?reqid=58&step=102&isuri=1&table_list=5&aggregation=sum
U.S. Bureau of Economic Analysis. (1 de Abril de 2021). The Use of Commodities by Industries. Obtenido de Input-Output Accounts Data | Supplemental Estimate Tables. After Redefinition Tables. Use Tables/After Redefinitions/Producer Value – Use of commodities by industry after reallocation of inputs ● 1997-2019: 71 Industries iTable: https://apps.bea.gov/iTable/iTable.cfm?reqid=58&step=102&isuri=1&table_list=6&aggregation=sum
Valle Baeza, A. (1978). Valor y Precios de Producción. Investigación Económica, 169-203.
Walras, L. (1954). Elements of Pure Economics or The Theory of Social Wealth. (W. Jaffé, Trad.) Homewood, Ilinois, Estados Unidos: Richard D. Irwin, Inc.
Einstein, A. (2005). The Foundation of the General Theory of Relativity. En A. Einstein, 100 Years of Gravity and Accelerated Frames. The Deepest lnsig hts of Einstein and Yang-Mills (págs. 65-119). Singapore: World Scientific Publishing Co. Pte. Ltd.
Frolov, I. T. (1984). Diccionario de filosofía. (O. Razinkov, Trad.) Moscú: Editorial Progreso. Obtenido de http://filosofia.org/
Gass, I., Smith, P., & Wilson, R. (2008). Introducción a las Ciencias de la Tierra. Barcelona: Reverté, S.A.
Kilifarska, N. A., Bakhmutov, V. G., & Melnyk, G. V. (2020). The Hidden Link between Earth’s Magnetic Field and Climate. Radarweg, Amsterdam, Netherlands: Elsevier.
Bayes, T. (23 de Diciembre de 1763). An Essay towards solving a Problem in the Doctrine of Chances. Philosophical Transactions of the Royal Society of London, 370-418.
Bernoulli, J. (2006). The Art of Conjecturing (Together to a Friend on Sets in Court Tennis). Maryland: John Hopkins University Press.
DeGroot, M., & Schervish, M. (2012). Probability and Statistics. Boston: Pearson Education.
Dussel, E. (1991). 2. El método dialéctico de lo abstracto a lo concreto (20, 41-33, 14; 21,3-31,38) :(Cuaderno M. desde la página 14 del manuscrito, terminado a mediados deseptiembre de 1857). En E. Dussel, La producción teórica de Marx: un comentario a los grundrisse (págs. 48-63). México D.F.: Siglo XXI Editores. Obtenido de http://biblioteca.clacso.edu.ar/clacso/otros/20120424094653/3cap2.pdf
Efron, B. (1978). Controversies in the Foundations of Statistics. The American Mathematical Monthly, 231-246.
Fröhlich, N. (2012). Labour values, prices of production and the missing equalisation tendency of profit rates: evidence from the German economy. Cambridge Journal of Economics, 37(5), 1107-1126.
Frolov, I. T. (1984). Diccionario de filosofía. (O. Razinkov, Trad.) Moscú: Editorial Progreso. Obtenido de http://filosofia.org/
Maibaum, G. (1988). Teoría de Probabilidades y Estadística Matemática. (M. Á. Pérez, Trad.) La Habana, Cuba: Editorial Pueblo y Educación.
Marx, K. (1894). Capital. A Critique of Political Economy (Vol. III). New York: International Publishers.
Marx, K. (1989). Contribución a la Crítica de la Economía Política. Moscú: Editorial Progreso.
Marx, K. (2007). Elementos Fundamentales para la Crítica de la Economía Política (Grundrisse) 1857-1858 (Vol. I). (J. Aricó, M. Murmis, P. Scaron, Edits., & P. Scaron, Trad.) México, D.F.: Siglo XXI Editores.
Marx, K. (2010). El Capital (Vol. I). México, D.F.: Fondo de Cultura Económica.
Marx, K., & Engels, F. (1987). Karl Marx and Friedrich Engels Collected Works (Vol. XLII). Moscú: Progress Publishers.
Mittelhammer, R. (2013). Mathematical Statistics for Economics and Business (Segunda ed.). New York: Springer.
Perezgonzalez, J. (3 de Marzo de 2015). Fisher, Neyman-Pearson or NHST? A tutorial for teaching data testing. (L. Roberts, Ed.) Frontiers in Psychology, 6(223), 1-11. doi:10.3389/fpsyg.2015.00223
Poisson, S.-D. (2013). Researches into the Probabilities of Judgments in Criminal and Civil Cases. (O. Sheynin, Ed.) Berlin: arXiv. Obtenido de https://arxiv.org/abs/1902.02782
Fórmula general para permutar un conjunto repitiendo sus elementosEjemplo de permutaciones con repetición para el caso de un conjunto de cuatro elementos
CÓDIGO EN R
library(gtools)
permutations(10, 10, conjunto, set = FALSE)
IV. COMBINACIONES SIN REPETICIÓN
Fórmula general para calcular combinaciones sin repetición
Desde Pierre-Simon Laplace en 1840 con su célebre “Ensayo Filosófico Sobre Probabilidades”, los filósofos y científicos se han interesado por dicotomía, sugerida por la observación de los hechos de la realidad, entre la incertidumbre y el determinismo. Henri Poincaré en 1908 coge el testigo de Laplace, comenzando así el esfuerzo consciente por unificarlas filosóficamente y dando así nacimiento a la Teoría del Caos, para que luego Edward Lorenz en 1963 diera a luz los Sistemas Complejos en su investigación titulada “Deterministic Nonperiodic Flow” y finalmente fue Benoit Mandelbrot en 1982 quien revolucionó la Geometría con el planteamiento de las superficies fractales en su obra “La Geometría Fractal de la Naturaleza”. Así como para los sistemas complejos ha sido de vital importancia ir comprendiendo unificadamente el caos y el determinismo, también fue para los sistemas filosóficos (particularmente la Antigua Grecia y del Idealismo Clásico Alemán) alcanzar precisión en las definiciones de las categorías esencia, forma, contenido, apariencia y fenómeno. Estas categorías filosóficas fueron trabajadas por los filósofos soviéticos en su búsqueda por comprender de manera holista la realidad, siendo plasmadas en el célebre “Diccionario Filosófico” publicado en 1971. La presente investigación plantea que la forma óptima de instrumentalizar esa visión filosófica es nutriéndola de los hallazgos realizados en el campo de la Teoría del Caos y también que la forma óptima de depurar teóricamente lo relacionado a los sistemas complejos es mediante su análisis a la luz de la Lógica Dialéctica-Materialista.
Palabras Clave: Materialismo Dialéctico, Sistemas Complejos, Fractales, Teoría del Caos, Escuela de Filosofía Soviética.
REREFENCIAS
Aravindh, M., Venkatesan, A., & Lakshmanan, M. (2018). Strange nonchaotic attractors for computation. Physical Review E, 97(5), 1-10. doi:https://doi.org/10.1103/PhysRevE.97.052212
Barnet, W., & Chen, P. (1988). Deterministic Chaos and Fractal Atrractors as Tools for NonParametric Dynamical Econometric Inference: With An Application to the Divisa Monetary Aggregates. Computational Mathematics and Modeling, 275-296. Obtenido de http://www.maths.usyd.edu.au/u/gottwald/preprints/testforchaos_MPI.pdf
Elert, G. (11 de Agosto de 2020). Flow Regimes – The Physics Hypertextbook. Recuperado el 11 de Agosto de 2020, de https://physics.info/turbulence/
Gottwald, G., & Melbourne, I. (2016). The 0-1 Test for Chaos: A review. En U. Parlitz, E. G. Lega, R. Barrio, P. Cincotta, C. Giordano, C. Skokos, . . . J. Laskar, & C. G. Sokos (Ed.), Chaos Detection and Predictability (págs. 221-248). Berlin: Springer.
Halperin, B. (2019). Theory of dynamic critical phenomena. Physics Today, 72(2), 42-43. doi:10.1063/PT.3.4137
Jaynes, E. (2003). Probability Theory. The Logic of Science. Cambridge University Press: New York.
Kessler, D., & Greenkorn, R. (1999). Momentum, Heat, and Mass Transfer Fundamentals. New York: Marcel Denker, Inc.
Kilifarska, N., Bakmutov, V., & Melnyk, G. (2020). The Hidden Link Between Earth’s Magnetic Field and Climate. Leiden: Elsevier.
Landau, L. (1994). Física Teórica. Física Estadística (Segunda ed., Vol. 5). (S. Velayos, Ed., & E. L. Vázquez, Trad.) Barcelona: Reverté, S.A.
Lesne, A. (1998). Renormalization Methods. Critical Phenomena, Chaos, Fractal Structures. Baffins Lane, Chichester, West Sussex, England: John Wiley & Sons Ltd.
Lesne, A., & Laguës, M. (2012). Scale Invariance. From Phase Transitions to Turbulence (Primera edición, traducida del francés (que cuenta con dos ediciones) ed.). New York: Springer.
Linder, J., Kohar, V., Kia, B., Hippke, M., Learned, J., & Ditto, W. (4 de Febrero de 2015). Strange nonchaotic stars. Recuperado el 16 de Abril de 2020, de Nonlinear Sciences > Chaotic Dynamics: https://arxiv.org/pdf/1501.01747.pdf
Lorenz, E. (1963). Deterministic Nonperiodic Flow. JOURNAL OF THE ATMOSPHERIC SCIENCES, 20, 130-141.
Mandelbrot, B. (1983). THE FRACTAL GEOMETRY OF NATURE. New York: W.H. Freeman and Company.
Pezard, L., & Nandrino, J. (2001). Paradigme dynamique en psychopathologie: la “Théorie du chaos”, de la physique à la psychiatrie [Dynamic paradigm in psychopathology: “chaos theory”, from physics to psychiatry]. Encephale, 27(3), 260-268. Obtenido de https://pubmed.ncbi.nlm.nih.gov/11488256/
Sharma, V. (2003). Deterministic Chaos and Fractal Complexity in the Dynamics of Cardiovascular Behavior: Perspectives on a New Frontier. The Open Cardiovascular Medicine Journal(3), 110-123.
Valdebenito, E. (1 de Julio de 2019). Fractales: La Geometría del Caos. Recuperado el 11 de Agosto de 2020, de viXra: https://vixra.org/pdf/1901.0152v1.pdf
Werndl, C. (2013). What Are the New Implications of Chaos for Unpredictability? The British Journal for the Philosophy of Science, 60(1), 1-25. doi:10.1093/bjps/axn053
Bellman, R. (1972). Dynamic Programming (Sexta Impresión ed.). New Jersey: Princeton University Press.
Dunn, K. G. (3 de Marzo de 2021). Process Improvement Using Data. Hamilton, Ontario, Canadá: Learning Chemical Engineering. Obtenido de 6.5. Principal Component Analysis (PCA) | 6. Latent Variable Modelling: https://learnche.org/pid/PID.pdf?60da13
Jollife, I. (2002). Principal Component Analysis. New York: Springer-Verlag.
Siguiendo a (Lakshmanan, 2019), es necesario definir las diferencias entre re-escalamiento, normalización y estandarización. Re-escalar un vector significa realizar alguna combinación lineal sobre él, es decir, “(…) sumar o restar una constante y luego multiplicar o dividir por una constante, como lo haría para cambiar las unidades de medida de los datos, por ejemplo, para convertir una temperatura de Celsius a Fahrenheit.” A su vez, normalizar un vector “(…) la mayoría de las veces significa dividir por una norma del vector. También se refiere a menudo al cambio de escala por el mínimo y el rango del vector, para hacer que todos los elementos se encuentren entre 0 y 1, lo que lleva todos los valores de las columnas numéricas del conjunto de datos a una escala común.”, mientras que estandarizar un vector significa “(…) la mayoría de las veces significa restar una medida de ubicación y dividir por una medida de escala. Por ejemplo, si el vector contiene valores aleatorios con una distribución gaussiana, puede restar la media y dividir por la desviación estándar, obteniendo así una variable aleatoria “normal estándar” con media 0 y desviación estándar 1.”
II. Razones generales de uso
En general, las razones para realizar alguno de los tres ajustes anteriores en la etapa de preprocesamiento de los datos son diferentes para cada uno. Así, las razones por las que se debe estandarizar tienen que ver con que la estandarización “(…) de las características alrededor del centro y 0 con una desviación estándar de 1 es importante cuando comparamos medidas que tienen diferentes unidades. Las variables que se miden a diferentes escalas no contribuyen por igual al análisis y podrían terminar creando un sesgo”. En la misma dirección, “(…) el objetivo de la normalización es cambiar los valores de las columnas numéricas en el conjunto de datos a una escala común, sin distorsionar las diferencias en los rangos de valores. Para el aprendizaje automático, no todos los conjuntos de datos requieren normalización. Solo se requiere cuando las características tienen diferentes rangos.”
III. Contextos de aplicación
La normalización es una buena técnica para usar cuando la distribución de sus datos o cuando sabe que la distribución no es gaussiana. La normalización es útil cuando sus datos tienen escalas variables y el algoritmo que se está utilizando no hace suposiciones sobre la distribución de las observaciones o puntos de datos, como k vecinos más cercanos y redes neuronales artificiales.
La estandarización asume que sus datos tienen una distribución gaussiana (curva de campana). Esto no tiene que ser estrictamente cierto, pero la técnica es más efectiva si su distribución de atributos es gaussiana. La estandarización es útil cuando sus datos tienen escalas variables y el algoritmo que está utilizando hace suposiciones acerca de que sus datos tienen una distribución gaussiana, como regresión lineal, regresión logística, entre otras.
Como se señala en el lugar citado, la normalización es recomendable cuando no conoce la distribución de las observaciones o cuando sabe que la distribución no es gaussiana. La normalización es útil cuando las observaciones tienen escalas variables y el algoritmo empleado no hace suposiciones sobre la distribución de las observaciones, como lo son K-vecinos más cercanos y las redes neuronales artificiales. Por otro lado, la estandarización asume que las observaciones tienen una distribución gaussiana. Esto no tiene que ser estrictamente cierto, pero la técnica es más efectiva si las observaciones siguen tal distribución. La estandarización es útil cuando los datos tienen escalas variables y el algoritmo que se está utilizando hace suposiciones acerca de que los datos tienen una distribución gaussiana, como es el caso de la regresión lineal, la regresión logística y el análisis discriminante lineal.
IV. Algunas razones teóricas por las que el re-escalamiento, la normalización y la estandarización pueden robustecer a los algoritmos numéricos y a la calidad de los datos
En el contexto del aprendizaje automático a la estandarización se le conoce como re-escalamiento de características[i](por su nombre en inglés, “feature scalling”) y consiste, siguiendo a (Saini, 2019), en poner los valores en el mismo rango o escala para que ninguna variable esté dominada por la otra y, con ello, se pueda estudiar su relación en términos de la menor heterogeneidad posible. La razón por la que la normalización contribuye a mejorar la robustez del algoritmo K-vecinos más cercanos es porque este algoritmo emplea la función distancia euclidiana, la cual es significativamente sensible a las magnitudes de las características, por lo que se deben normalizar (en el sentido antes definido) de tal forma que “todas pesen igual”. En el caso de la utilización del análisis de componentes principales (PCA) es de importancia fundamental el re-escalar las variables de estudio, porque ya que el PCA busca capturar (en las variables resultantes tras la reducción de dimensionalidad) la mayor variabilidad posible y siendo esto así, las características de mayor magnitud tendrán mayor variabilidad, por lo que estas características tendrán más peso (lo cual no necesariamente cierto en la totalidad de las ocasiones) y ello puede conducir al investigador a conclusiones falsas o a verdades a medias.
Por otro lado, considerando no el PCA globalmente sino únicamente la metodología numérica que lo orquesta, i.e., el método del gradiente descendiente, es posible acelerar el descenso de gradientes mediante el re-escalamiento, lo que implica una disminución considerable del costo computacional. Esta mejora en el desempeño de la metodología referida se debe a que θ descenderá rápidamente en rangos pequeños y lentamente en rangos grandes, por lo que oscilará ineficazmente hasta el óptimo cuando las variables sean muy desiguales, aspecto que corrige el re-escalamiento.
Por otro lado, el re-escalamiento tiene impacto en la calidad de los datos y es un proceso que se realiza en la etapa conocida como preprocesamiento.
Como se señala en (PowerData, 2016), “El preprocesamiento de datos es un paso preliminar durante el proceso de minería de datos. Se trata de cualquier tipo de procesamiento que se realiza con los datos brutos para transformarlos en datos que tengan formatos que sean más fáciles de utilizar (…) En el mundo real, los datos frecuentemente no están limpios, faltan valores clave, contienen inconsistencias y suelen mostrar ruido, conteniendo errores y valores atípicos. Sin un preprocesamiento de datos, estos errores en los datos sobrevivirían y disminuirían la calidad de la minería de datos (…) La falta de limpieza adecuada en los datos es el problema número uno en data warehousing. Algunos de las tareas de preprocesamiento de datos son las siguientes (…) Rellenar valores faltantes (…) Identificar y eliminar datos que se pueden considerar un ruido (…) Resolver redundancia (…) Corregir inconsistencias (…) Los datos están disponibles en varios formatos, tales como formas estáticas, categóricas, numéricas y dinámicas (…) Algunos ejemplos incluyen metadatos, webdata, texto, vídeo, audio e imágenes. Estas formas de datos tan variadas contribuyen a que el procesamiento de datos continuamente se encuentre con nuevos desafíos (…) Además de manejar datos faltantes, es esencial identificar las causas de la falta de datos para evitar que esos problemas evitables con los datos no vuelvan a ocurrir. Las soluciones para datos faltantes incluyen rellenar manualmente los valores perdidos y rellenar automáticamente con la palabra “desconocido” (…) La duplicación de datos puede ser un problema importante en minería de datos, ya que a menudo hace que se pierdan negocios, se pierda el tiempo y sea difícil de tratar. Un ejemplo común de un problema de duplicación de datos típico incluye varias llamadas de ventas al mismo contacto. Las posibles soluciones implican actualizaciones de software o cambiar la forma en que tu negocio controla la gestión de relaciones con clientes. Sin un plan específico y el software adecuado, es difícil eliminar la duplicación de datos (…) Otra fuente común de duplicación de datos es cuando una empresa tiene un número excesivo de bases de datos. Como parte de su preprocesamiento de datos debe revisar periódicamente oportunidades para reducir y eliminar algunas de esas bases de datos. Si no se hace, la duplicación de datos es probable que sea un problema recurrente con el que vas a tener que lidiar una y otra vez (…) Alcanzar la calidad de datos en minería de datos (…) La mayoría de las empresas quieren hacer un mejor uso de sus extensos datos, pero no están seguros acerca de por dónde empezar. La limpieza de datos es un primer paso prudente de un largo camino hacia la mejora de la calidad de los datos. La calidad de los datos puede ser un objetivo difícil de alcanzar sin una metodología eficaz que acelere la limpieza de datos: 1. Reconocer el problema e identificar las causas fundamentales (…) 2. Creación de una estrategia y visión de calidad de datos (…) 3. Priorizar la importancia de los datos (…) 4. Realización de evaluaciones de datos (…) 5. Estimación del ROI para mejorar la calidad de los datos frente al coste de no hacer nada (…) Establecer la responsabilidad de la calidad de los datos.”
Como señala (GeeksforGeeks, 2019), el re-escalamiento es un paso del preprocesamiento de datos que se aplica a variables independientes o características de los datos. Básicamente, ayuda a normalizar los datos dentro de un rango particular. A veces, también ayuda a acelerar los cálculos en un algoritmo, como se mencionó anteriormente.
Finalmente, es necesario acotar que las metodologías de naturaleza numérica-algorítmica conocidas como Naive Bayes, Análisis de Discriminante Lineal, Modelos de Árboles y todo procedimiento estadístico-matemático de la naturaleza antes descrita que no se base metodológicamente en la aplicación (de una u otra forma) de la función distancia del espacio en el que se analicen los datos, que es lo que en Ciencia de Datos se conoce como “algoritmos basados en la distancia”.